最近、MLCommons が MLPerf 推論 v4.1 の結果を発表しました。複数の AI 推論チップ メーカーが参加し、競争は熾烈を極めました。このコンテストには初めて、AMD、Google、UntetherAI、その他のメーカーのチップと、Nvidia の最新 Blackwell チップが参加します。性能の比較に加えて、エネルギー効率も競争上の重要な要素となっています。さまざまなメーカーが独自のスキルを発揮し、さまざまなベンチマーク テストでそれぞれの利点を実証し、AI 推論チップ市場に新たな活力をもたらしています。
人工知能トレーニングの分野では、Nvidia のグラフィックス カードはほぼ無敵ですが、AI 推論に関しては、特にエネルギー効率の点で競合他社が追いつき始めているようです。 Nvidiaの最新Blackwellチップの好調なパフォーマンスにもかかわらず、首位を維持できるかどうかは不透明だ。本日、ML Commons は最新の AI 推論コンテスト、MLPerf Inference v4.1 の結果を発表しました。今回初めて、AMDのInstinctアクセラレータ、GoogleのTrilliumアクセラレータ、カナダのスタートアップUntetherAIのチップ、NvidiaのBlackwellチップが参加する。他の 2 社、Cerebras と FuriosaAI は新しい推論チップを発売しましたが、テストのために MLPerf を提出していません。
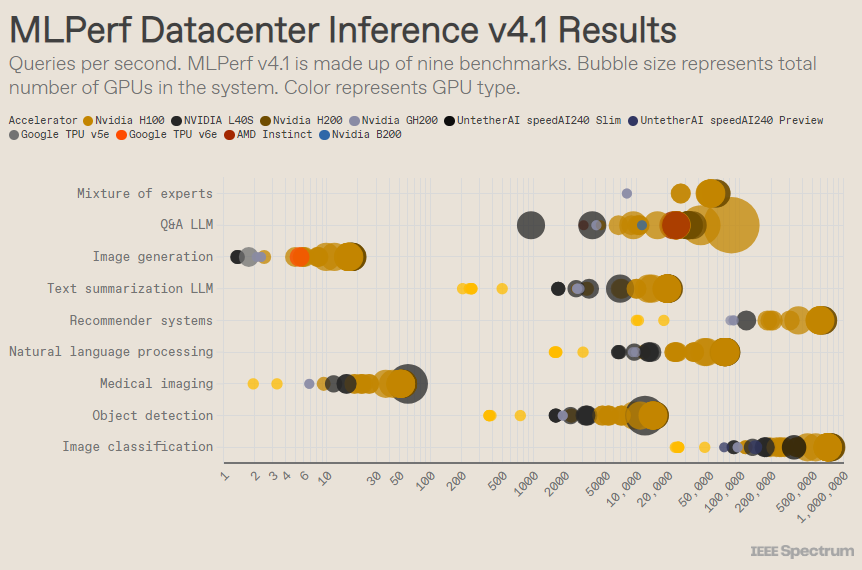
MLPerf はオリンピック競技会のように構成されており、複数のイベントとサブイベントがあります。最も多くのエントリーがあったのは「データセンター エンクロージャ」カテゴリです。オープン カテゴリとは異なり、クローズド カテゴリでは、参加者はソフトウェアを大幅に変更することなく、特定のモデルに対して直接推論を実行する必要があります。データセンター カテゴリでは主にリクエストをバッチ処理する機能をテストしますが、エッジ カテゴリでは遅延の削減に焦点を当てます。
各カテゴリには 9 つの異なるベンチマークがあり、人気のある画像生成 (Midjourney など) や大規模な言語モデルによる質問応答 (ChatGPT など) などのさまざまな AI タスクに加え、重要だがあまり知られていないタスクもカバーしています。画像分類、オブジェクト検出、推奨エンジン。
このラウンドでは、「エキスパート ハイブリッド モデル」という新しいベンチマークが追加されます。これは、言語モデルを展開する方法としてますます人気が高まっています。言語モデルを複数の独立した小さなモデルに分割し、それぞれが日常会話、数学的問題の解決、プログラミング支援などの特定のタスクに合わせて微調整されます。 AMDの上級技術スタッフ、ミロスラフ・ホダック氏は、各クエリを対応する小規模モデルに割り当てることで、リソース使用率が削減され、コストが削減され、スループットが向上すると述べた。

人気のある「クローズド データ センター」ベンチマークでは、GPU と CPU を 1 つのパッケージにまとめた Nvidia H200 GPU および GH200 スーパーチップをベースにしたベンチマークが依然として優勝しています。ただし、結果を詳しく見てみると、いくつかの興味深い詳細が明らかになります。複数のアクセラレータを使用する競合他社もあれば、1 つだけを使用する競合他社もありました。 1 秒あたりのクエリをアクセラレータの数で正規化し、アクセラレータの種類ごとに最もパフォーマンスの高い送信を保持すると、結果はさらに混乱します。このアプローチでは、CPU とインターコネクトの役割が無視されることに注意してください。
アクセラレータごとのベースでは、Nvidia の Blackwell は大規模な言語モデルの質疑応答タスクで優れており、以前のチップ イテレーションと比較して 2.5 倍の高速化を実現しました。これは、同社が提出した唯一のベンチマークです。 Untether AI の SpeedAI240 プレビュー チップは、提出された唯一の画像認識タスクにおいて H200 とほぼ同等のパフォーマンスを発揮しました。 Google の Trillium は、画像生成タスクでは H100 および H200 よりわずかに低いパフォーマンスを示しますが、AMD の Instinct は、大規模な言語モデルの質問と回答のタスクでは H100 と同等のパフォーマンスを示します。
Blackwell の成功の一部は、4 ビット浮動小数点精度を使用して大規模な言語モデルを実行できる能力にあります。 Nvidia と競合他社は、計算を高速化するために、ChatGPT などの変換モデルで表現されるビット数を減らすことに取り組んできました。 Nvidia は H100 で 8 ビット演算を導入しており、この提出は MLPerf ベンチマークにおける 4 ビット演算の最初のデモンストレーションです。
Nvidia の製品マーケティング担当ディレクターである Dave Salvator 氏は、このような低精度の数値を扱う際の最大の課題は、精度を維持することだと述べています。 MLPerf 提出の高い精度を維持するために、Nvidia チームはソフトウェアに多くの革新を加えました。
さらに、Blackwell のメモリ帯域幅は、H200 の 4.8 テラバイトと比較して、ほぼ 2 倍の 8 テラバイト/秒となっています。
NvidiaのBlackwell提案ではシングルチップが使用されているが、サルバトール氏によると、これはネットワーキングとスケーリング向けに設計されており、NvidiaのNVLinkインターコネクトと組み合わせることで最高のパフォーマンスを発揮するという。 Blackwell GPU は、1 秒あたり最大 18 の NVLink 100 GB 接続をサポートし、合計帯域幅は 1.8 テラバイト/秒で、これは H100 の相互接続帯域幅のほぼ 2 倍です。
Salvator 氏は、大規模な言語モデルがスケールし続けるにつれて、推論でも需要を満たすためにマルチ GPU プラットフォームが必要になると考えており、Blackwell はこの状況向けに設計されています。 「Havel はプラットフォームです」と Salvator 氏は言います。
Nvidia は、Blackwell チップ システムをプレビュー サブカテゴリに提出しました。これは、まだ利用可能ではありませんが、約 6 か月後の次の MLPerf リリースまでに利用可能になる予定であることを意味します。
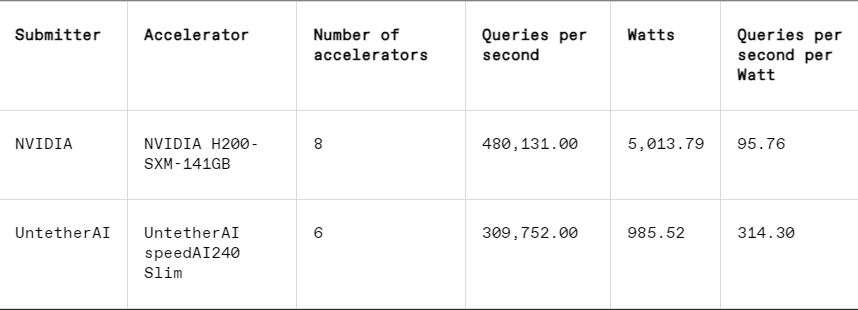
各ベンチマークでは、MLPerf には、タスクの実行中に各システムの実際の電力消費を系統的にテストするエネルギー測定セクションも含まれています。このラウンドのメインコンペティション (データセンター密閉型エネルギー部門) には、Nvidia と Untether AI の 2 社のみが参加しました。 Nvidia はすべてのベンチマークに参加しましたが、Untether は画像認識タスクの結果のみを提出しました。
Untether AI はこの点で優れており、優れたエネルギー効率を実現することに成功しています。同社のチップは「インメモリコンピューティング」と呼ばれるアプローチを採用している。 Untether AI のチップは、メモリ セルのバンクとその近くに配置された小型プロセッサで構成されています。各プロセッサは並行して動作し、隣接するメモリ ユニットと同時にデータを処理するため、メモリとコンピューティング コアの間でモデル データを転送するのにかかる時間とエネルギーが大幅に削減されます。
「AI ワークロードを実行する際、エネルギー消費の 90% が DRAM からキャッシュ処理ユニットへのデータの移動であることがわかりました」と Untether AI の製品担当副社長、ロバート ビーチラー氏は述べています。 「したがって、Untether が行うことは、データをコンピューティング ユニットに移動するのではなく、コンピューティングをデータに近づけることです。」
このアプローチは、MLPerf の別のサブカテゴリであるエッジ クロージャで特にうまく機能します。このカテゴリは、工場での機械検査、誘導ビジョンロボット、自動運転車など、より実用的なユースケースに焦点を当てており、これらのアプリケーションにはエネルギー効率と高速処理に対する厳しい要件があるとビーチラー氏は説明した。
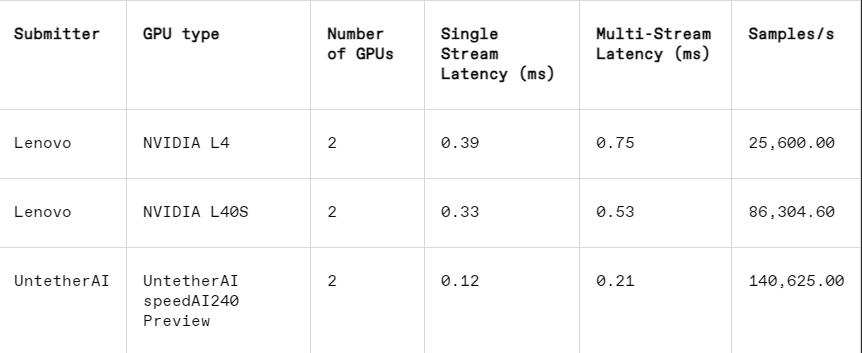
画像認識タスクでは、Untether AI の SpeedAI240 プレビュー チップのレイテンシ性能は Nvidia の L40S よりも 2.8 倍高速で、スループット (1 秒あたりのサンプル数) も 1.6 倍増加します。同社はこのカテゴリの消費電力結果も提出したが、Nvidiaの競合他社は提出していないため、直接比較するのは困難だった。ただし、Untether AI の SpeedAI240 プレビュー チップの公称消費電力は 150 ワットですが、Nvidia の L40S は 350 ワットであり、消費電力において 2.3 倍の利点があり、遅延パフォーマンスが向上しています。
Cerebras と Furiosa は MLPerf には参加していませんが、それぞれ新しいチップもリリースしました。 Cerebras は、スタンフォード大学で開催された IEEE Hot Chips カンファレンスで推論サービスを発表しました。カリフォルニア州サニーバレーに拠点を置く Cerebras は、シリコン ウェーハが許す限りの大きさの巨大チップを製造しているため、チップ間の相互接続が回避され、デバイスのメモリ帯域幅が大幅に増加します。これらは主に巨大なニューラル ネットワークのトレーニングに使用されています。現在、彼らは推論をサポートするために最新のコンピューター CS3 をアップグレードしました。
Cerebras は MLPerf を提出していませんが、同社のプラットフォームは 1 秒あたりに生成される LLM トークンの数で H100 を 7 倍、競合する Groq チップを 2 倍上回っていると主張しています。 「今日、私たちは生成型 AI のダイヤルアップ時代に入っています」とセレブラスの CEO 兼共同創設者であるアンドリュー フェルドマンは述べています。 「これはすべて、メモリ帯域幅のボトルネックがあるためです。Nvidia の H100 であれ、AMD の MI300 や TPU であれ、それらはすべて同じ外部メモリを使用するため、結果として同じ制限が生じます。当社はウェハ レベルの設計でその障壁を打ち破ります。 」
Hot Chips カンファレンスでは、ソウルの Furiosa も第 2 世代チップ RNGD (「反逆者」と発音) をデモしました。 Furiosa の新しいチップは、Tensor Contraction Processor (TCP) アーキテクチャを特徴としています。 AI ワークロードでは、基本的な数学関数は行列の乗算であり、多くの場合、プリミティブとしてハードウェアに実装されます。ただし、行列のサイズと形状、つまりより広いテンソルは大幅に変化する可能性があります。 RNGD は、このより一般的なテンソル乗算をプリミティブとして実装します。 「推論中、バッチ サイズは大きく変化するため、特定のテンソル形状に固有の並列処理とデータの再利用を最大限に活用することが重要です」と Furiosa の創設者兼 CEO の June Paik 氏は Hot Chips で述べました。
Furiosa には MLPerf がありませんが、社内テストで RNGD チップを MLPerf の LLM サマリー ベンチマークと比較したところ、結果は Nvidia の L40S チップと同等でしたが、消費電力は L40S の 320 ワットと比較して 185 ワットのみでした。 Paik氏は、ソフトウェアをさらに最適化することでパフォーマンスが向上すると述べた。
IBMはまた、企業がAIワークロードを生成できるように設計された新しいSpyreチップの発売も発表し、2025年の第1四半期に発売される予定だ。
AI推論チップ市場が近い将来に活況を呈することは明らかです。
参考: https://spectrum.ieee.org/new-inference-chips
全体として、MLPerf v4.1 の結果は、AI 推論チップ市場の競争がますます激化していることを示しています。Nvidia が依然としてリードを維持していますが、AMD、Google、Untether AI などのメーカーの台頭は無視できません。将来的には、エネルギー効率が重要な競争要因となり、インメモリ コンピューティングなどの新しいテクノロジーも重要な役割を果たすでしょう。 さまざまなメーカーの技術革新は今後も AI 推論能力の向上を促進し、AI アプリケーションの普及と開発に大きな推進力を与えるでしょう。