ModelScope コミュニティは、国内のオープンソース Sora ビデオ生成モデル CogVideoX - CogVideoX-5B のアップグレード バージョンをオープンソース化しました。これは、大規模な DiT モデルに基づくテキストからビデオへの生成モデルです。従来の CogVideoX-2B と比較して、新モデルではビデオ品質と視覚効果が大幅に向上しました。 CogVideoX-5B は、3D 因果変分オートエンコーダー (3D 因果変分オートエンコーダー) とエキスパート Transformer テクノロジーを利用し、位置エンコーディングおよび時空間関節モデリングのための 3D フル アテンション メカニズムとして 3D-RoPE を使用します。また、より長いトレーニング テクノロジーを生成することもできます。 、より高品質で、より動きのあるビデオ。
以前の CogVideoX-2B と比較して、新しいモデルはビデオ生成の品質と視覚効果を大幅に向上させました。
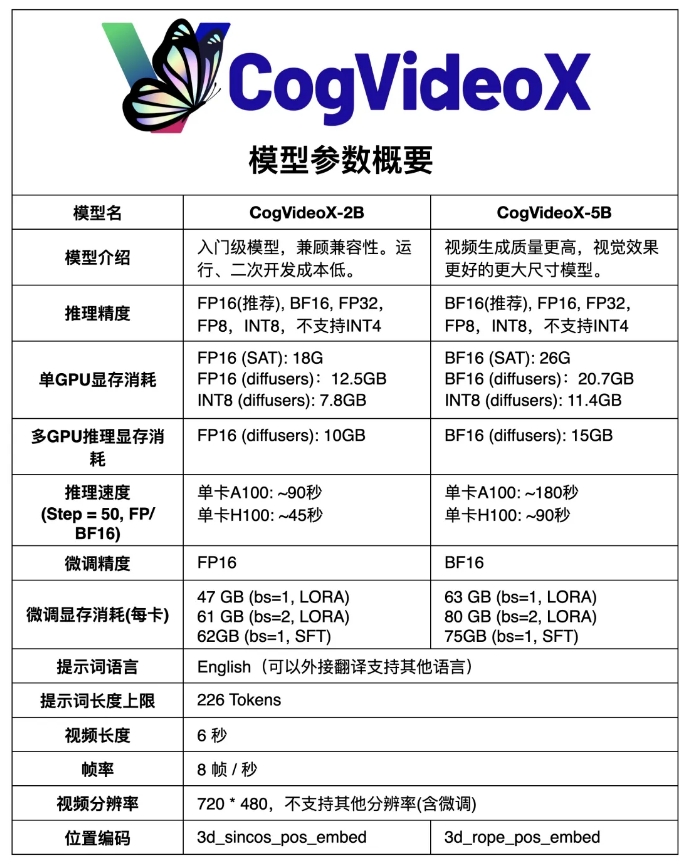
CogVideoX-5B は、テキストからビデオへの生成タスク用に特別に設計された大規模 DiT (拡散トランス) モデルに基づいています。このモデルは、3D 因果変分オートエンコーダー (3D 因果変分オートエンコーダー) とエキスパート Transformer テクノロジーを採用し、テキストとビデオの埋め込みを組み合わせ、位置エンコーディングとして 3D-RoPE を使用し、時空間関節モデリングに 3D フル アテンション メカニズムを利用します。
さらに、このモデルはプログレッシブ トレーニング テクノロジーを採用しており、重要なモーション機能を備えた一貫性のある長時間の高品質ビデオを生成できます。
モデルリンク:
https://modelscope.cn/models/ZhipuAI/CogVideoX-5b
CogVideoX-5B のオープンソースは、国内の AI ビデオ生成分野に新たな技術的ブレークスルーと開発の機会をもたらし、研究者と開発者に強力なツールとリソースも提供しました。将来的には、CogVideoX-5B をベースにしたさらに革新的なアプリケーションが登場し、AI ビデオ生成技術の継続的な進歩が促進されると考えられます。モデルに簡単にアクセスできるため、研究や応用の敷居が低くなり、テクノロジーのより広範な普及と応用が促進されます。