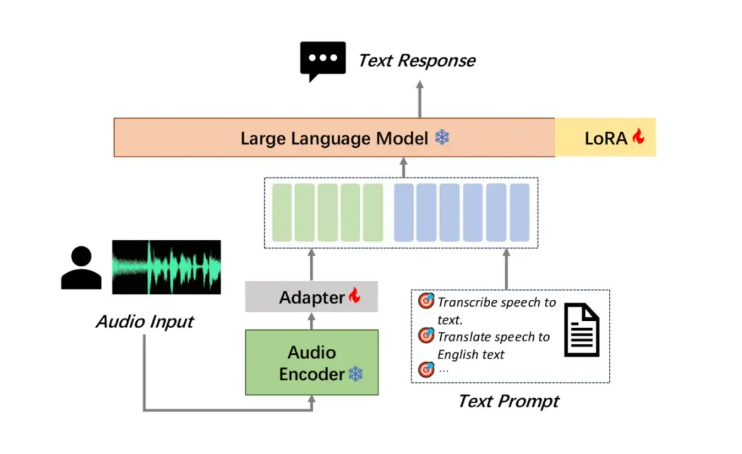
Moore Thread は、大規模な音声理解モデル MooER をオープンソース化しました。これは、国内のフル機能の GPU トレーニングと推論に基づく業界初の大規模なオープンソース音声モデルであり、これはマイルストーンです。 MooER は、中国語と英語の音声認識と中国語と英語の音声翻訳をサポートしており、その革新的な 3 部構成のモデル構造 (エンコーダー、アダプター、デコーダー) により、モデルが効率的に音声を処理し、ダウンストリーム タスクを実行できるようになります。現在、5,000時間のデータに基づいて学習された推論コードとモデルがオープンソース化されており、将来的には80,000時間のデータに基づいて学習された強化されたモデルがオープンソース化され、開発が大幅に促進されます。国内外のオーディオAI技術の進化を目指します。
MooER は、複数の有名なオープンソースの音声理解大規模モデルの比較テストで良好なパフォーマンスを示し、中国語単語誤り率 (CER) は 4.21% と低く、英語単語誤り率 (WER) は 17.98% で、特に中国語の BLEU でした。 -英語翻訳テストセット。スコアは25.2と他のオープンソースモデルをリードします。 80,000 時間のデータに基づいてトレーニングされた MooER-80k モデルはパフォーマンスが向上しており、CER と WER はそれぞれ 3.50% と 12.66% に減少し、大きな可能性を示しています。 Moore Thread によるこの動きは、AI 分野における国内 GPU の強力な強みを証明するだけでなく、世界的なオーディオ AI 技術の開発に新たな活力を注入するものであり、MooER が将来的にさらなるブレークスルーをもたらすことが期待されています。
複数の有名なオープンソースのオーディオ理解大規模モデルとの比較テストでは、MooER-5K は優れたパフォーマンスを発揮しました。中国語テストでは単語誤り率 (CER) が 4.21% に達し、英語テストでは単語誤り率 (WER) が 17.98% で、他の上位モデルと同等かそれ以上でした。 Covost2zh2en の中国語-英語翻訳テスト セットでは、MooER の BLEU スコアが 25.2 と高く、他のオープンソース モデルを大幅に上回り、産業レベルのアプリケーションに匹敵するレベルに達していることは特に注目に値します。
さらに興味深いのは、80,000 時間のデータに基づいてトレーニングされた MooER-80k モデルが、より強力なパフォーマンスを示したことです。中国語のテスト セットの CER はさらに 3.50% に低下し、英語のテスト セットの WER も 12.66 に最適化されました。 %。大きな発展の可能性を示しています。
Moore Thread のオープンソース MooER は、AI 分野における国産 GPU の応用力を実証するだけでなく、世界的なオーディオ AI 技術の開発に新たな活力を注入します。より多くのトレーニング データとコードがオープンソースになるにつれ、業界は MooER が音声認識、翻訳、その他の分野でさらなるブレークスルーをもたらし、オーディオ AI テクノロジーの普及と革新的な応用を促進すると期待しています。
アドレス: https://arxiv.org/pdf/2408.05101
MooER のオープンソースは、国内の GPU が AI 大型モデルの分野で大きな進歩を遂げたことを示しており、国内外の開発者に貴重なリソースとプラットフォームを提供します。 MooER は将来的により多くのアプリケーション シナリオで役割を果たし、オーディオ AI テクノロジーの継続的な革新と開発を促進することが期待されています。