Microsoft は、新しい軽量マルチモーダル AI モデル Phi-3.5-vision を発売しました。これは、Phi-3 ファミリの新しいメンバーであり、テキストと視覚入力を処理するように設計されています。このモデルはリソースに制約のある環境で優れたパフォーマンスを発揮し、128K のコンテキスト長をサポートしているため、商用アプリケーションや研究アプリケーションに最適です。 Phi-3.5-vision は、画像理解、OCR、チャート分析などの機能を統合しており、複数のベンチマーク テストで優れたパフォーマンスを実証しています。そのオープンソースの性質と効率的な設計により、さまざまな AI アプリケーションにとって理想的な選択肢となります。
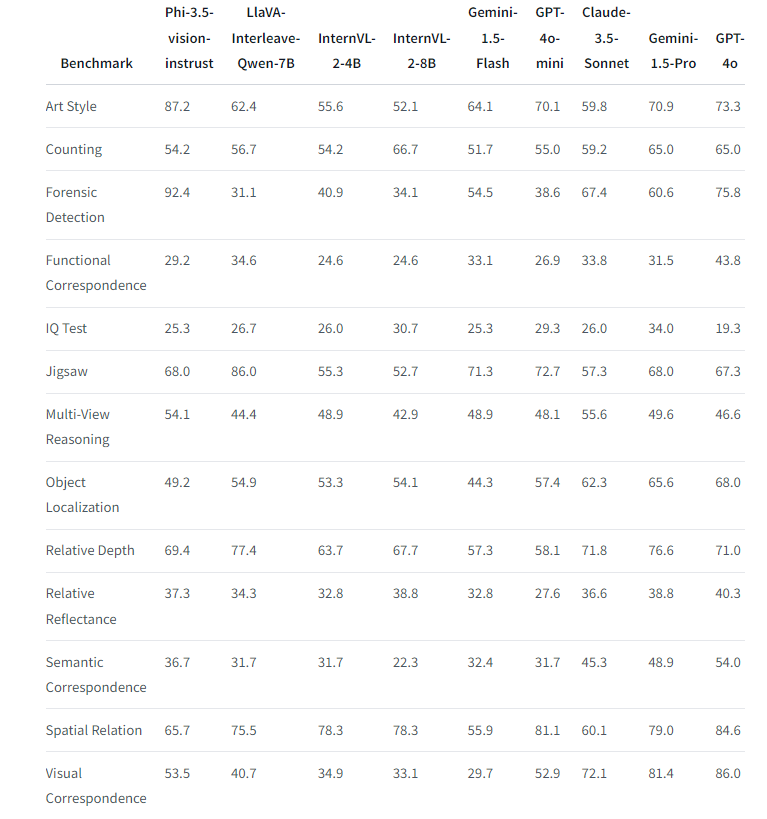
Phi-3.5 ビジョン モデルは、広範な画像理解、光学式文字認識 (OCR)、チャートと表の解析、複数画像またはビデオ クリップの要約などの機能を備えています。このモデルは、画像およびビデオ処理に関連するベンチマークで大幅なパフォーマンスの向上を示しました。
Phi-3.5 ビジョン モデルは、画像エンコーダ、コネクタ、プロジェクター、Phi-3Mini 言語モデルを含む 42 億のパラメータ システムで構成されています。高品質の教育データ、合成データ、厳格に審査された公的文書を使用してトレーニングされており、データの品質とプライバシーが保証されています。
Phi-3.5-vision には 3 つのモデルが含まれています。
Phi-3.5Mini Instruct: メモリやコンピューティング リソースが限られている環境に適した軽量 AI モデル。
Phi-3.5MoE (専門家混合): Microsoft の最初の「専門家混合」モデル。複雑なタスクの処理に優れています。
Phi-3.5Vision Instruct: テキストと画像の処理機能を統合したマルチモーダル モデル。
主な特長
Phi-3.5 ビジョン モデルの主な機能には、画像の理解、OCR、チャートと表の理解、複数の画像の比較、複数の画像またはビデオ クリップの要約、効率的な推論機能、低遅延とメモリの最適化が含まれます。
Phi-3.5-vision は、MMMU、MMBench、TextVQA、ビデオ処理能力テスト、BLINK ベンチマーク テストなどの複数のベンチマーク テストで良好なパフォーマンスを示し、マルチモーダルおよびビジュアル タスクにおける強力なパフォーマンスを実証しました。
Microsoft の Phi-3.5 ビジョン モデルのリリースは、特にデバイス側の操作と複雑な視覚的推論の点で、AI 分野に新しいオプションをもたらします。オープンソース機能と最適化された設計により、リソースに制約のある環境でも適切なパフォーマンスを発揮し、さまざまな AI 駆動型アプリケーションを強力にサポートします。
モデルのダウンロード アドレス: https://huggingface.co/microsoft/Phi-3.5-vision-instruct
全体として、Phi-3.5-vision は、軽量、マルチモーダル、高性能の特性を備えた AI 開発者と研究者に強力なツールを提供し、より多くの分野での AI の応用を促進します。そのオープンソースの性質により、AI テクノロジーの共有と開発も促進されます。