近年、大規模な言語モデル(LLM)のパフォーマンスが注目を集めています。この記事では、エキサイティングな研究を紹介します。この研究では、検索戦略を巧みに使用して、小型LLMのパフォーマンスを大幅に向上させ、特定のタスクで大規模なモデルに匹敵させます。この研究は、伝統的な「より大きなモデルとより良い」という概念に挑戦し、LLMの将来の開発のための新しいアイデアと方向性を提供し、リソースが限られている研究者と開発者により多くの可能性を提供します。これは、コンピューティングリソースとモデルパラメーターとの関係について、モデルの推論能力とトリガーを改善する際の検索戦略の大きな可能性を明らかにしています。
最近、新しい研究は刺激的であり、大規模な言語モデル(LLM)が検索機能を通じてパフォーマンスを大幅に改善できることを証明しています。特に、パラメーターボリュームが8億個のパラメーターを持つLLAMA3.1モデルは、100個の検索を通過しましたが、PythonコードのGPT-4Oに匹敵しませんでした。
このアイデアは、2019年のリッチサットンの古典的なブログ投稿「The Bitter Lesson」であるLish Suttonの古典的なブログ投稿を人々に思い出させているようです。彼は、コンピューティングパワーの改善により、一般的な方法の力を認識する必要があると述べました。特に、「検索」と「学習」の2つの方法は、拡大し続けることができる優れた選択のようです。
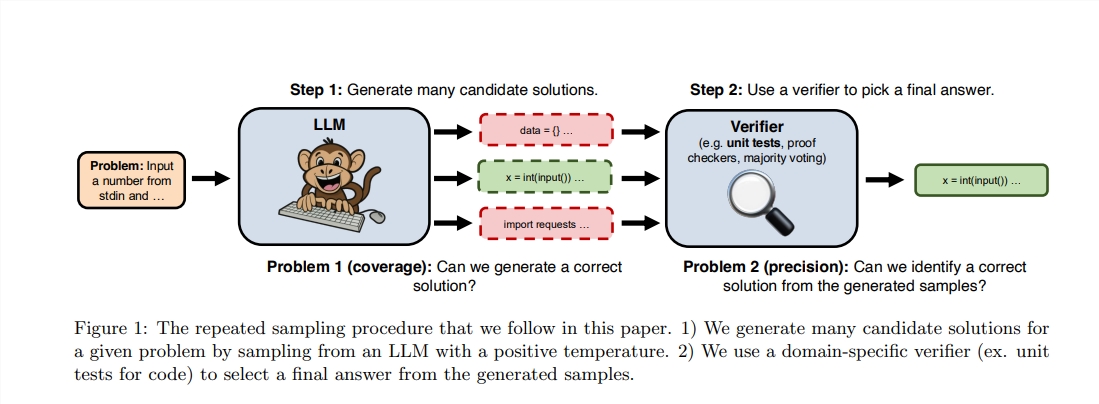
サットンは学習の重要性を強調していますが、つまり、より大きなモデルは通常、より多くの知識を学ぶことができますが、推論のプロセスにおける検索の可能性を無視することがよくあります。最近、スタンフォード、オックスフォード、ディープマインドの研究者は、推論段階で繰り返しサンプリング時間の数を増やすと、数学、推論、コード生成の分野でのモデルのパフォーマンスが大幅に向上する可能性があることを発見しました。
これらの研究に触発された後、2人のエンジニアは実験を行うことを決定しました。彼らは、検索に100の小さなLlamaモデルを使用すると、PythonプログラミングタスクでGPT-4oを上回り、さらにはGPT-4oを結び付けることさえあることがわかりました。彼らは鮮やかなメタファーを使用して次のように説明しています。「過去には、マレーシアのマレーシアはある程度の能力を達成できました。今では、同じものを完成させることができるのは100個だけです。」
より高いパフォーマンスを達成するために、彼らはVLLMライブラリを使用してバッチ推論を実施し、10 A100-40GB GPUで実行しました。著者は、より客観的で正確なテスト評価によって生成されたコードを実行できるため、Humanvalのベンチマークテストを選択しました。
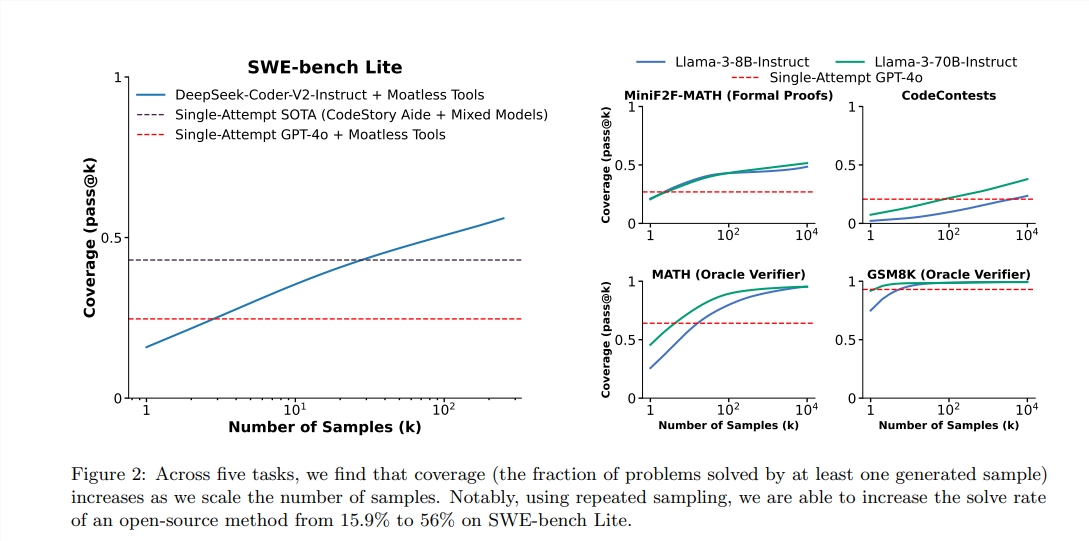
レポートによると、GPT-4Oのパス@1スコアは、ゼロサンプル推論で90.2%です。上記の方法により、Llama3.18bのPass@Kスコアも大幅に改善されています。繰り返しサンプリングの数が100の場合、ラマのスコアは90.5%に達しました。
この実験は元の研究の厳密な複製ではありませんが、検索方法が推論段階を強化すると、小さいモデルが予見可能な範囲内の大きなモデルの可能性を上回ることができることを強調していることに言及する価値があります。
検索は、計算とリソースの増加がメモリから計算へと転送され、リソースのバランスを達成するにつれて「透過的に」拡大できるため、強力です。最近、DeepMindは数学の分野で重要な進歩を遂げ、検索の力を証明しています。
ただし、検索の成功は、最初に結果の高品質の評価を実施する必要があります。 DeepMindモデルは、自然言語の数学的問題を変換して正式な表現を形成することにより、効果的な監督を達成しました。他の領域では、「要約メール」などのオープンNLPタスクを効果的に検索するのははるかに困難です。
この研究は、特定の分野での生成モデルのパフォーマンスの向上がその評価と検索機能に関連していることを示しており、将来の研究では、繰り返しのデジタル環境を通じてこれらの機能を改善する方法を探ることができます。
論文アドレス:https://arxiv.org/pdf/2407.21787
全体として、この研究は、より大きなモデルパラメーターを追求するのではなく、大規模な言語モデルのパフォーマンス改善のための新しい視点を提供します。 将来、学習戦略と検索戦略を効果的に組み合わせる方法は、LLM開発にとって重要な方向になります。 この研究のリンクされたリンクされたリンクも提供されており、興味のある読者はそれをさらに理解することができます。