Tencent Youtu Lab およびその他の機関は、ビデオ、画像、テキスト、オーディオを同時に処理し、スムーズなインタラクティブなエクスペリエンスを提供できる初のマルチモーダル大規模言語モデル VITA をオープンソース化しました。 VITA の登場は、中国語の方言処理における既存の大規模言語モデルの欠点を補うことを目的としており、Mixtral8×7B モデルに基づいて中国語の語彙が拡張され、バイリンガル命令が微調整され、英語に堪能になります。そして中国語が堪能。これは、マルチモーダルな理解と対話において、オープンソース コミュニティにとって大きな進歩を示しています。
最近、Tencent Youtu Lab などの研究者らは、ビデオ、画像、テキスト、オーディオを同時に処理できる初のオープンソース マルチモーダル大規模言語モデル VITA を発表しました。そのインタラクティブなエクスペリエンスも一流です。
VITA モデルは、中国語の方言を処理する際の大規模な言語モデルの欠点を埋めるために生まれました。これは、強力な Mixtral8×7B モデル、拡張された中国語語彙、および微調整されたバイリンガル命令に基づいており、VITA は英語だけでなく中国語も流暢に話せるようになります。
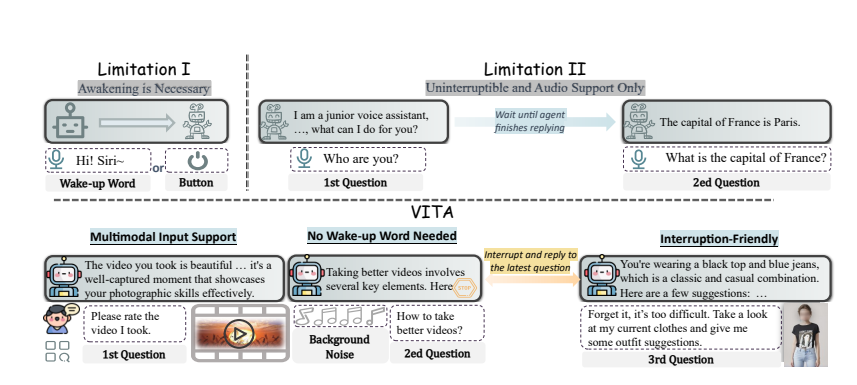
主な特徴:
マルチモーダルの理解: ビデオ、画像、テキスト、オーディオを処理する VITA の能力は、オープンソース モデルの中で前例のないものです。
自然な対話: 毎回「ねえ、VITA」と言う必要はなく、話しかければいつでも反応し、他の人と話しているときでも、礼儀正しく、勝手に中断することはありません。
オープンソース パイオニア: VITA は、オープンソース コミュニティにとってマルチモーダルな理解と対話における重要なステップであり、その後の研究の基礎を築きます。
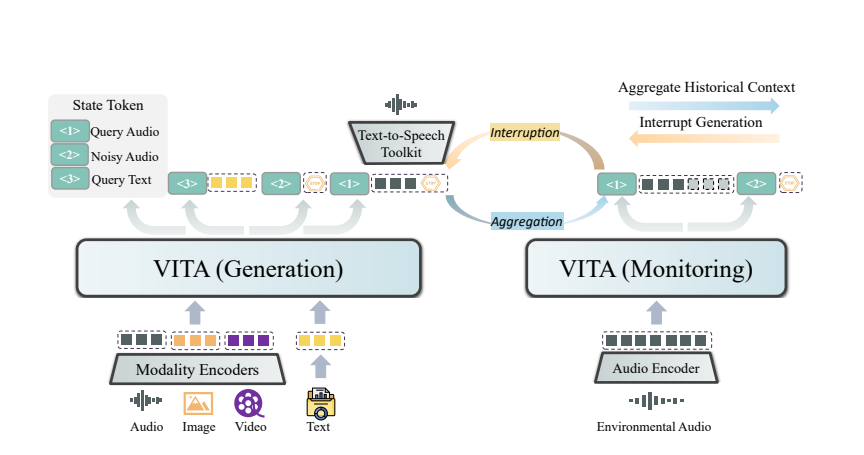
VITA の魅力は、デュアル モデル展開にあります。 1 つのモデルはユーザーのクエリに対する応答を生成する責任を負い、もう 1 つのモデルは環境入力を継続的に追跡して、すべてのインタラクションが正確かつタイムリーであることを保証します。
VITAはチャットだけでなく、運動するときのチャットパートナーとして機能したり、旅行中にアドバイスを提供したりすることもできます。また、提供された写真やビデオコンテンツに基づいて質問に回答することもでき、その強力な実用性を示しています。
VITA は大きな可能性を示していますが、感情的な音声合成とマルチモーダル サポートの点ではまだ進化の途上にあります。研究者らは、次世代の VITA がビデオとテキスト入力から高品質のオーディオを生成できるようにすることを計画しており、高品質のオーディオとビデオを同時に生成する可能性も検討します。
VITA モデルのオープンソースは、技術的な勝利であるだけでなく、インテリジェントなインタラクションの方法における大きな革新でもあります。研究が深まるにつれ、VITA がよりスマートで人間味のあるインタラクティブ エクスペリエンスをもたらしてくれると信じる理由ができました。
論文アドレス: https://arxiv.org/pdf/2408.05211
VITA のオープンソースは、マルチモーダル大規模言語モデルの開発に新たな方向性をもたらし、その強力な機能と便利なインタラクティブなエクスペリエンスは、将来的には人間とコンピューターの対話がよりインテリジェントで人間味のあるものになることを示しています。 VITAが今後さらに飛躍し、人々の生活にさらなる利便性をもたらすことを期待しています。