Transformer アーキテクチャの台頭は自然言語処理の分野に革命をもたらしましたが、その高い計算コストが長いテキストを処理する際のボトルネックになっています。この問題に対応して、この記事では、ツリー アテンションと呼ばれる新しい方法を紹介します。これは、ツリー削減を通じて長いコンテキストの Transformer モデルのセルフ アテンションの計算の複雑さを効果的に軽減し、最新の GPU クラスターの能力を最大限に活用します。コンピューティング効率が大幅に向上します。
この情報爆発の時代において、人工知能は明るい星のようなもので、人類の知恵の夜空を照らします。これらのスターの中で、自己注意メカニズムを核とする Transformer アーキテクチャは間違いなく最も輝かしいものであり、自然言語処理の新時代をリードします。しかし、最も明るい星であっても、到達するのが困難な角があります。ロングコンテキストの Transformer モデルの場合、セルフアテンション計算による高いリソース消費が問題になります。数万語の長さの記事を AI に理解させようとすると、各単語を記事内の他のすべての単語と比較する必要があり、その計算量は間違いなく膨大になります。
この問題を解決するために、Zyphra と EleutherAI の科学者グループは、Tree Attendant と呼ばれる新しい方法を提案しました。
Transformer モデルの中核であることに注意してください。その計算の複雑さは、シーケンスの長さが増加するにつれて二次関数的に増加します。これは、長いテキストを扱う場合、特に大規模言語モデル (LLM) の場合、克服できない障害になります。
Tree Attendance の誕生は、この計算の森に効率的な計算を実行できる木を植えるようなものです。これは、自己注意の計算をツリー削減を通じて複数の並列タスクに分解します。各タスクはツリーの葉のようなもので、それらが集まって完全なツリーを形成します。
さらに驚くべきことは、ツリー・アテンションの提案者らは、自己注意のエネルギー関数も導出したことです。これは、自己注意のベイズ的説明を提供するだけでなく、それをホップフィールド・ネットワーク・スタンド・アップなどのエネルギー・モデルと密接に結び付けています。
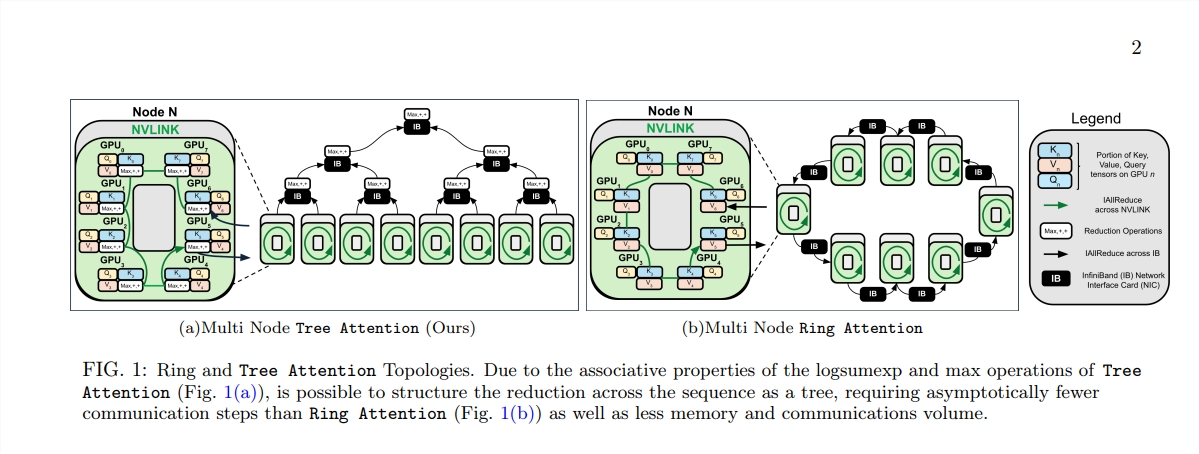
Tree Attention は、最新の GPU クラスターのネットワーク トポロジーも特別に考慮しており、クラスター内の高帯域幅接続をインテリジェントに利用することでクロスノード通信要件を軽減し、それによってコンピューティング効率を向上させます。
科学者らは一連の実験を通じて、さまざまなシーケンス長と GPU の数の下での Tree Attend のパフォーマンスを検証しました。結果は、通信量とピーク時のメモリ使用量を大幅に削減しながら、複数の GPU でデコードする場合、ツリー アテンションは既存のリング アテンション方式よりも最大 8 倍高速であることを示しています。
Tree Attendant の提案は、ロングコンテキスト アテンション モデルの計算に効率的なソリューションを提供するだけでなく、Transformer モデルの内部メカニズムを理解するための新しい視点も提供します。 AI テクノロジーが進歩し続けるにつれて、Tree Attend が将来の AI 研究と応用において重要な役割を果たすと信じる理由があります。
論文アドレス: https://mp.weixin.qq.com/s/U9FaE6d-HJGsUs7u9EKKuQ
Tree Attendant の出現は、長いテキスト処理の計算ボトルネックを解決するための効率的かつ革新的なソリューションを提供します。これは、Transformer モデルの理解と将来の開発にとって広範な重要性を持ちます。この方法は、パフォーマンスの大幅な向上を達成するだけでなく、さらに重要なことに、その後の研究に新しいアイデアと方向性を提供し、詳細な研究と議論に値します。