アリババは、音声認識、翻訳、音声分析を大幅に向上させた新しいオープンソース音声モデル Qwen2-Audio を発表し、その機能とパフォーマンスは前世代製品 Qwen-Audio を上回り、複数の OpenAI の Whisper- テストでもそれを上回りました。大-v3。 Qwen2-Audio は複数の言語をサポートしており、基本バージョンと指示付きの詳細バージョンが提供されており、ユーザーは音声で質問し、話者の年齢や感情の判断、さまざまな音の分析などの音声コンテンツの認識と分析を実行できます。オーディオのコンポーネント。このモデルでは、事前トレーニングにより自然な言語プロンプトが使用され、理解力と応答能力が大幅に向上し、ボイス チャットと音声分析の 2 つのモードが導入されて、ユーザー インタラクションの自然さが強化されています。
最近、Alibaba は、Qwen-Audio をベースにした新しいオープンソース音声モデル Qwen2-Audio を発表しました。このモデルは、音声認識、翻訳、音声分析において優れたパフォーマンスを発揮するだけでなく、機能とパフォーマンスの大幅な向上も実現しています。 Qwen2-Audio は、基本バージョンと微調整バージョンの指示を提供し、ユーザーは音声でオーディオ モデルに質問し、内容を認識して分析できます。
たとえば、ユーザーが女性に話すように依頼すると、Qwen2-Audio が女性の年齢を特定したり、騒々しい音が入力された場合に彼女の感情を分析したりできます。また、モデルはさまざまな音の成分を分析できます。 Qwen2-Audio は中国語、広東語、フランス語、英語、日本語を含む複数の言語をサポートしており、感情分析および翻訳アプリケーションの開発に非常に便利です。
製品入口: https://top.aibase.com/tool/qwen2-audio
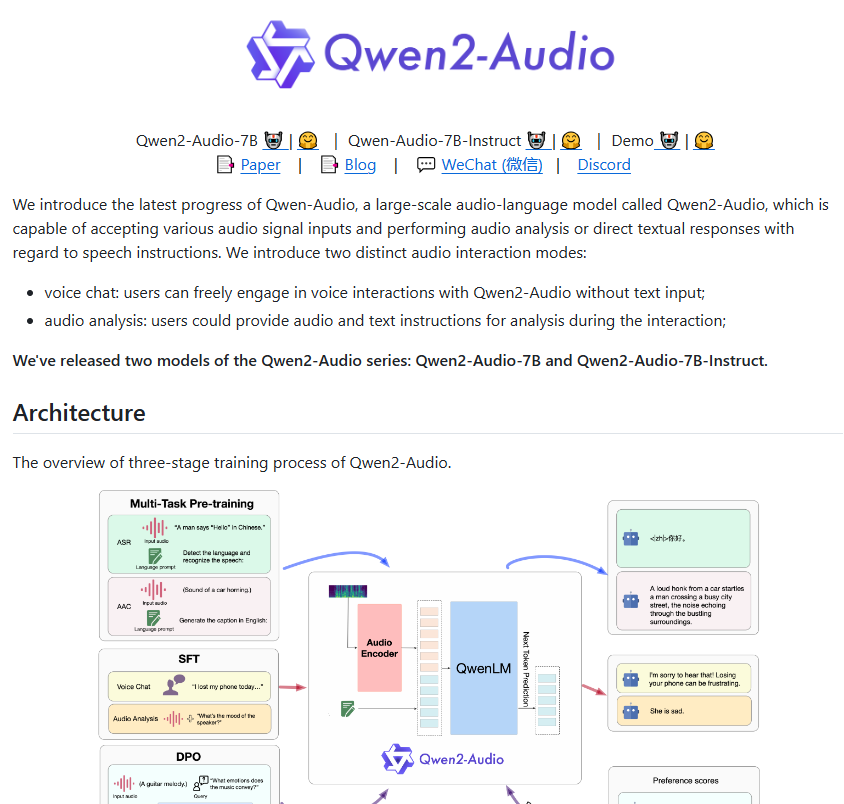
第一世代の Qwen-Audio と比較して、Qwen2-Audio はアーキテクチャとパフォーマンスが完全に最適化されています。トレーニング前の段階では、この新しいモデルはより自然言語の手がかりを使用して、以前の複雑な階層ラベルを置き換えます。この改善により、モデルが理解しやすくなり、さまざまなタスクに対応できるようになり、汎化能力も大幅に向上しました。
Qwen2-Audio のコマンド追従能力も大幅に向上し、ユーザーのコマンドをより正確に理解できるようになりました。たとえば、ユーザーが「この音声の感情傾向を分析して」というコマンドを発行すると、Qwen2-Audio は音声に含まれる感情を正確に判断できます。さらに、このモデルにはボイスチャットとオーディオ分析という 2 つのモードが導入されており、ユーザーの音声対話がより自然になります。オーディオ分析モードでは、Qwen2-Audio はさまざまな種類のオーディオを深く分析し、詳細かつ正確な分析結果を提供します。
モデルの出力が人間の期待に確実に応えられるようにするために、Qwen2-Audio では、教師付き微調整や直接的な好みの最適化などの高度なテクノロジーも導入しています。人間と対話するとき、モデルはより自然かつ正確に表示されます。
パフォーマンス テストの点では、Qwen2-Audio は複数の主流ベンチマーク テストで良好なパフォーマンスを示し、特に音声認識と翻訳の精度で OpenAI の Whisper-large-v3 を上回りました。この新モデルの性能は業界で広く注目を集めただけでなく、音声テクノロジーの新たな未来を告げるものでもありました。
ハイライト:
Qwen2-Audio は Alibaba の最新のオープンソース音声モデルで、複数の言語をサポートし、強力な認識機能と分析機能を備えています。
前世代と比較して、Qwen2-Audio はパフォーマンスとアーキテクチャが大幅に最適化されており、理解して応答する能力が向上しています。
? 複数のパフォーマンス テストにおいて、Qwen2-Audio は OpenAI の Whisper を上回り、強力な競争力を示しました。
Qwen2-Audio のオープンソースは音声技術分野の発展を促進し、開発者に強力なツールを提供し、より革新的なアプリケーションの誕生を促進します。多言語サポートとパフォーマンスにおける利点により、将来の音声技術開発の重要な方向性となります。より多くのシナリオで Qwen2-Audio が適用されることを楽しみにしています。