AI 分野の権威である Andrej Karpathy 氏は最近、人間のフィードバックに基づく強化学習 (RLHF) に疑問を呈し、それが真の人間レベルの AI を実現する唯一の方法ではないと考えており、これが業界内で広範な懸念と激しい議論を引き起こしています。 。彼は、RLHF は究極の解決策というよりも、その場しのぎの手段であると信じており、AlphaGo を例として、実際の強化学習と RLHF の問題解決における違いを比較しました。 Karpathy 氏の見解は間違いなく、現在の AI 研究の方向性に新たな視点を提供し、将来の AI 開発に新たな課題をもたらします。
最近、AI 業界の著名な研究者である Andrej Karpathy 氏は、現在広く賞賛されているヒューマン フィードバック (RLHF) テクノロジーに基づく強化学習が、それを実現する唯一の方法ではない可能性があると考えています。真の人間レベルの問題解決能力。この声明は間違いなく現在のAI研究分野に重爆弾を投下した。
RLHF はかつて、ChatGPT などの大規模言語モデル (LLM) の成功の重要な要素とみなされ、AI の理解、従順、自然な対話能力を与える秘密兵器として賞賛されました。従来の AI トレーニング プロセスでは、通常、RLHF は事前トレーニングと教師あり微調整 (SFT) 後の最後のリンクとして使用されます。しかし、カルパシー氏は、RLHF をボトルネックや一時しのぎの手段と例え、AI 進化の究極の解決策には程遠いと考えました。
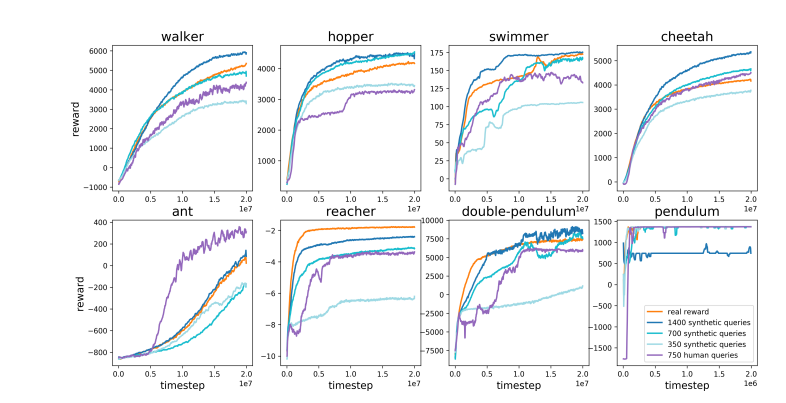
Karpathy 氏は、RLHF を DeepMind の AlphaGo と巧みに比較しました。 AlphaGo は、彼が真の RL (強化学習) テクノロジーと呼ぶものを使用し、常に自分自身と対戦して勝率を最大化することで、最終的には人間の介入なしで人間のトップ チェス プレイヤーを超えました。このアプローチは、ゲームの結果から直接学習するようにニューラル ネットワークを最適化することで、超人的なパフォーマンス レベルを達成します。
対照的に、カルパシー氏は、RLHF は実際に問題を解決するというよりも、人間の好みを模倣することにあると考えています。同氏は、AlphaGo が RLHF 手法を採用した場合、人間の評価者は多数のゲーム状態を比較して好みを選択する必要があり、このプロセスでは人間の雰囲気チェックを模倣した報酬モデルをトレーニングするために最大 100,000 回の比較が必要になる可能性があると想像しました。しかしながら、囲碁のような厳密なゲームでは、このような雰囲気に基づく判断は誤解を招く結果を生む可能性がある。
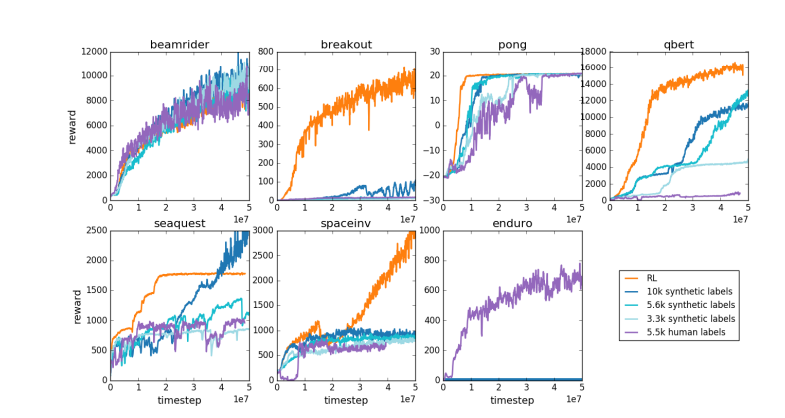
同じ理由で、現在の LLM 報酬モデルも同様に機能します。つまり、人間の評価者が統計的に好むと思われる高い回答をランク付けする傾向があります。これは、真の問題解決能力を反映するものではなく、人間の表面的な好みに応えるエージェントです。さらに心配なのは、モデルが実際に機能を向上させるのではなく、この報酬関数を利用する方法をすぐに学習してしまう可能性があることです。
Karpathy 氏は、強化学習は Go のような閉鎖的な環境ではうまく機能しますが、オープンな言語タスクでは真の強化学習は依然として難しいと指摘しています。これは主に、オープンなタスクでは明確な目標と報酬メカニズムを定義することが難しいためです。記事を要約する、pip のインストールに関する漠然とした質問に答える、ジョークを言う、Java コードを Python に書き直すなどのタスクに対して客観的な報酬を与えるにはどうすればよいでしょうか? Karpathy はこの洞察力に富んだ質問をしていますが、この方向に進むことは原則として不可能です。しかしそれも簡単ではなく、創造的な思考が必要です。

それでもカルパシー氏は、この困難な問題が解決できれば、言語モデルは人間の問題解決能力に真に匹敵する、あるいはそれを超える可能性があると信じています。この見解は、オープン性が汎用人工知能 (AGI) の基礎であると指摘した、Google DeepMind が最近発表した論文と一致します。
今年 OpenAI を去った数人の上級 AI 専門家の 1 人として、Karpathy 氏は現在、自身の教育 AI スタートアップに取り組んでいます。彼の発言は間違いなく、AI 研究分野に新たな思考の次元を注入し、AI 開発の将来の方向性について貴重な洞察を提供しました。
Karpathy 氏の見解は、業界内で広範な議論を引き起こしました。支持者らは、同氏が現在のAI研究における重要な問題、つまり人間の行動を模倣するだけでなく、AIが本当に複雑な問題を解決できるようにするにはどうすればよいかを明らかにしたと信じている。反対派は、RLHFの早期放棄がAI開発の方向性の逸脱につながるのではないかと懸念している。
論文アドレス: https://arxiv.org/pdf/1706.03741
カルパシー氏の見解は、AI の将来の開発方向についての深い議論を引き起こし、RLHF に対する彼の疑念は、真の人工知能を実現するという最終目標に向けて、現在の AI トレーニング方法を再検討し、より効果的な道を模索することを研究者に促しました。