モバイル デバイスとスマート ホームの人気が高まる時代において、大規模言語モデル (LLM) を効率的に実行することが緊急の必要性となっています。ただし、エッジ デバイスの限られたコンピューティング リソースとメモリがボトルネックになります。この記事では、ルックアップ テーブルに基づく手法である T-MAC テクノロジを紹介します。これにより、エッジ デバイス上の低ビット LLM の動作効率が大幅に向上し、スマート デバイスにより強力なインテリジェントな処理機能がもたらされ、より便利で効率的なスマート ユーザーを実現できます。経験。
スマート デバイスがあらゆる場所に存在するこの時代において、私たちは携帯電話、タブレット、さらにはスマート ホーム デバイスに、より強力なインテリジェントな処理機能を持たせることに熱心に取り組んでいます。ただし、これらのエッジ デバイスにはハードウェア リソース、特にメモリとコンピューティング能力が限られているため、大規模言語モデル (LLM) の展開と実行が制限されます。自然言語を理解し、質問に答え、さらには作成できる強力なモデルをこれらのデバイスに装備できたら、私たちの世界がどのように変わるか想像してみてください。
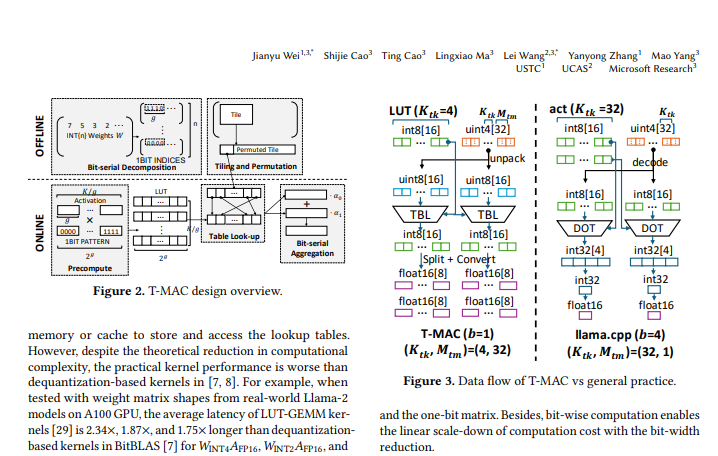
これがT-MACテクノロジー誕生の背景です。 Table-Lookup-based MAC の正式名である T-MAC は、ルックアップ テーブルに基づく方式であり、大規模な低ビット言語モデルを CPU 上で効率的に実行できるため、エッジ デバイス上でインテリジェントなアップグレードを実現できます。
大規模な言語モデルには多くの場合、数十億、さらには数百億のパラメーターが含まれており、それらを保存するには大量のメモリが必要です。これらのモデルをエッジ デバイスに展開するには、モデルの重みを量子化する必要があります。つまり、重みを表すために使用するビットを減らし、それによってモデルのメモリ フットプリントを削減します。ただし、量子化モデルは動作中に混合精度行列乗算 (mpGEMM) を必要としますが、これは既存のハードウェアおよびソフトウェア システムでは一般的ではなく、効率的なサポートが不足しています。
T-MAC の中心となるアイデアは、従来のデータ型ベースの乗算演算をビットベースのルックアップ テーブル (LUT) ルックアップに変換することです。この方法では、乗算演算が不要になるだけでなく、加算演算も削減されるため、演算効率が大幅に向上します。
具体的には、T-MAC は次の手順で実装されます。
重み行列を複数の 1 ビット行列に分解します。
アクティブ化ベクトルと考えられるすべての 1 ビット パターンの積を事前計算し、結果をルックアップ テーブルに保存します。
推論中、最終的な行列乗算の結果は、ルックアップ テーブルのインデックスと累積演算を通じて迅速に取得されます。
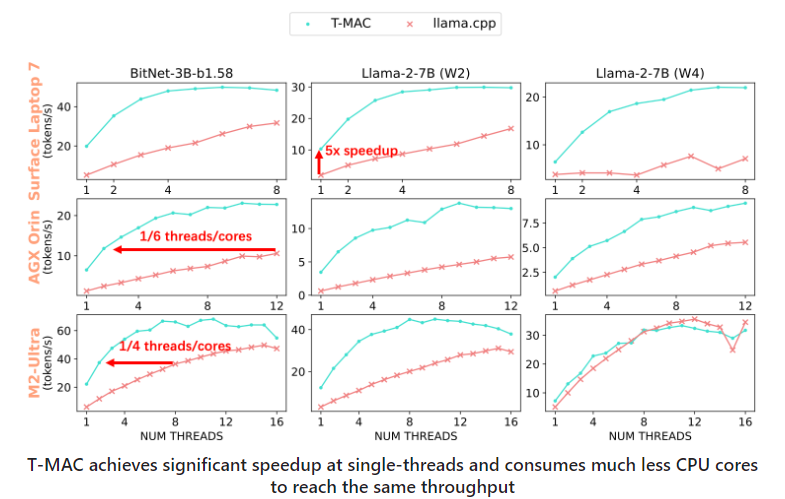
さまざまなエッジ デバイスでのテストを通じて、T-MAC はパフォーマンスに大きな利点があることがわかりました。既存の llama.cpp 実装と比較して、T-MAC はスループットを 4 倍向上させ、エネルギー消費を 70% 削減します。これにより、Raspberry Pi5 などのローエンド デバイスでも、成人の平均的な読書速度よりも速くトークンを生成できるようになります。
T-MAC には理論上の利点があるだけでなく、実用化の可能性もあります。スマートフォンでリアルタイムの音声認識や自然言語処理を実行する場合でも、スマート ホーム デバイスでよりインテリジェントなインタラクティブ エクスペリエンスを提供する場合でも、T-MAC は重要な役割を果たします。
T-MAC テクノロジーは、エッジ デバイス上で低ビットの大規模言語モデルを展開するための効率的でエネルギー節約のソリューションを提供します。デバイスのインテリジェンス レベルを向上させるだけでなく、より豊かで便利なインテリジェント エクスペリエンスをユーザーにもたらすことができます。テクノロジーの継続的な開発と最適化により、T-MAC がエッジ インテリジェンスの分野でますます重要な役割を果たすようになると考える理由があります。
オープンソースのアドレス: https://github.com/microsoft/T-MAC
論文アドレス: https://www.arxiv.org/pdf/2407.00088
T-MAC テクノロジーの出現は、エッジ コンピューティングの分野に新たなブレークスルーをもたらし、その高効率と省エネルギーにより、さまざまなスマート デバイスでの幅広い応用が可能になります。今後もT-MACはさらに改良され、よりスマートで便利な世界の構築に貢献できるものと信じております。