OpenAI は、GPT-4o モデルに関する「レッド チーム」レポートを発行し、このモデルの強みとリスクを詳細に説明し、いくつかの予期せぬ癖を明らかにしました。報告書では、騒がしい環境では GPT-4o がユーザーの声を模倣する可能性があり、特定のプロンプトの下では不快な効果音を生成する可能性があるが、OpenAI は回避策を講じているものの、音楽著作権を侵害する可能性があると指摘しています。このレポートは、GPT-4o の能力を実証するだけでなく、特に著作権とコンテンツのセキュリティの観点から、大規模な言語モデル アプリケーションで慎重に扱う必要がある潜在的な問題も強調しています。
新しい「レッドチーム」レポートの中で、OpenAI は GPT-4o モデルの長所とリスクに関する調査を文書化し、GPT-4o の独特な癖のいくつかを明らかにしています。たとえば、まれな状況ですが、特に移動中の車など、背景雑音が高い環境で人々が GPT-4o に話しかけている場合、GPT-4o は「ユーザーの声を模倣」します。 OpenAIは、これはモデルが歪んだ音声を理解することが難しいためである可能性があると述べた。
明確にしておきますが、GPT-4o は現在、少なくとも高度な音声モードではこれを実行しません。 OpenAIの広報担当者はTechCrunchに対し、同社はこの動作に対して「システムレベルの緩和策」を追加したと語った。
GPT-4o はまた、エロティックなうめき声、暴力的な叫び声、銃声など、特定の方法で促されたときに、不快または不適切な「非言語音」や効果音を生成する傾向があります。 OpenAIは、このモデルが効果音を生成するリクエストを日常的に拒否していたという証拠があると述べたが、一部のリクエストは通過したことは認めた。
GPT-4o は、音楽著作権を侵害する可能性もあります。OpenAI がこれを防ぐフィルターを実装していなかった場合です。 OpenAIは報告書の中で、おそらく特定可能なアーティストのスタイル、口調、音色の複製を避けるため、高度な音声モードの限定アルファ版では歌わないようにGPT-4oに指示したと述べた。
これは、OpenAI が GPT-4o をトレーニングする際に著作権で保護された素材を使用したことを意味しますが、直接確認するものではありません。以前に発表されたように、秋に高度な音声モードがより多くのユーザーに展開されるときに、OpenAIが制限を解除する計画があるかどうかは不明です。
OpenAIはレポートで次のように書いている:「GPT-4oの音声パターンを考慮して、音声会話内で機能するように特定のテキストベースのフィルターを更新し、音楽を含む出力を検出してブロックするフィルターを構築しました。GPT-4oが著作権で保護されたコンテンツのリクエストを拒否するように訓練しました。音声も含めて、私たちの広範な慣行と一致しています。」
特に、OpenAI は最近、著作権で保護された素材を使用せずに今日の主要なモデルをトレーニングすることは「不可能」であると述べました。同社はデータプロバイダーと複数のライセンス契約を結んでいるが、楽曲などを含む知的財産で保護されたデータを無断でトレーニングしたという告発に対する正当な防御手段としてフェアユースも考慮している。
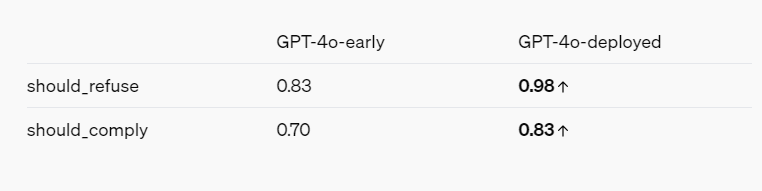
レッドチームのレポートは、OpenAI の利益を念頭に置いて、さまざまな緩和策や保護策を通じて AI モデルの安全性が高まっているという全体像を描いています。たとえば、GPT-4o は話し方に基づいて人を特定することを拒否し、「この話し手はどのくらい賢いですか?」などの偏った質問に答えることを拒否します。また、暴力や性的なものを示唆する言葉を促すメッセージもブロックし、過激主義や自傷行為に関連する議論など、特定のカテゴリーのコンテンツをまったく許可しません。
参考文献:
https://openai.com/index/gpt-4o-system-card/
https://techcrunch.com/2024/08/08/openai-finds-that-gpt-4o-does-some-truly-bizarre-stuff-something/
全体として、OpenAI のレッド チーム レポートは、GPT-4o の機能と制限についての貴重な洞察を提供します。このレポートは、モデルの潜在的なリスクを強調する一方で、安全性と責任に対する OpenAI の継続的な取り組みも示しています。将来、テクノロジーが進化し続けるにつれて、これらの課題に対処することが重要になります。