大規模言語モデル (LLM) は、長いテキストの理解において課題に直面しており、コンテキスト ウィンドウのサイズによって処理能力が制限されます。この問題を解決するために、研究者は LLM の長期コンテキスト理解能力を評価する LooGLE ベンチマーク テストを開発しました。 LooGLE には、2022 年以降にリリースされた 776 件の超長文書 (平均 19.3k ワード) と、複数の分野をカバーする 6448 件のテスト インスタンスが含まれており、長いテキストを理解して処理するモデルの能力をより包括的に評価することを目的としています。このベンチマークは既存の LLM のパフォーマンスを評価し、将来のモデルの開発に貴重な参考資料を提供します。
自然言語処理の分野では、長い文脈を理解することが常に課題でした。大規模言語モデル (LLM) はさまざまな言語タスクで良好に機能しますが、コンテキスト ウィンドウのサイズを超えるテキストを処理する場合は制限されることがよくあります。この制限を克服するために、研究者たちは、長いテキストを理解する LLM の能力を向上させることに懸命に取り組んできました。これは、学術研究だけでなく、ドメイン固有の知識の理解など、現実世界の応用シナリオにとっても重要です。ダイアログの生成や長いストーリーの生成なども重要です。
この研究では、著者らは、LLM の長文コンテキスト理解能力を評価するために特別に設計された新しいベンチマーク テストである LooGLE (長文コンテキスト汎用言語評価) を提案します。このベンチマークには、2022 年以降の 776 の超長いドキュメントが含まれており、各ドキュメントには平均 19.3,000 ワードが含まれており、学術、歴史、スポーツ、政治、芸術、イベント、エンターテイメントなどの複数の分野をカバーする 6,448 のテスト インスタンスがあります。
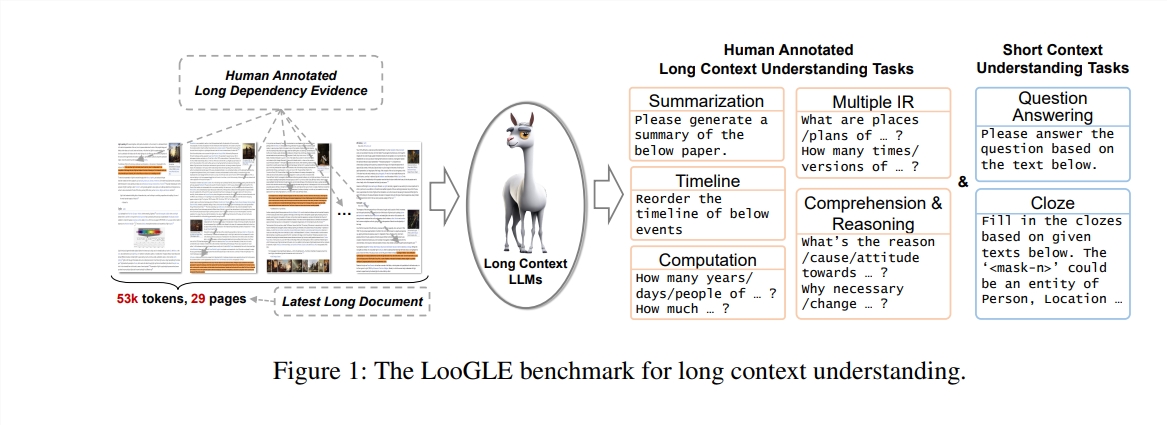
LooGLEの特徴
超長い実際のドキュメント: ooGLE のドキュメントの長さは、LLM のコンテキスト ウィンドウ サイズをはるかに超えているため、モデルが長いテキストを記憶して理解できる必要があります。
手動で設計された長い依存関係タスクと短い依存関係タスク: ベンチマーク テストには、長い依存関係と短い依存関係の内容を理解する LLM の能力を評価するための、短い依存関係タスクと長い依存関係タスクを含む 7 つの主要なタスクが含まれています。
比較的新しいドキュメント: すべてのドキュメントは 2022 年以降にリリースされました。これにより、ほとんどの最新の LLM が事前トレーニング中にこれらのドキュメントにさらされていないことが保証され、状況に応じた学習能力をより正確に評価できるようになります。
クロスドメイン共通データ: ベンチマーク データは、arXiv 論文、Wikipedia 記事、映画やテレビの台本などの一般的なオープン ソース ドキュメントから取得されます。
研究者らは 8 つの最先端の LLM の包括的な評価を実施し、その結果、次の重要な発見が明らかになりました。
商用モデルは、オープンソース モデルよりもパフォーマンスが優れています。
LLM は、依存関係の短いタスクでは良好に機能しますが、より複雑な依存関係の長いタスクでは課題が発生します。
コンテキスト学習と思考連鎖に基づく方法では、長いコンテキストの理解において限定的な改善しか得られません。
検索ベースの手法は、短い質問に答える場合に大きな利点を示しますが、最適化された Transformer アーキテクチャまたは位置エンコーディングによってコンテキスト ウィンドウの長さを拡張する戦略は、長いコンテキストの理解には限定的な影響を与えます。
LooGLE ベンチマークは、ロングコンテキスト LLM を評価するための体系的かつ包括的な評価スキームを提供するだけでなく、「真のロングコンテキスト理解」機能を備えたモデルの将来の開発のためのガイダンスも提供します。すべての評価コードは、研究コミュニティによる参照と使用のために GitHub で公開されています。
論文アドレス: https://arxiv.org/pdf/2311.04939
コードアドレス: https://github.com/bigai-nlco/LooGLE
LooGLE ベンチマークは、LLM の長文理解能力を評価および向上させるための重要なツールを提供し、その研究成果は自然言語処理分野の発展を促進する上で非常に重要です。 研究者らによって提案された改善の方向性は注目に値します。私は、長いテキストをより適切に処理するために、より強力な LLM が今後さらに登場すると信じています。