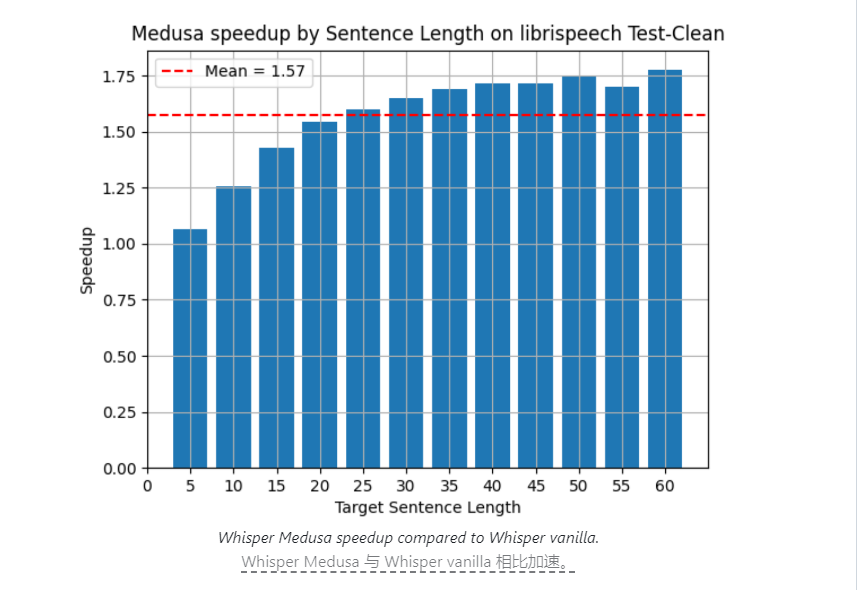
イスラエルの人工知能企業 aiOla は最近、Whisper Medusa と呼ばれるオープンソースの音声認識モデルをリリースしました。このモデルは速度の大幅な進歩を達成しており、その処理速度は OpenAI の Whisper モデルよりも 50% 高速です。この画期的な進歩は業界で広く注目を集めており、その核心は改善されたアーキテクチャ設計と革新的なトレーニング方法にあります。 Whisper Medusa は高速なだけでなく、高い精度と安定性を維持し、音声認識技術の開発に新たな可能性をもたらします。
イスラエルの人工知能企業 aiOla は最近、音声認識技術の分野で大きな進歩を遂げ、Whisper Medusa と呼ばれるオープンソースの音声認識モデルを発表しました。この新しいモデルの処理速度は、業界で広く注目を集めている OpenAI の Whisper モデルよりも 50% 高速です。
Whisper Medusa の核となる革新は、改良されたアーキテクチャ デザインです。 aiOla は Whisper のオリジナルのアーキテクチャを変更し、マルチヘッド アテンション メカニズムを導入しました。このメカニズムにより、モデルは複数のアテンション ヘッドを並行して使用することで、異なる表現部分空間からの情報に同時に焦点を当てることができます。この革新により、モデルは従来の一度に 1 つのトークンではなく、一度に 10 個のトークンを予測できるようになり、音声予測速度と生成ランタイムが大幅に向上します。
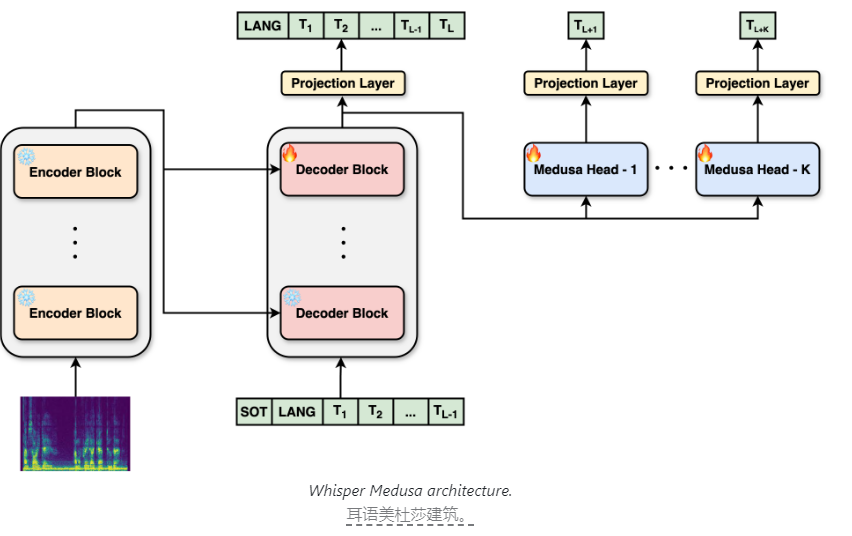
Whisper Medusa がパフォーマンスを犠牲にすることなく速度を向上させることは注目に値します。これは、バックボーン システムが依然として Whisper に基づいており、モデルの精度と安定性が確保されているためです。トレーニング プロセス中に、aiOla は弱い監視と呼ばれる機械学習手法を使用します。具体的には、Whisper の主要コンポーネントを凍結し、追加のトークン予測モジュールをトレーニングするためのラベルとしてモデルによって生成された音声転写を使用しました。この革新的なトレーニング方法により、モデルの学習効率と精度がさらに向上します。
Whisper Medusa のオープンソース リリースは、音声認識技術の開発に大きな影響を与える可能性があります。研究者や開発者に強力な新しいツールを提供するだけでなく、より高速で効率的な音声処理アプリケーションの開発を促進する可能性もあります。音声インタラクションの需要が高まる中、この技術的進歩は間違いなく、音声認識分野における人工知能の応用に新たな可能性を切り開くでしょう。
Whisper Medusa の発売により、スマート アシスタントからリアルタイム翻訳、音声制御システムに至るまで、このモデルに基づくより革新的なアプリケーションが登場することが期待され、その結果、すべてのアプリケーションで大幅なパフォーマンスの向上が得られる可能性があります。この進歩は、音声認識技術における重要なマイルストーンを示すだけでなく、人工知能と人間の間の相互作用の将来に向けて、より効率的かつスムーズな青写真を描きます。
プロジェクトアドレス: https://github.com/aiola-lab/whisper-medusa
ハグフェイス: https://huggingface.co/aiola/whisper-medusa-v1
Whisper Medusa のオープンソースと高いパフォーマンスは、音声認識テクノロジーが開発の新たな波をもたらし、さまざまな音声アプリケーションによりスムーズで効率的なエクスペリエンスをもたらし、より多くの分野で人工知能テクノロジーの応用を促進することを示しています。このモデルに基づいた革新的なアプリケーションがさらに登場することを楽しみにしています。