急成長を遂げる AI 分野では、データ取得方法がますます注目を集めています。この記事では、AI 企業 Anthropic 傘下の Claude チームの大規模なデータ スクレイピング行為によって引き起こされた論争について考察します。 Claude チームのクローラー プログラム ClaudeBot は、複数の Web サイトから大量のデータを許可なくクロールし、Web サイトの規制に違反しただけでなく、サーバー リソースの大量消費を引き起こし、広く批判と懸念を引き起こしました。この事件はAI開発とデータ著作権保護の間の矛盾を浮き彫りにし、業界がデータ取得の倫理と法的規範を再考するきっかけとなった。
インシデントの原因は、クロードのチームのクローラーが 24 時間以内に企業のサーバーに 100 万回アクセスし、Web サイトのコンテンツを無料でクロールしたことです。この行為は、Web サイトのクローリング禁止のアナウンスをあからさまに無視しただけでなく、大量のサーバー リソースを強制的に占有しました。
被害企業は自らを守るための最善の努力にもかかわらず、最終的にはクロードのチームによるデータスクレイピングを阻止できませんでした。会社のリーダーたちは怒ってソーシャルメディアでクロードのチームの行動を非難した。多くのネチズンも不満を表明し、この行為を「盗む」という言葉で表現することを提案する人もいた。
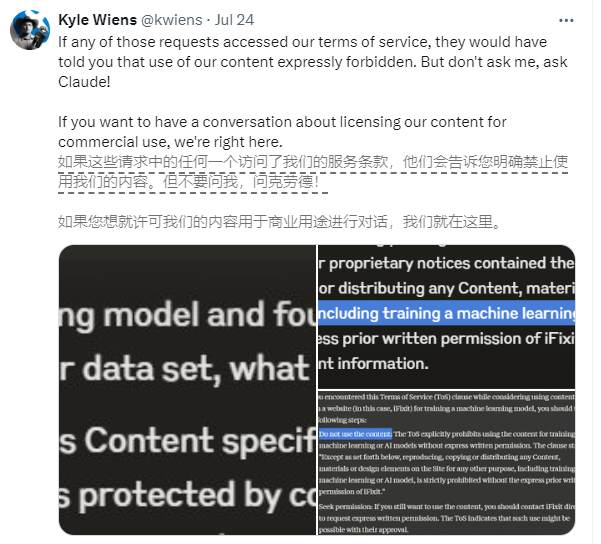
関与している企業は、米国の電子商取引およびハウツー Web サイトである iFixit です。 iFixit は、家庭用電化製品やガジェットを対象とした数百万ページにわたる無料のオンライン修理ガイドを提供しています。しかし、iFixit は、Claude のクローラー プログラム ClaudeBot が短期間に大量のリクエストを開始し、1 日で 10 TB、5 月全体で合計 73 TB のファイルにアクセスしたことを発見しました。
iFixit CEOのKyle Wiens氏は、ClaudeBotが許可なくすべてのデータを盗み、サーバーリソースを占有したと述べた。 iFixit は Web サイトで不正なデータ スクレイピングが禁止されていると明示していますが、Claude チームはこれに目をつぶっているようです。
クロードのチームの行動は特別なものではありません。今年 4 月には、Linux Mint フォーラムも ClaudeBot による頻繁なアクセスに悩まされ、フォーラムの実行が遅くなったり、クラッシュしたりすることがありました。また、ClaudeとOpenAIのGPT以外にも、Webサイトのrobots.txtの設定を無視してデータを強制的に取得しているAI企業は数多くあると指摘する声もあった。
この状況に直面して、Web サイト所有者は、データが違法にスクレイピングされたかどうかを検出するために、追跡可能な情報または固有の情報を含む偽のコンテンツをページに追加することが提案されています。 iFixit は実際にこの措置を講じ、データが Claude だけでなく OpenAI によってもスクレイピングされたことを発見しました。
この事件は、AI企業のデータスクレイピング慣行に関する広範な議論を引き起こした。 AI の開発にはそれをサポートするために大量のデータが必要となる一方で、データの取得には Web サイト所有者の権利と規制も尊重する必要があります。技術の進歩の促進と著作権の保護との間のバランスをどのように見つけるかは、業界全体で考える必要がある問題です。
クロード氏のチームによるデータ窃取事件は警鐘を鳴らし、AI企業は技術の進歩を追求する一方で、知的財産権を尊重し、法律や規制を遵守し、準拠したデータ取得方法を積極的に模索する必要があることを思い出させた。この方法によってのみ、AI テクノロジーの健全な発展を確保し、不適切な行為による業界の評判や社会の信頼の毀損を回避することができます。