Llama 3.1 大規模言語モデルのトレーニングにおける Meta の経験は、AI 開発における前例のない課題と機会を私たちに示してくれました。 16,384 個の GPU からなる巨大なクラスターでは、54 日間のトレーニング期間中、平均 3 時間ごとに障害が発生しました。これは、AI モデルの規模の急速な成長を強調しただけでなく、スーパーコンピューティングの安定性における大きなボトルネックも明らかにしました。システム。この記事では、Llama 3.1 のトレーニング プロセス中に Meta が遭遇した課題と、これらの課題に対処するために採用された戦略を詳しく掘り下げ、それが AI 業界全体に与える影響を分析します。
人工知能の世界では、あらゆる画期的な進歩には驚くべきデータが伴います。 16,384 個の GPU が同時に実行されていると想像してください。これは SF 映画のワンシーンではなく、最新の Llama3.1 モデルをトレーニングするときのメタの実際の描写です。しかし、この技術の饗宴の背後には、平均して 3 時間ごとに発生する障害があります。この驚くべき数字は、AI 開発のスピードを示すだけでなく、現在のテクノロジーが直面している大きな課題も明らかにしています。
Llama1 で使用されている 2,028 個の GPU から、Llama3.1 で使用されている 16,384 個の GPU まで、この飛躍的な成長は量の変化であるだけでなく、既存のスーパーコンピューティング システムの安定性に対する極端な挑戦でもあります。 Meta の調査データによると、Llama3.1 の 54 日間のトレーニング サイクル中に、合計 419 件の予期しないコンポーネント障害が発生し、その約半分は H100 GPU とその HBM3 メモリに関連していました。このデータは、AI のパフォーマンスのブレークスルーを追求する一方で、システムの信頼性も同時に向上したのか、ということを考えさせられます。
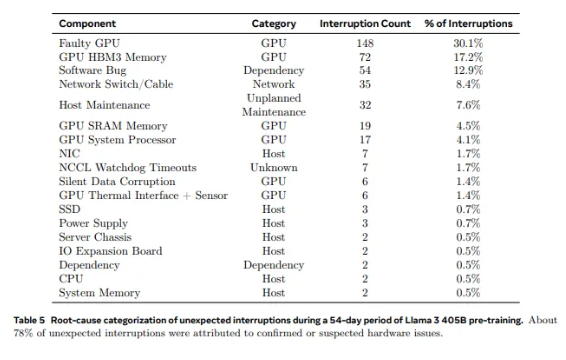
実際、スーパーコンピューティングの分野では、規模が大きくなるほど障害を避けることが難しくなるという、議論の余地のない事実があります。 Meta の Llama 3.1 トレーニング クラスターは、数万のプロセッサ、数十万のその他のチップ、数百マイルのケーブルで構成されており、その複雑さのレベルは小都市のニューラル ネットワークに匹敵します。このような巨大企業では、故障はよくあることのようです。
頻繁な失敗に直面しても、メタ チームは無力ではありませんでした。彼らは、ジョブの起動時間とチェックポイント時間の短縮、独自の診断ツールの開発、PyTorch の NCCL フライト レコーダーの活用など、一連の対処戦略を採用しました。これらの対策により、システムの耐障害性が向上するだけでなく、自動処理機能も強化されます。 Meta のエンジニアは現代の消防士のようなもので、訓練プロセスを中断する可能性のある火災をいつでも消火します。
ただし、課題はハードウェア自体からのみ発生するわけではありません。環境要因や消費電力の変動も、スーパーコンピューティング クラスターに予期せぬ課題をもたらします。 Meta チームは、昼夜の温度変化と GPU 消費電力の急激な変動がトレーニングのパフォーマンスに大きな影響を与えることを発見しました。この発見は、技術の進歩を追求する一方で、環境とエネルギー消費の管理の重要性を無視できないことを思い出させます。
Llama3.1 のトレーニング プロセスは、スーパーコンピューティング システムの安定性と信頼性を試す究極のテストと言えます。課題に対処するためにメタ チームが採用した戦略と開発された自動化ツールは、AI 業界全体に貴重な経験とインスピレーションを提供します。困難にもかかわらず、技術の継続的な進歩により、将来のスーパーコンピューティング システムはより強力で安定したものになると信じる理由があります。
AI技術が急速に発展しているこの時代において、メタの試みは間違いなく勇気ある冒険である。これは、AI モデルのパフォーマンスの限界を押し上げるだけでなく、限界を追求する際に直面する本当の課題も示しています。 AI技術がもたらす無限の可能性に期待するとともに、テクノロジーの最前線でたゆまぬ努力を続ける技術者たちを讃えましょう。彼らが行うあらゆる試み、あらゆる失敗、あらゆる画期的な進歩が、人類の技術進歩への道を切り開きます。
参考文献:
https://www.tomshardware.com/tech-industry/artificial-intelligence/faulty-nvidia-h100-gpus-and-hbm3-memory-caused-half-of-the-failures-during-llama-3-training-メタス 16384-GPU トレーニング クラスターの 3 時間ごとに 1 回の障害
Llama 3.1 のトレーニング ケースは、私たちに貴重な教訓を提供し、スーパーコンピューティング システムの将来の開発の方向性を指摘しました。パフォーマンスを追求する一方、システムの安定性と信頼性を非常に重視し、さまざまな障害に対処する戦略を積極的に模索する必要があります。この方法によってのみ、AI テクノロジーの継続的かつ安定した開発を確保し、人類に利益をもたらすことができます。