NVIDIA は最近、4B および 8B バージョンを含む小型言語モデルの Minitron シリーズをリリースしました。この動きは、大規模な言語モデルのトレーニングと展開のコストを削減し、より多くの開発者がこの高度なテクノロジを簡単に使用できるようにすることを目的としています。 Minitron モデルは、「枝刈り」と「知識の蒸留」テクノロジーにより、大型モデルと同等のパフォーマンスを維持しながらモデル サイズを大幅に縮小し、一部の指標では他のよく知られたモデルを上回っています。これは人工知能技術の普及を促進する上で非常に重要です。
最近、NVIDIA は人工知能の分野で新たな動きを出し、4B および 8B バージョンを含む小型言語モデルの Minitron シリーズを発売しました。これらのモデルは、トレーニング速度を 40 倍に高速化するだけでなく、開発者が翻訳、感情分析、会話型 AI などのさまざまなアプリケーションに簡単に使用できるようにします。
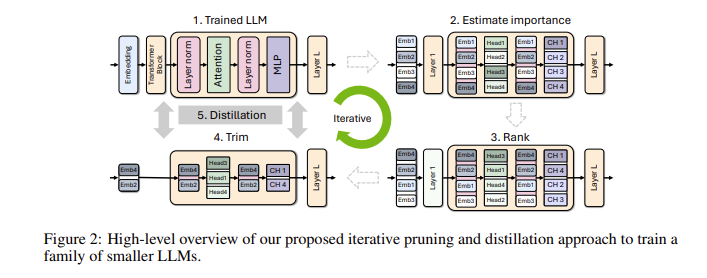
なぜ小規模な言語モデルがそれほど重要なのかと疑問に思われるかもしれません。実際、従来の大規模な言語モデルは優れたパフォーマンスを持っていますが、トレーニングと展開のコストが非常に高く、多くの場合、大量のコンピューティング リソースとデータが必要になります。これらの高度なテクノロジをより多くの人が利用できるようにするために、NVIDIA の研究チームは、「枝刈り」と「知識の蒸留」という 2 つのテクノロジを組み合わせてモデルのサイズを効率的に削減するという素晴らしい方法を考え出しました。
具体的には、研究者はまず既存の大規模モデルから出発し、それを枝刈りします。これらは、モデル内の各ニューロン、層、またはアテンション ヘッドの重要性を評価し、重要性の低いものを削除します。このようにして、モデルは大幅に小さくなり、トレーニングに必要なリソースと時間も大幅に削減されます。次に、小規模のデータセットを使用して、枝刈りされたモデルに対して知識の蒸留トレーニングを実行し、モデルの精度を復元します。驚くべきことに、このプロセスはコストを節約するだけでなく、モデルのパフォーマンスも向上します。
実際のテストでは、NVIDIA の研究チームは Nemotron-4 モデル ファミリで良好な結果を達成しました。同様のパフォーマンスを維持しながら、モデルのサイズを 2 ~ 4 倍に縮小することに成功しました。さらに興味深いのは、8B モデルが複数の指標において Mistral7B や LLaMa-38B などの他のよく知られたモデルを上回っており、トレーニング プロセス中に必要なトレーニング データが 40 分の 1 に減り、コンピューティング コストが 1.8 倍節約されることです。これが何を意味するか想像してみてください。より多くの開発者が、より少ないリソースとコストで強力な AI 機能を体験できるようになります。
NVIDIA は、これらの最適化された Minitron モデルを、誰もが自由に使用できるように、Huggingface 上でオープンソースにします。
デモの入り口: https://huggingface.co/collections/nvidia/minitron-669ac727dc9c86e6ab7f0f3e
ハイライト:
** トレーニング速度の向上 **: Minitron モデルのトレーニング速度は従来のモデルより 40 倍速く、開発者は時間と労力を節約できます。
**コスト削減**: プルーニングと知識の蒸留テクノロジーにより、トレーニングに必要なコンピューティング リソースとデータ量が大幅に削減されます。
? **オープンソース共有**: Minitron モデルは Huggingface でオープンソース化されているため、より多くの人が簡単にアクセスして使用できるようになり、AI テクノロジーの普及が促進されます。
Minitron モデルのオープンソースは、小規模言語モデルの実用化における重要な進歩を示しています。また、人工知能テクノロジーがより普及し、より使いやすくなり、より多くの開発者とアプリケーション シナリオが可能になることを示しています。将来的には、人工知能技術の継続的な開発を促進するために、より多くの同様のイノベーションが期待されます。