Nvidia AI によってリリースされた最新の ChatQA2 モデルは、長いテキストのコンテキストの理解と検索拡張生成 (RAG) の分野で大きな進歩を遂げました。これは強力な Llama3 モデルに基づいており、コンテキスト ウィンドウを 128K トークンに拡張し、3 段階の命令微調整を採用することにより、命令追従機能、RAG パフォーマンス、および長文理解機能が大幅に向上します。 ChatQA2 は、大量のテキスト データを処理する際にコンテキストの一貫性と高い再現率を維持することができ、複数のベンチマーク テストで GPT-4-Turbo に匹敵するパフォーマンスを実証し、いくつかの側面では GPT-4-Turbo を上回りました。 これは、大規模な言語モデルで長いテキストを処理できる能力が大幅に進歩したことを示しています。
パフォーマンスのブレークスルー: ChatQA2 は、コンテキスト ウィンドウを 128K トークンに拡張し、3 段階の命令調整プロセスを採用することにより、命令追従機能、RAG パフォーマンス、および長いテキストの理解を大幅に向上させます。この技術的進歩により、モデルは最大 10 億トークンのデータセットを処理する際に、コンテキストの一貫性と高い再現率を維持できるようになります。
技術的な詳細: ChatQA2 は、詳細かつ再現可能な技術ソリューションを使用して開発されました。このモデルはまず、継続的な事前トレーニングを通じて Llama3-70B のコンテキスト ウィンドウを 8K トークンから 128K トークンに拡張します。次に、モデルがさまざまなタスクを効果的に処理できるようにするために、3 段階の命令チューニング プロセスが適用されました。
評価結果: InfiniteBench の評価では、ChatQA2 は長文の要約、質疑応答、多肢選択、対話などのタスクで GPT-4-Turbo-2024-0409 に匹敵する精度を達成し、RAG ベンチマークではそれを上回りました。この成果は、さまざまなコンテキストの長さと機能にわたる ChatQA2 の包括的な機能を浮き彫りにします。
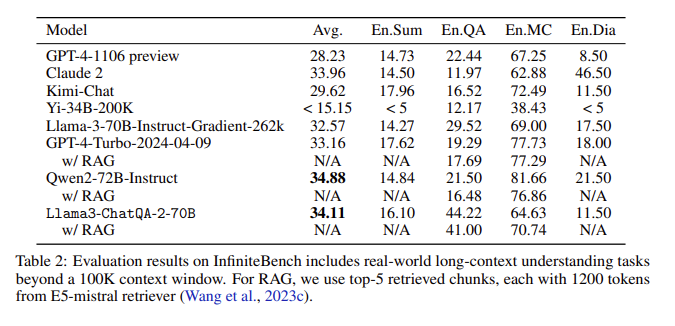
主要な問題への対処: ChatQA2 は、最先端の長いテキスト取得機能を使用して、取得の精度と効率を向上させることで、コンテキストの断片化や再現率の低さなど、RAG プロセスの主要な問題をターゲットにしています。
コンテキスト ウィンドウを拡張し、3 段階の命令チューニング プロセスを実装することにより、ChatQA2 は、GPT-4-Turbo に匹敵する長いテキストの理解と RAG パフォーマンスを実現します。このモデルは、高度な長文テキストと検索強化生成技術を通じて精度と効率のバランスをとり、さまざまな下流タスクに柔軟なソリューションを提供します。
論文の入り口: https://arxiv.org/abs/2407.14482
ChatQA2 の出現は、長いテキスト処理と RAG アプリケーションに新たな可能性をもたらし、その効率と精度は、人工知能の将来の開発に重要な参考値を提供します。 このモデルに関する公開研究は、学界と産業界のコラボレーションも促進し、この分野の継続的な進歩を推進します。 将来的には、このモデルに基づくさらに革新的なアプリケーションが登場することを楽しみにしています。