Apple と Meta AI は共同で、長いテキスト推論の処理における大規模言語モデル (LLM) の効率を大幅に向上させるように設計された LazyLLM と呼ばれる新テクノロジーを発表しました。現在の LLM が長いプロンプトを処理すると、アテンション メカニズムの計算の複雑さがトークンの数の 2 乗に応じて増加し、特にプリチャージ段階で速度が遅くなります。 LazyLLM は、計算のために重要なトークンを動的に選択して計算量を効果的に削減し、刈り取られたトークンを効率的に復元する補助キャッシュ メカニズムを導入することで、精度を確保しながら速度を大幅に向上させます。
最近、Apple の研究チームとメタ AI 研究者は共同で、長文推論における大規模言語モデル (LLM) の効率を向上させる LazyLLM と呼ばれる新技術を発表しました。
周知のとおり、現在の LLM は、長いプロンプトを処理するとき、特にプリチャージ段階で速度低下の問題に直面することがよくあります。これは主に、アテンションを計算する際の最新のトランスフォーマー アーキテクチャの計算の複雑さが、ヒント内のトークンの数に応じて二次関数的に増加するためです。したがって、Llama2 モデルを使用する場合、最初のトークンの計算時間は、後続のデコード ステップの計算時間の 21 倍になることが多く、生成時間の 23% を占めます。
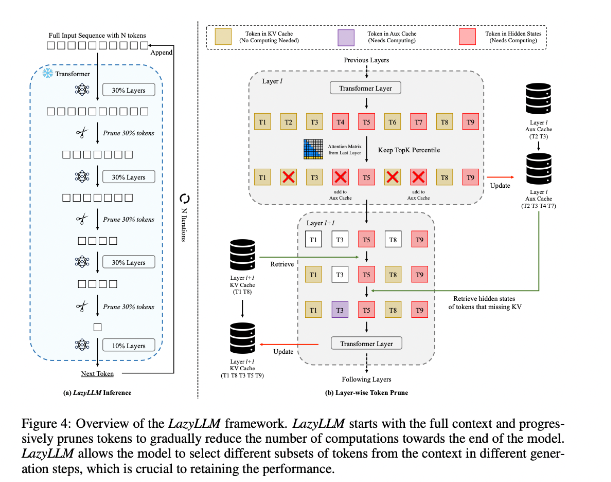
この状況を改善するために、研究者らは重要なトークンの計算方法を動的に選択することでLLM推論を高速化する新しい手法であるLazyLLMを提案しました。 LazyLLM の核心は、前の層の注意スコアに基づいて各トークンの重要性を評価し、それによって計算量を徐々に削減することです。永続的な圧縮とは異なり、LazyLLM はモデルの精度を確保するために必要に応じてプルーニングされたトークンを復元できます。さらに、LazyLLM は Aux Cache と呼ばれるメカニズムを導入しています。これは、プルーニングされたトークンの暗黙的な状態を保存して、これらのトークンを効率的に復元し、パフォーマンスの低下を防ぐことができます。
LazyLLM は、特に事前入力段階とデコード段階での推論速度に優れています。この手法の 3 つの主な利点は、トランスフォーマー ベースの LLM と互換性があること、実装中にモデルの再トレーニングが必要ないこと、さまざまな言語タスクを非常に効率的に実行できることです。 LazyLLM の動的プルーニング戦略により、最も重要なトークンを保持しながら計算量を大幅に削減できるため、生成速度が向上します。
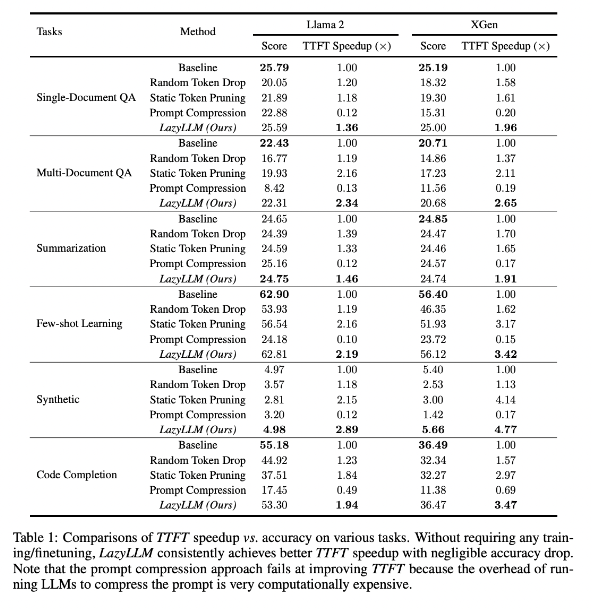
研究結果によると、LazyLLM は複数言語タスクで優れたパフォーマンスを発揮し、TTFT 速度は 2.89 倍 (Llama2 の場合)、4.77 倍 (XGen の場合) 向上し、精度はベースラインとほぼ同じであることがわかりました。質問応答、要約生成、またはコード補完タスクのいずれであっても、LazyLLM はより高速な生成速度を達成し、パフォーマンスと速度の適切なバランスを実現できます。レイヤーごとの分析と組み合わせた段階的なプルーニング戦略が、LazyLLM の成功の基礎を築きます。
論文アドレス: https://arxiv.org/abs/2407.14057
ハイライト:
LazyLLM は、特に長いテキストのシナリオで重要なトークンを動的に選択することにより、LLM 推論プロセスを高速化します。
この技術により推論速度が大幅に向上し、高精度を維持したままTTFT速度を最大4.77倍向上させることができます。
LazyLLM は既存のモデルを変更する必要がなく、コンバータベースの LLM と互換性があり、実装が簡単です。
全体として、LazyLLM の出現は、LLM 長いテキストの推論効率の問題を解決するための新しいアイデアと効果的なソリューションを提供します。その速度と精度の優れたパフォーマンスは、LazyLLM が将来の大規模モデル アプリケーションで重要な役割を果たすことを示しています。 この技術は幅広い応用の可能性を秘めており、さらなる開発と応用が期待されます。