Llama 3.1は、4,050億個のパラメータを持つ巨大なオープンソース言語モデルで、正式リリースなしのリークによりAI分野に大きな衝撃を与えました。そのパフォーマンスは非常に強力で、一部のベンチマーク テストでは GPT-4o をも上回り、オープンソース モデルの新たなベンチマークを設定しました。 Reddit での白熱した議論は、AI コミュニティへの影響をさらに証明しています。この記事では、Llama 3.1 のパフォーマンス、ハイライト、安全対策を詳しく掘り下げ、この謎に満ちたモデルを明らかにします。
Llama3.1 がリークされました! ご存知のとおり、4,050 億のパラメータを備えたこのオープンソース モデルは Reddit で大騒ぎを引き起こしました。これはおそらく、これまでで GPT-4o に最も近いオープンソース モデルであり、いくつかの点では GPT-4o を上回っています。
Llama3.1 は、Meta (旧 Facebook) によって開発された大規模な言語モデルです。まだ正式リリースはありませんが、リークされたバージョンはすでにコミュニティで騒動を引き起こしています。このモデルには、ベースモデルだけでなく、8B、70B、および最大パラメータ 405B のベンチマーク結果も含まれています。
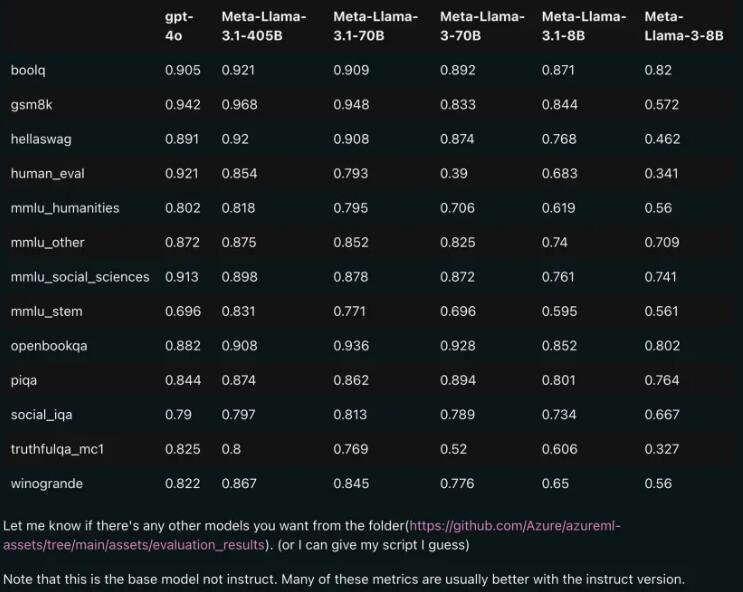
パフォーマンスの比較: Llama3.1 vs GPT-4o
リークされた比較結果から判断すると、Llama3.1 の 70B バージョンでさえ、複数のベンチマーク テストで GPT-4o を上回りました。オープンソース モデルが複数のベンチマークで SOTA (State of the Art、最先端のテクノロジー) レベルに達したのはこれが初めてです。オープンソースの力は本当に強力です。
モデルのハイライト: 多言語サポート、より豊富なトレーニング データ
Llama3.1 モデルは、トレーニングに公的ソースからの 15T+ トークンを使用しており、トレーニング前データの期限は 2023 年 12 月です。英語だけでなく、フランス語、ドイツ語、ヒンディー語、イタリア語、ポルトガル語、スペイン語、タイ語にも対応しています。これは、多言語での会話のユースケースに最適です。

Llama3.1 研究チームはモデルのセキュリティを非常に重視しています。彼らは、人間が生成したデータと合成データを組み合わせた多面的なデータ収集アプローチを使用して、潜在的なセキュリティ リスクを軽減しました。さらに、このモデルでは、データ品質管理を強化するために、境界プロンプトと敵対的プロンプトも導入されています。
モデルカードのソース: https://pastebin.com/9jGkYbXY#google_vignette
Llama 3.1の流出は間違いなくAI分野に大きな影響を与えるだろう。これは、オープンソース モデルの大きな可能性を実証するだけでなく、モデルのセキュリティと倫理的問題についてさらに考えるきっかけにもなります。今後もLlama 3.1とその後の展開に注目し、AI技術の進歩にさらなる驚きをもたらすことを楽しみにしています。