Apple は、ワシントン大学およびその他の機関と協力して、7 億のパラメータ サイズと 2 兆 5,000 億のデータ トークンに達する驚異的な量のトレーニング データを備えた DCLM と呼ばれる強力な言語モデルをオープン ソースとしてリリースしました。 DCLM は効率的な言語モデルであるだけでなく、さらに重要なことに、言語モデルのデータ セットを最適化するための「Dataset Competition」(DataComp) と呼ばれるツールを提供します。このイノベーションはモデルのパフォーマンスを向上させるだけでなく、言語モデルの研究に新しい手法と標準を提供するものであり、注目に値します。
最近、Apple の人工知能チームはワシントン大学などの多くの機関と協力して、DCLM と呼ばれるオープンソース言語モデルを立ち上げました。このモデルには 7 億のパラメーターがあり、トレーニング中に最大 2 兆 5,000 億のデータ トークンを使用して、言語の理解を深め、生成するのに役立ちます。
では、言語モデルとは何でしょうか? 簡単に言うと、言語を分析して生成し、翻訳、テキスト生成、感情分析などのさまざまなタスクを完了するのに役立つプログラムです。これらのモデルのパフォーマンスを向上させるには、高品質のデータセットが必要です。ただし、無関係または有害なコンテンツを除外し、重複した情報を削除する必要があるため、このデータを取得して整理するのは簡単な作業ではありません。
この課題に対処するために、Apple の研究チームは、言語モデルのデータセット最適化ツールである DataComp for Language Models (DCLM) を立ち上げました。彼らは最近、Hugging Face プラットフォーム上の DCIM モデルとデータセットをオープンソース化しました。オープンソース バージョンには、DCLM-7B、DCLM-1B、dclm-7b-it、DCLM-7B-8k、dclm-baseline-1.0、および dclm-baseline-1.0-parquet が含まれており、研究者はこのプラットフォームを通じて多数の実験を行うことができます。効果的なデータ ラングリング戦略を見つけます。
https://huggingface.co/collections/mlfoundations/dclm-669938432ef5162d0d0bc14b
DCLM の中核的な強みは、構造化されたワークフローです。研究者は、ニーズに応じて 4 億 1,200 万から 7 億のパラメータの範囲でさまざまなサイズのモデルを選択でき、重複排除やフィルタリングなどのさまざまなデータ キュレーション方法を試すこともできます。これらの体系的な実験を通じて、研究者はさまざまなデータセットの品質を明確に評価できます。これは将来の研究の基礎を築くだけでなく、データセットを改善してモデルのパフォーマンスを向上させる方法を理解するのにも役立ちます。
たとえば、DCLM によって確立されたベンチマーク データ セットを使用して、研究チームは 7 億のパラメーターで言語モデルをトレーニングし、MMLU ベンチマーク テストで 5 ショット精度 64% を達成しました。これは、以前と比較して 6.6 の向上です。最高レベルで、コンピューティング リソースの使用量が 40% 削減されます。 DCLM ベースライン モデルのパフォーマンスは、より多くのコンピューティング リソースを必要とする Mistral-7B-v0.3 および Llama38B にも匹敵します。
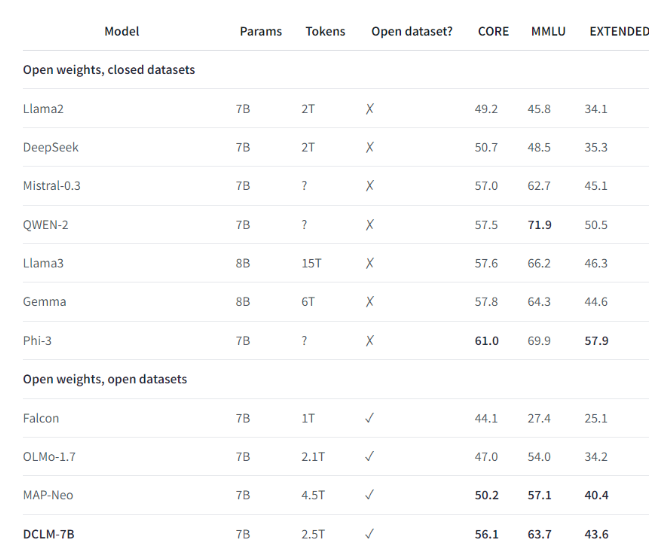
DCLM の開始により、言語モデル研究の新しいベンチマークが提供され、科学者が必要なコンピューティング リソースを削減しながらモデルのパフォーマンスを体系的に向上させることができます。
ハイライト:
1️⃣ Apple AI は複数の機関と協力して DCLM を立ち上げ、強力なオープンソース言語モデルを作成しました。
2️⃣ DCLM は、研究者が効果的な実験を行うのに役立つ標準化されたデータセット最適化ツールを提供します。
3️⃣ 新しいモデルは、計算リソース要件を削減しながら、重要なテストで大幅な進歩を遂げています。
全体として、DCLM のオープンソースは言語モデル研究の分野に新たな活力を注入しており、その効率的なモデルおよびデータセット最適化ツールは、この分野での開発の迅速化を促進し、より強力で効率的な言語モデルの誕生を促進すると期待されています。今後、DCLMがさらに驚くべき研究成果をもたらすことが期待されます。