Alibaba Tongyi Qianwen チームは、Qwen2 シリーズのオープンソース モデルをリリースしました。このシリーズには、5 つのサイズの事前トレーニングおよび命令微調整モデルが含まれており、前世代の Qwen1.5 と比較して、パラメーターの数とパフォーマンスが大幅に向上しました。 Qwen2 シリーズは多言語機能でも大きな進歩を遂げ、英語と中国語以外の 27 言語をサポートしています。自然言語の理解、コーディング、数学的能力などの点で、大規模モデル (70B 以上のパラメーター) が優れたパフォーマンスを発揮し、特に Qwen2-72B モデルはパフォーマンスとパラメーターの数において前世代を上回っています。このリリースは、人工知能テクノロジーの新たな高みを示し、世界的な AI アプリケーションと商業化の幅広い可能性を提供します。
今朝早く、Alibaba Tongyi Qianwen チームは Qwen2 シリーズのオープンソース モデルをリリースしました。このシリーズのモデルには、Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B、および Qwen2-72B の 5 サイズの事前トレーニング済みおよび指示が微調整されたモデルが含まれています。重要な情報は、これらのモデルのパラメーターの数とパフォーマンスが前世代の Qwen1.5 と比較して大幅に向上していることを示しています。
モデルの多言語機能を実現するために、Qwen2 シリーズはデータセットの量と質を高めることに多大な労力を費やし、英語と中国語を除く 27 の言語をカバーしました。比較テストの結果、大規模モデル (70B + パラメーター) は、自然言語理解、コーディング、数学的能力などで良好なパフォーマンスを示しました。Qwen2-72B モデルは、パフォーマンスとパラメーター数の点で前世代を上回りました。
Qwen2 モデルは、基本的な言語モデルの評価で強力な機能を実証するだけでなく、命令チューニング モデルの評価でも優れた結果を達成します。その多言語機能は、M-MMLU や MGSM などのベンチマーク テストで良好なパフォーマンスを示し、Qwen2 命令チューニング モデルの強力な可能性を示しています。
今回リリースされたQwen2シリーズモデルは、人工知能技術の新たな高みを示し、世界的なAI応用と商用化のさらなる可能性を提供します。将来に向けて、Qwen2 はモデルの規模とマルチモーダル機能をさらに拡張し、オープンソース AI 分野の開発を加速します。
機種情報Qwen2 シリーズには、Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B、Qwen2-72B の 5 サイズのベーシック モデルとコマンド チューニング モデルが含まれています。以下の表で各モデルの重要な情報を説明します。
モデル Qwen2-0.5BQwen2-1.5BQwen2-7BQwen2-57B-A14BQwen2-72B# パラメータ 049 百万 154 百万 707B57.41B72.71B# 非 Emb パラメータ 035 百万 131B5 億 9800 万 5632 百万 7021B 品質保証は本当に本当に本当に真の真の結合埋め込みですtrue true false false false false コンテキスト長 32,000 32,000 128,000 64,000 128,000具体的には、Qwen1.5 では、Qwen1.5-32B と Qwen1.5-110B のみがグループ クエリ アテンション (GQA) を使用していました。今回は、すべてのモデル サイズに GQA を適用し、モデル推論の高速化とメモリ フットプリントの削減のメリットを享受できるようにしました。小規模なモデルの場合は、大規模な疎埋め込みがモデルの合計パラメーターの大部分を占めるため、結合埋め込みを適用することを好みます。
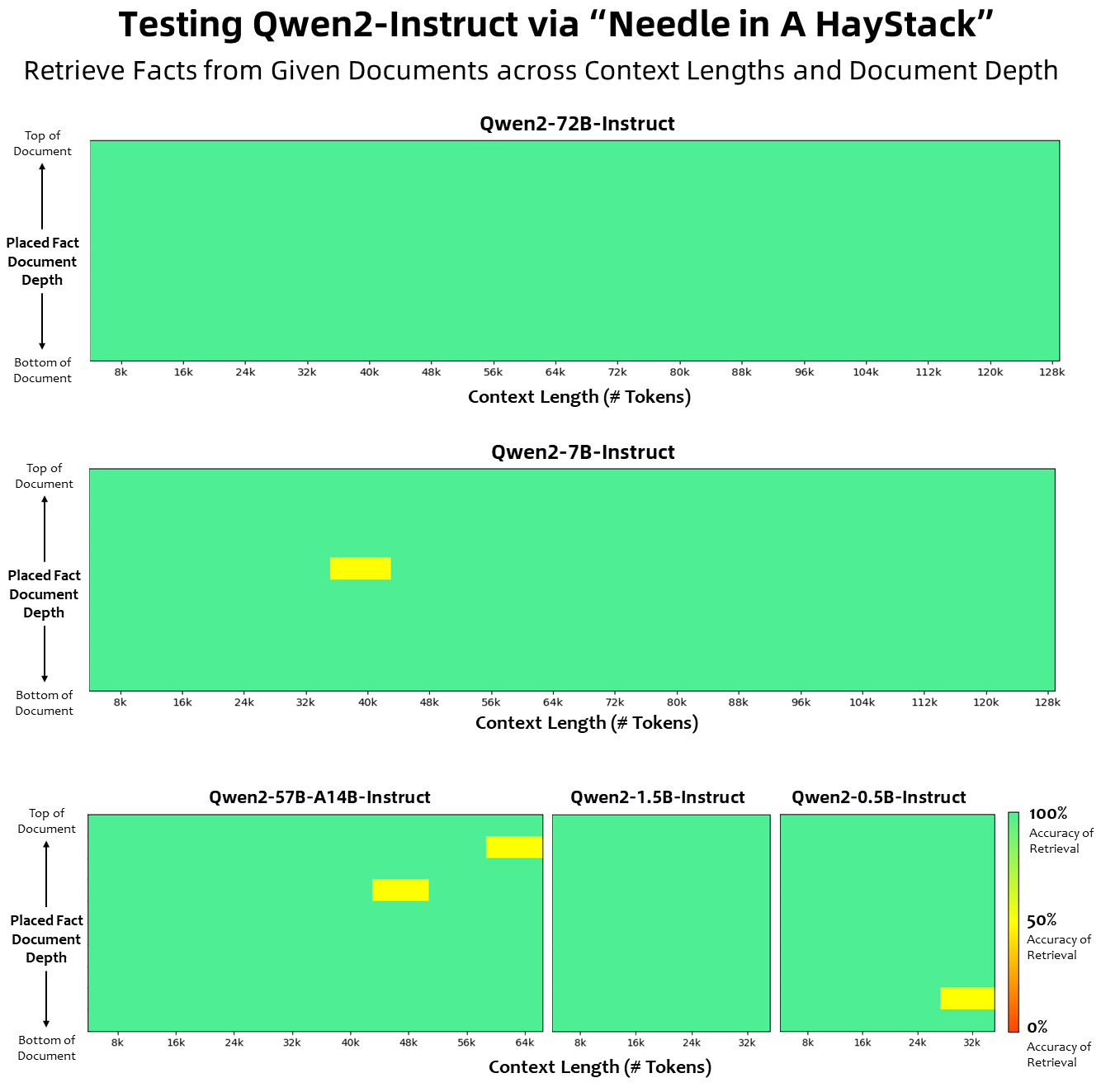
コンテキスト長に関しては、すべての基本言語モデルが 32K トークンのコンテキスト長データで事前トレーニングされており、PPL 評価では最大 128K まで満足のいく外挿機能が確認されました。ただし、命令調整モデルの場合、PPL 評価だけでは満足できません。モデルが長いコンテキストを正しく理解してタスクを完了できる必要があります。表には、Needlein a Haystack タスクの評価によって評価された、命令調整モデルのコンテキスト長機能がリストされています。 YARN で強化すると、Qwen2-7B-Instruct モデルと Qwen2-72B-Instruct モデルの両方が優れた機能を示し、最大 128K トークンまでのコンテキスト長を処理できることは注目に値します。
私たちは、多言語機能を強化するために、英語と中国語以外の複数の言語をカバーする事前トレーニングおよび命令調整されたデータセットの量と質を向上させるために多大な努力を払ってきました。大規模な言語モデルには他の言語に一般化する固有の機能がありますが、私たちはトレーニングに他の 27 言語を含めることを明確に強調しています。
地域言語 西ヨーロッパ ドイツ語、フランス語、スペイン語、ポルトガル語、イタリア語、オランダ語 東および中央ヨーロッパ ロシア語、チェコ語、ポーランド語 中東アラビア語、ペルシア語、ヘブライ語、トルコ語 東アジア 日本語、韓国語 東南アジア ベトナム語、タイ語、インドネシア語、マレー語、ラオス語、ビルマ語、セブアノ語、クメール語、タガログ語 南アジアのヒンディー語、ベンガル語、ウルドゥー語さらに、多言語評価でよく発生するトランスコーディングの問題の解決にも多大な労力を費やしました。したがって、この現象を処理するモデルの能力が大幅に向上しました。通常、言語間のコード切り替えを引き起こすキューを使用した評価により、関連する問題が大幅に減少することが確認されました。
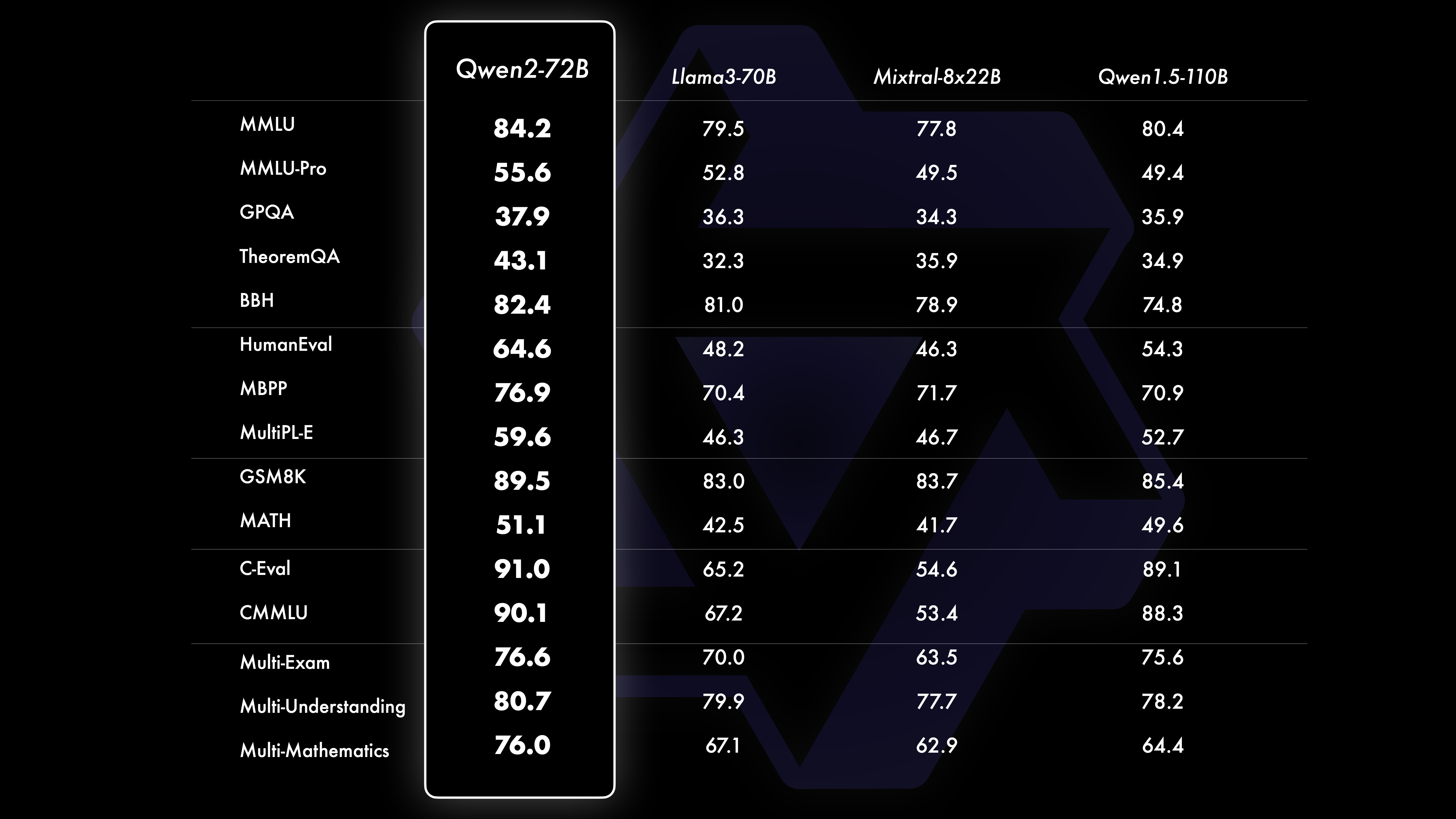
パフォーマンス比較テストの結果は、大規模モデル (70B+ パラメーター) のパフォーマンスが Qwen1.5 と比較して大幅に向上していることを示しています。今回のテストは大型モデルQwen2-72Bを中心に実施しました。基本言語モデルに関しては、自然言語理解、知識獲得、プログラミング能力、数学的能力、多言語能力などの観点から、Qwen2-72B と現在の最高のオープンモデルのパフォーマンスを比較しました。慎重に選択されたデータセットと最適化されたトレーニング方法のおかげで、Qwen2-72B は Llama-3-70B などの主要なモデルを上回り、より少ないパラメーター数で前世代の Qwen1.5- をも上回ります。
広範囲にわたる大規模な事前トレーニングの後、クウェンの知能をさらに強化し、人間に近づけるために事後トレーニングを実行します。このプロセスにより、コーディング、数学、推論、指示に従い、多言語理解などの分野でモデルの機能がさらに向上します。さらに、モデルの出力を人間の価値観に合わせて調整し、それが有用で、正直で、無害であることを保証します。トレーニング後のフェーズは、スケーラブルなトレーニングと最小限の人による注釈の原則に基づいて設計されています。具体的には、数学のリジェクトサンプリング、コーディングと命令フォローの実行フィードバック、クリエイティブライティングの逆翻訳など、さまざまな自動調整戦略を通じて、高品質で信頼性があり、多様で創造的なプレゼンテーションデータと嗜好データを取得する方法を研究します。 、ロールプレイングのスケーラブルな監督など。トレーニングに関しては、教師あり微調整、報酬モデル トレーニング、オンライン DPO トレーニングを組み合わせて使用します。また、調整税を最小限に抑えるために、新しいオンライン マージ オプティマイザーも採用しています。以下の表に示すように、これらの取り組みを組み合わせることで、モデルの機能とインテリジェンスが大幅に向上します。
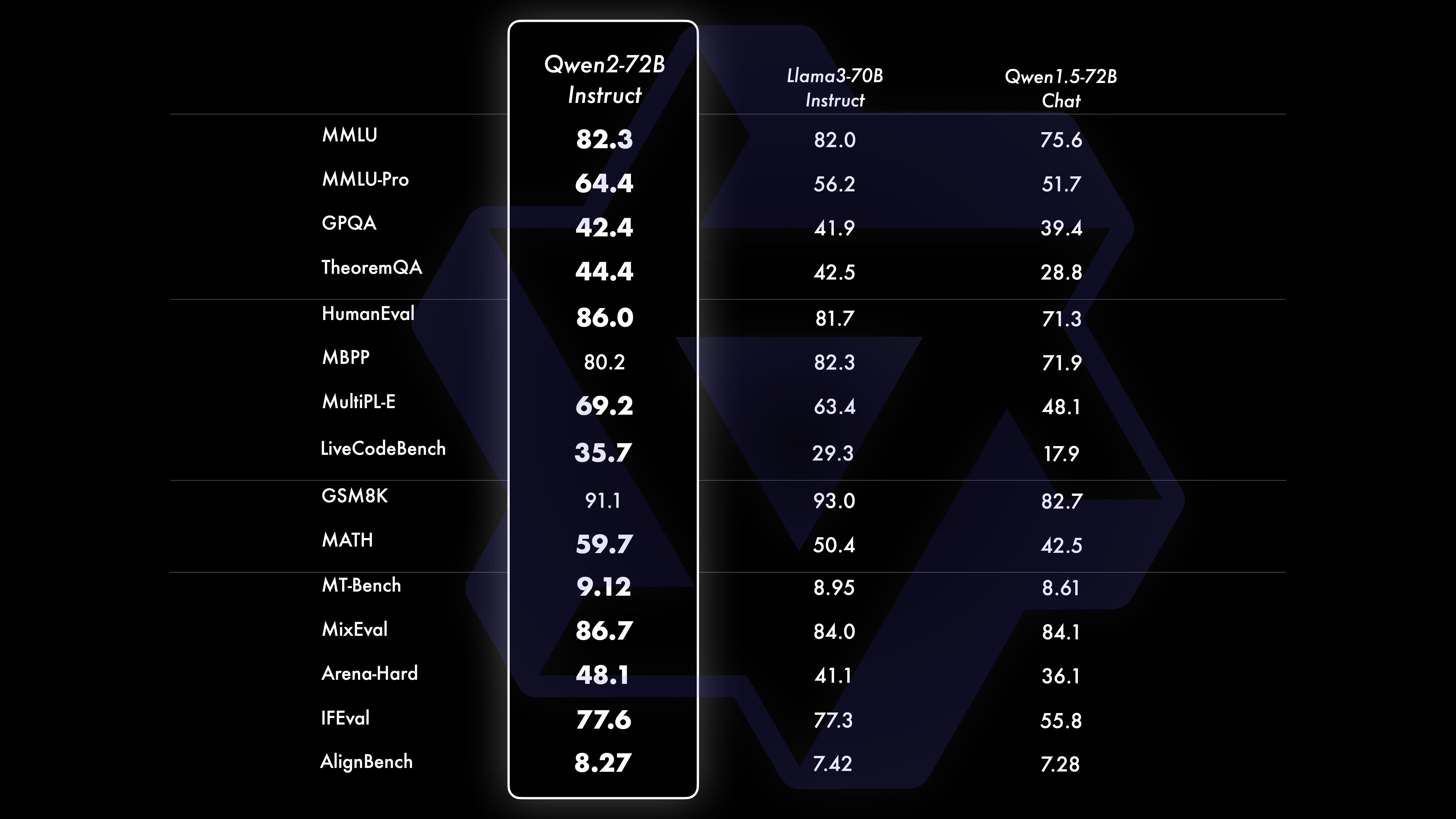
さまざまな分野の 16 のベンチマークをカバーして、Qwen2-72B-Instruct の総合的な評価を実施しました。 Qwen2-72B-Instruct は、より優れた能力の獲得と人間の価値観との一貫性のバランスをとります。具体的には、Qwen2-72B-Instruct はすべてのベンチマークで Qwen1.5-72B-Chat を大幅に上回り、Llama-3-70B-Instruct と比較しても競争力のあるパフォーマンスを達成しています。
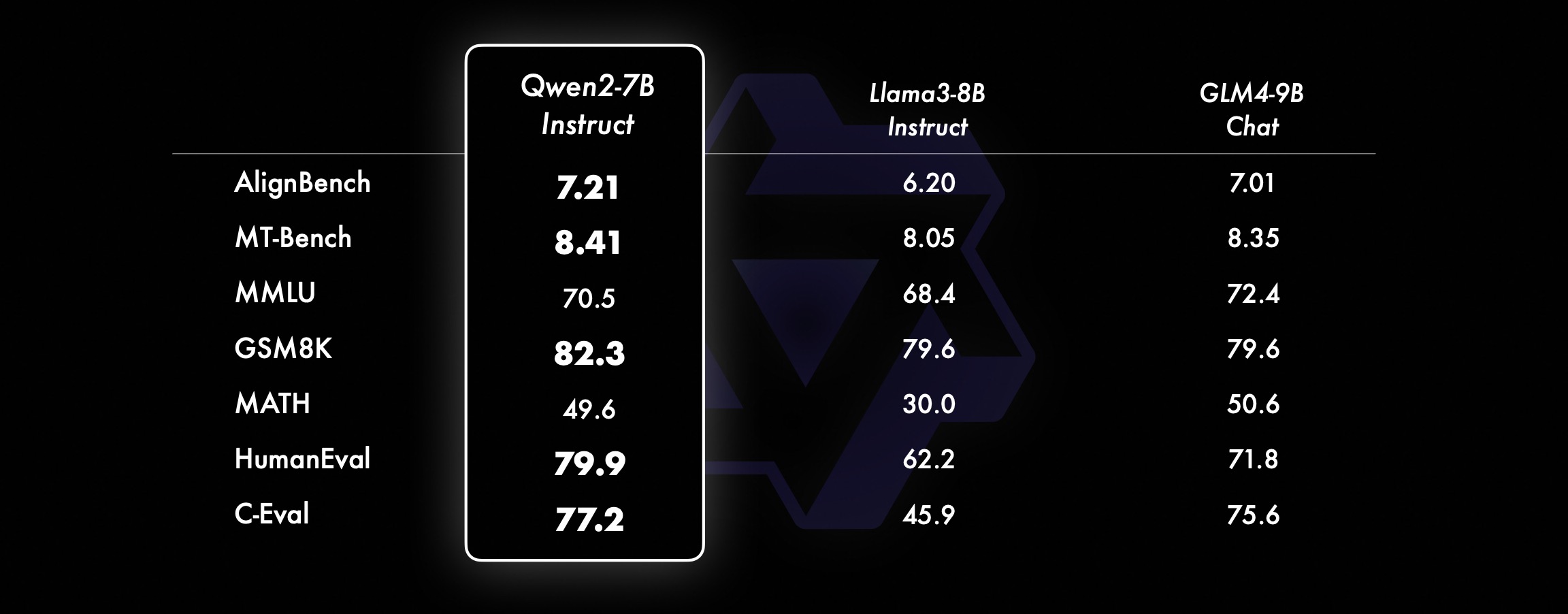
小型モデルでは、Qwen2 モデルは同様の、さらに大型の SOTA モデルよりも優れたパフォーマンスを発揮します。リリースされたばかりの SOTA モデルと比較して、Qwen2-7B-Instruct はさまざまなベンチマーク テスト、特にエンコーディングと中国語関連のインジケーターで依然として利点を示しています。
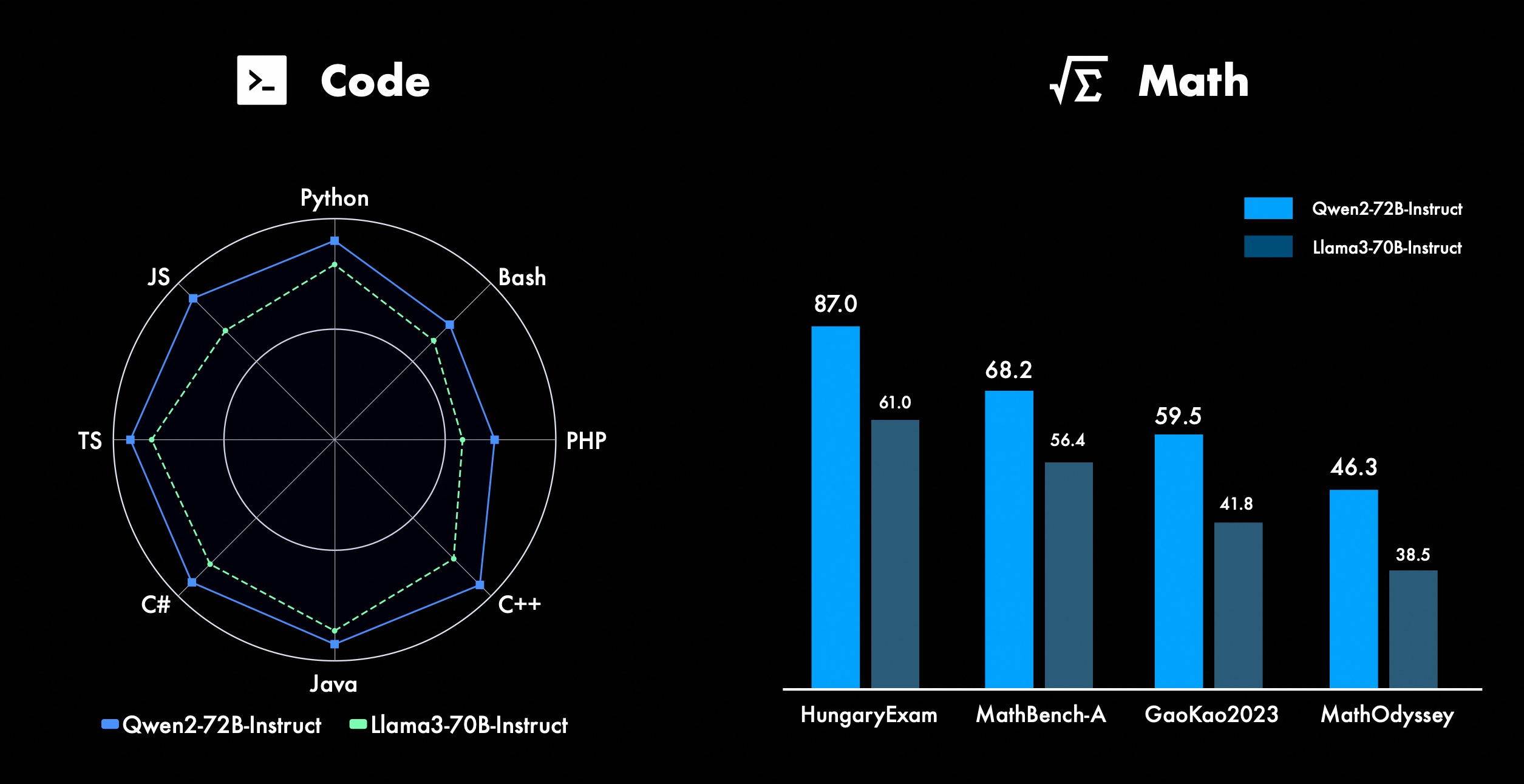
私たちは Qwen の高度な機能、特にコーディングと数学の改善に常に取り組んでいます。コーディングの面では、CodeQwen1.5 のコード トレーニングの経験とデータをうまく統合し、その結果 Qwen2-72B-Instruct がさまざまなプログラミング言語で大幅な改善を達成しました。数学では、Qwen2-72B-Instruct は、広範で高品質のデータセットを活用することで数学的問題を解決する強化された機能を示します。
Qwen2 では、すべての命令調整モデルは 32k の長さのコンテキストでトレーニングされ、YARN やデュアル チャンク アテンションなどの技術を使用してより長いコンテキスト長に外挿されます。
下の図は、Haystack の Needle でのテスト結果を示しています。注目に値するのは、Qwen2-72B-Instruct が 128k コンテキストでの情報抽出タスクを完全に処理できるため、リソースが十分な場合に使用できることです。 . の場合、長いテキスト タスクを処理する場合の最初の選択肢になります。
さらに、シリーズの他のモデルの優れた機能にも注目する価値があります。Qwen2-7B-Instruct は最大 128k のコンテキストをほぼ完全に処理し、Qwen2-57B-A14B-Instruct は最大 64k のコンテキストを管理します。より小さいモデルは 32k コンテキストをサポートします。
長いコンテキスト モデルに加えて、最大 100 万個のタグを含むドキュメントを効率的に処理するためのプロキシ ソリューションをオープンソース化しました。詳細については、このトピックに関する専用のブログ投稿を参照してください。
以下の表は、多言語の安全でないクエリの 4 つのカテゴリ (違法行為、詐欺、ポルノ、私的暴力) に対して大規模モデルによって生成された有害な応答の割合を示しています。テスト データは Jailbreak から取得され、評価のために複数の言語に翻訳されます。 Llama-3 は多言語キューを効率的に処理できないことが判明したため、比較には含めませんでした。有意性検定 (P_value) により、Qwen2-72B-Instruct モデルのセキュリティ パフォーマンスは GPT-4 と同等であり、Mistral-8x22B モデルよりも大幅に優れていることがわかりました。
言語 違法行為 詐欺 ポルノグラフィー プライバシー暴力 GPT-4 Mistral-8x22BQwen2-72B-GuidanceGPT-4 Mistral-8x22BQwen2-72B-GuidanceGPT-4 Mistral-8x22BQwen2-72B-Guidance GPT-4 Mistral-8x22BQwen2-72B-Guide 中国語0%13%0 %0%17%0%43%47%53%0%10%0%英語0%7%0%0%23% 0%37%67%63%0%27%3%売掛金0%13%0% 0%7%0%15%26%15%3%13%0%西文0%7%0%3 %0%0%48%64%50%3%7%3%フランス0%3%0% 3%3%7%3%19%7%0%27%0%Ke0%4%0%3 %8%4%17%29%10%0%26%4%ポイント0%7%0%3% 7%3%47%57%47%4%26%4%日0%10%0%7 %23%3%13%17%10%13%7%7%六0%4%0%4% 11%0%22%26%22%0%0%0%平均0%8%0% 3%11%2%27%39%31%3%16%2% 開発には Qwen2 を使用します現在、ハグフェイスとモデルスコープでは全モデルを公開しておりますので、詳しい使用方法や各モデルの特徴、性能などについてはモデルカードをご覧ください。
長い間、多くの友人が微調整 (Axolotl、Llama-Factory、Firefly、Swift、XTuner)、定量化 (AutoGPTQ、AutoAWQ、Neural Compressor)、展開 (vLLM、SGL、SkyPilot、 TensorRT-LLM、OpenVino、TGI)、API プラットフォーム (Together、Fireworks、OpenRouter)、ローカル実行 (MLX、Llama.cpp、Ollama、LM Studio)、エージェントおよび RAG フレームワーク (LlamaIndex、CrewAI、OpenDevin)、評価 (LMSys、 OpenCompass、Open LLM Leaderboard)、モデルトレーニング(Dolphin、Openbuddy)など。サードパーティのフレームワークで Qwen2 を使用する方法については、それぞれのドキュメントと公式ドキュメントを参照してください。

私たちが言及しなかった Qwen に貢献したチームや個人は数多くあります。私たちは彼らのサポートに心から感謝しており、私たちの協力がオープンソース AI コミュニティでの研究開発を促進することを願っています。
ライセンス今回はモデルの権限を別のものに変更します。 Qwen2-72B とその命令チューニング モデルは依然としてオリジナルの Qianwen ライセンスを使用していますが、Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B を含む他のすべてのモデルは Apache2.0 に切り替えられていると考えられます。私たちのモデルをコミュニティにさらに公開することで、世界中で Qwen2 の応用と商業化が加速できると考えています。
Qwen2 の次は何でしょうか?私たちは、モデル拡張と最近のデータ拡張をさらに調査するために、より大きな Qwen2 モデルをトレーニングしています。さらに、Qwen2 言語モデルをマルチモーダルに拡張し、視覚情報と音声情報を理解できるようにします。近い将来、私たちはオープンソース AI を加速するために新しいモデルをオープンソース化し続けます。乞うご期待!
引用Qwen2に関するテクニカルレポートを近日公開する予定です。引用は大歓迎です!
@article{qwen2、付録基本言語モデルの評価基本モデルの評価は、主に自然言語理解、一般的な質問応答、コーディング、数学、科学的知識、推論、多言語機能などのモデルのパフォーマンスに焦点を当てます。
評価されるデータセットには次のものが含まれます。
英語タスク: MMLU (5 回)、MMLU-Pro (5 回)、GPQA (5 回)、Theorem QA (5 回)、BBH (3 回)、HellaSwag (10 回)、Winogrande (5 回)、TruthfulQA ( 0回)、ARC-C(25回)
コーディングタスク: EvalPlus (0 ショット) (HumanEval、MBPP、HumanEval+、MBPP+)、MultiPL-E (0 ショット) (Python、C++、JAVA、PHP、TypeScript、C#、Bash、JavaScript)
数学タスク: GSM8K (4 回)、MATH (4 回)
中国語タスク: C-Eval (5 ショット)、CMMLU (5 ショット)
複数言語タスク: 複数の試験 (M3Exam 5 回、IndoMMLU 3 回、ruMMLU 5 回、mmMLU 5 回)、複数の理解 (BELEBELE 5 回、XCOPA 5 回、XWinograd 5 回、XStoryCloze 0 回、PAWS-X 5 回) 、複数の数学 (MGSM 8 回)、複数の翻訳 (Flores-1015 回)
Qwen2-72B パフォーマンス データセット DeepSeek-V2Mixtral-8x22BCamel-3-70BQwen1.5-72BQwen1.5-110BQwen2-72BArchitectureMinistry of EducationDenseDenseDenseDenseDense#Activated パラメータ 21B39B70B72B110B72B#パラメータ 236B140B70B72B11 0B72B 英語モーマン ·Lu 78.577.879.577.580.484.2MMLU-プロフェッショナル版-49.552。 845.849.455.6品質保証-34.336.336.335.937.9定理Q&A-35.932.329.334.943.1バイビヘイ78.978.981.065.574.88 2.4シラスワグ87.888.788.086。 7.6 大きなウィンドウ 84.885.085.383.083.585.1ARC-C70.070.768.865.969。 668.9 正直な Q&A 42.251.045.659.649.654.8 コーディング人材評価 45.746.348.246.354.364.6 マレーシア公共サービス局 73 .971.770.466.970.976.9 評価 55.054.154.852.957。 765.4 さまざまな 44.446.746.341.852.759.6 数学 GSM8K79。 283.783.079.585.489.5 数学 43.641.742.534.149.651.1 中国語 C-Assessment 81.754.665. 284.189.191.0 カナダのモントリオール大学 84.053 .467.283.588.390.1 複数の言語と複数の試験67.563.570.066.475.676.6複数の理解77.077.779.978.278.280.7複数の数学 58.862.967.161.764.476.0複数の翻訳 36.023.338.035.636.2 37.8Qwen2-57B-A14B データセット Jabba Mixtral-8x7B Instrument-1.5-34BQwen1 .5-32BQwen2-57B-A14B アーキテクチャ MoE MoE 密密MoE #Activated Parameters 12B12B34B32B14B #Parameters 52B47B34B32B57B English Moleman Lu 67.471.877.174.376.5MMLU - プロフェッショナル エディション - 41.048.344.043.0 品質保証 - 29.2 - 30.834.3 定理 Q&A - 23. 2 - 28.833.5 バイベイ ブラック 45.450.376.466.867.0 シーラスワッグ 87.186.585.985.085.2 ウィノグランド 82.581.984.981 .579.5ARC-C64.466.065.663.664.1 正直な質問と回答 46.451.153.957.457.7 コーディング人材評価 29.337.246.343。 353.0 マレーシア公共サービス - 63.965.564.271.9 評価 - 46.451 .950.457.2 さまざま - 39.03 9.538.549 .8 数学 GSM8K59.962.582.776.880.7 数学-30.841.736.143.0 中国語 C-Assessment---83.587.7 カナダ、モントリオール大学--84.882.388.5 複数の言語および複数の検査 -56.158.361.665.5 複数当事者の理解 -70.773.976.577.0複数の数学 -45.049.356.162.3複数の翻訳 -29.830.033.534.5Qwen2-7B データセット ミストラル -7B ジェマ -7B ラクダ -3-8BQwen1.5 -7BQwen2-7B# パラメータ 72 億 8 億 5,000 万 8.0B7.7B7.6B# 非 emb パラメータ 70 億 7 億 8,000 万 70 億 6 億 5,000 万 6 億 5,000 万 英語 Mohrman Lu 64.264.666.661.070.3MMLU-Pro 30.933.735.429.940.0 品質保証 24.725 .725.826。 731.8 定理 Q&A 19.221.522.114.231.1 バイベイ ブラック 56.155.157.740.262.6 シラスワガー 83.282.282.178.580.7 ウィノグランド 78.479.077.471.377.0ARC-C60.061.159 54.260.6正直な質問と回答 42.244 .844.051.154.2 コーディング人材の評価 29.337.233.536 .051.2 マレーシア公務員 51.150.653.951.665.9 評価 36.439.640.340.054.2 倍数 29.429.722.628.146.3 数学 GSM8K52.246.456.0 62.579.9 数学 13.124.320。 520.344.2 中国ヒューマン C 評価 47.443.649.574.183.2 モントリオール大学、カナダ -- 50.873.183.9 多言語複数試験 47.142.752.347.759.2 複数理解 63.358.368.667.672.0 多変量数学 26.339.136.337.357.5 複数翻訳 23.331.231 .928.431.5Qwen2 - 0.5B および Qwen2-1.5B データセット Phi-2Gemma -2B 最小 CPM Qwen1.5-1.8BQwen2-0.5BQwen2-1.5B# Emb 以外のパラメータ 2 億 5,000 万 2.0B2.4B1.3B035 百万 1.3 B Mohrman Lu 52.742.353.546.845.456.5MMLU-Professional-15.9--14.721.8 定理Q&A----8.915.0 人材評価 47.622.050.020.122.031.1 マレーシア公務員局 55.029.247.318.022.037 .4GSM8K57.217.753.838.436.558.5 数学 3.511.810.210.110。 721.7 バイビ ブラック 43.435.236.924.228.437。 2 シーラ スワッグ 73.171.468.361.449.366.6 ウィノグランド 74.466.8 -60.356.866.2ARC -C61.148.5-37.931.543.9 正直な Q&A 44.533.1-39.439.745.9C - 評価 23.428.05 1.159.758.270.6 モントリオール大学、カナダ 24.2 - 51.157.855.170.3 命令チューニング モデルの評価 Qwen2-72B - ガイド付きデータセット Camel - 3-70B - ガイダンス Qwen1.5-72B - チャット Qwen2-72B - ガイダンス 英語 Mohr Man Lu 82.075.682.3MMLU - プロフェッショナル エディション 56.251。 764.4 品質保証 41.939.442.4 定理 Q&A 42.528.844.4MT - ベンチ8.958.619.12 アリーナ - ハード 41.136.148.1 IFEval (Prompt Strict Access) 77.355.877.6 コーディング人材評価 81.771.386.0 公共サービス マレーシア82.371.980.2 複数の 63.448.169.2 の評価75.266.979.0 ライブ コード テスト 29.317.935.7 数学 GSM 8K93.082.7 91.1 数学 50.442.559.7 中国語 C-Evaluation 61.676.183.8AlignBench7.427.288.27Qwen2-57B-A14B-命令データセットミックスtral-8x7B-Instruct-v0.1Yi-1.5 -34B-ChatQwen1.5-32B-ChatQwen2- 57B-A14B - ガイダンス アーキテクチャ 教育省 密 密 教育省 #アクティブ化パラメータ 12B34B32B14B #パラメータ 47B34B32B57B English Mohr Man Lu 71.476.874.875.4MMLU - Professional Edition 43.352.346.452.8 品質保証-30.834.3定理の質問と回答-30.933.1MT -Bench8.308.508.308.55コーディング人材評価45.175.268.379.9公共サービスマレーシア59.574.667.970.9さまざまな-50.766.4評価48.5-63.671.6コード テスト 12.3-15.225.5 数学 GSM8K65.790.283.679.6 数学 30.750.142.449.1 中国語 C-評価--76.780.5AlignBench5.707.207.197.36Qwen2-7B-ガイド データセット Camel-3-8B-Guide .5-9B -チャット GLM-4- 9B-チャット Qwen1.5-7B-チャット Qwen2-7B-ガイド 英語 Mohrman Lu 68.469.572.459.570.5MMLU-Pro 41.0--29.144.1 品質保証 34.2--27.825.3 定理 Q&A 23.0- -14.125 .3MT-Bench8.058.208.357.608.41 コーディング人道的 62.266.571.846.379.9 公共サービス マレーシア 67.9--48.967.2 複数 48.5--27.259.1 評価 60.9--44.870.3 ライブコードテスト 17.3-- 6.026。 6 数学 GSM8K79.684.879.660.382.3 数学 30.047.750.623.249.6 中国語 C-評価 45.9-75.667.377.2 AlignBench6.206.907.016.207.21 Qwen2-0.5B-Instruct および Qwen2-1.5B-InstructデータセットQwen1- 0.5B-チャット Qwen2-0.5B-ガイド Qwen1.5-1.8B-チャット Qwen2-1.5B-ガイド Morman Lu35.037.943.752.4 人材評価 9.117.125.037.8GSM8K11.340.135.361.6C-評価 37.245.255.3 63.8IFEval (厳密なアクセスのプロンプト) 14.620.016.829.0 コマンドはモデルの多言語機能を調整しますQwen2 命令チューニング モデルを他の最近の LLM と、いくつかの言語間のオープン ベンチマークおよび人間による評価で比較します。ベースラインとして、2 つの評価データセットの結果を示します。
okapi の M-MMLU: 多言語の一般知識評価 (評価には ar、de、es、fr、it、nl、ru、uk、vi、zh のサブセットを使用します) MGSM: ドイツ語、英語、スペイン語、フランス語、数学の評価用日本語、ロシア語、タイ語、中国語、ブラジル語結果は各ベンチマークの言語間で平均化され、次のようになります。
例示的な M-MMLU (5 ショット) MGSM (0 ショット、CoT) 独自の LLM GPT-4-061378.087.0GPT-4-Turbo-040979.390.5GPT-4o-051383.289.6 Claude-3-works- 2024022980.191.0 claude-3 -sonnet-2024022971.085.6 オープンソース LL.M コマンド-r-plus-110b65.563.5Qwen1.5-7B-チャット 50.037.0Qwen1.5-32B-チャット 65.065.0Qwen1.5 -72B-チャット 68.471.7Qwen2-7B -ガイド 60.057.0Qwen2-57B-A14B-ガイド 68.074.0Qwen2-72B-ガイド 78.086.6手動評価では、10 言語 (ar、es、fr、ko、th、vi、 pt、id、ja、および ru (スコア範囲は 1 ~ 5):
モデル売掛金スペイン語フランス語 Corri 6 ポイント ID Jiaru 平均 Claude-3-Works-2024.314.234.234.013.984.094.403.854.254.15GPT-4o-05133.554.264.164.404.094.143.894.3。 724.324.09 GPT-4-ターボ- 04093.444.084.194.244.113.843.864.093.684.273.98Qwen2-72B-ガイド 3.864.104.014.143.753.913.973.833.634.153.93GPT-4-06133.5 .943.873.833.953.553.773.063.633.71GPT-3.5-ターボ-11062.524。 073.472.373.382.903.373.562.753.243.16タスクの種類ごとにグループ化した結果は次のとおりです。
モデルの知識の作成 数学GPT-4-06133.424。 32GPT-3.5-ターボ-11063.373.673.892.97これらの結果は、Qwen2 命令チューニング モデルの強力な多言語機能を示しています。
アリババのオープンソース Qwen2 シリーズ モデルは、パフォーマンスと多言語機能が大幅に向上しており、オープンソース AI コミュニティに重要な貢献をしています。今後、Qwen2 は開発を継続し、モデル規模とマルチモーダル機能をさらに拡張していく予定であり、期待に値します。