bitnet.cpp는 1비트 LLM(예: BitNet b1.58)을 위한 공식 추론 프레임워크입니다. CPU에서 1.58비트 모델의 빠르고 무손실 추론을 지원하는 최적화된 커널 제품군을 제공합니다(다음에는 NPU 및 GPU 지원 예정).
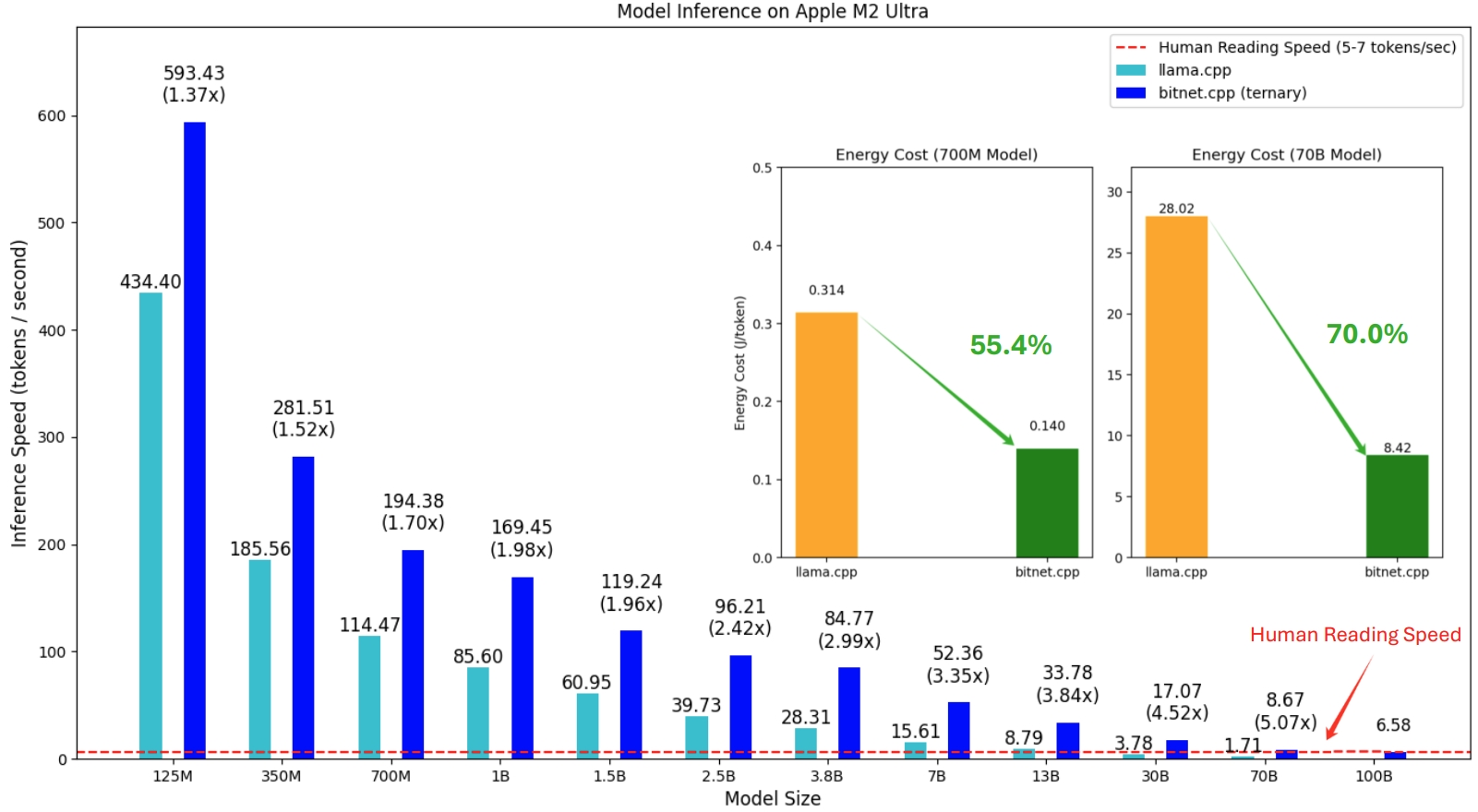
bitnet.cpp의 첫 번째 릴리스는 CPU에 대한 추론을 지원하는 것입니다. bitnet.cpp는 ARM CPU에서 1.37x ~ 5.07x 의 속도 향상을 달성하며 더 큰 모델에서는 더 큰 성능 향상을 경험합니다. 또한 에너지 소비를 55.4% 에서 70.0% 까지 줄여 전반적인 효율성을 더욱 향상시킵니다. x86 CPU에서 속도 향상 범위는 2.37x ~ 6.17x 이며 에너지 감소는 71.9% ~ 82.2% 입니다. 또한 bitnet.cpp는 단일 CPU에서 100B BitNet b1.58 모델을 실행하여 사람이 읽는 것과 비슷한 속도(초당 5-7개 토큰)를 달성하여 로컬 장치에서 LLM을 실행할 가능성을 크게 향상시킵니다. 자세한 내용은 기술 보고서를 참조하세요.


테스트된 모델은 bitnet.cpp의 추론 성능을 보여주기 위해 연구 맥락에서 사용되는 더미 설정입니다.
Apple M2에서 BitNet b1.58 3B 모델을 실행하는 bitnet.cpp의 데모:
2024/10/21 1비트 AI 인프라: 1.1부, 빠르고 무손실 BitNet b1.58 CPU 추론
2024년 10월 17일 bitnet.cpp 1.0이 출시되었습니다.
2024/03/21 1비트 LLM 시대__Training_Tips_Code_FAQ
2024/02/27 1비트 LLM 시대: 모든 대형 언어 모델은 1.58비트에 있습니다.
2023/10/17 BitNet: 대규모 언어 모델을 위한 1비트 변환기 확장
이 프로젝트는 llama.cpp 프레임워크를 기반으로 합니다. 오픈 소스 커뮤니티에 기여해 주신 모든 저자들에게 감사의 말씀을 전하고 싶습니다. 또한 bitnet.cpp의 커널은 T-MAC에서 개척된 조회 테이블 방법론을 기반으로 구축되었습니다. 삼항 모델 이상의 일반적인 낮은 비트 LLM을 추론하려면 T-MAC를 사용하는 것이 좋습니다.
❗️ Hugging Face에서 사용할 수 있는 기존 1비트 LLM을 사용하여 bitnet.cpp의 추론 기능을 보여줍니다. 이러한 모델은 Microsoft에서 교육하거나 출시하지 않습니다. bitnet.cpp의 출시가 모델 크기 및 교육 토큰 측면에서 대규모 설정에서 1비트 LLM 개발에 영감을 주기를 바랍니다.
| 모델 | 매개변수 | CPU | 핵심 | ||
|---|---|---|---|---|---|
| I2_S | TL1 | TL2 | |||
| bitnet_b1_58-대형 | 0.7B | x86 | ✔ | ✘ | ✔ |
| 팔 | ✔ | ✔ | ✘ | ||
| bitnet_b1_58-3B | 3.3B | x86 | ✘ | ✘ | ✔ |
| 팔 | ✘ | ✔ | ✘ | ||
| Llama3-8B-1.58-100B-토큰 | 8.0B | x86 | ✔ | ✘ | ✔ |
| 팔 | ✔ | ✔ | ✘ | ||
파이썬>=3.9
cmake>=3.22
꽝>=18
C++를 사용한 데스크탑 개발
C++-Windows용 CMake 도구
윈도우용 힘내
Windows용 C++-Clang 컴파일러
LLVM 도구 집합(clang)에 대한 MS 빌드 지원
Windows 사용자의 경우 Visual Studio 2022를 설치하십시오. 설치 프로그램에서 최소한 다음 옵션을 켜십시오(이렇게 하면 CMake와 같은 필수 추가 도구도 자동으로 설치됩니다).
Debian/Ubuntu 사용자의 경우 자동 설치 스크립트를 사용하여 다운로드할 수 있습니다.
bash -c "$(wget -O - https://apt.llvm.org/llvm.sh)"
콘다 (강력히 추천)
중요한
Windows를 사용하는 경우 다음 명령에 대해 항상 VS2022용 개발자 명령 프롬프트/PowerShell을 사용해야 합니다.
저장소 복제
git clone --recursive https://github.com/microsoft/BitNet.gitcd BitNet
종속성 설치
# (권장) 새 conda 환경 생성conda create -n bitnet-cpp python=3.9 conda는 bitnet-cpp를 활성화합니다 pip 설치 -r 요구사항.txt
프로젝트 빌드
# Hugging Face에서 모델을 다운로드하고 양자화된 gguf 형식으로 변환한 후 프로젝트를 빌드합니다python setup_env.py --hf-repo HF1BitLLM/Llama3-8B-1.58-100B-tokens -q i2_s# 또는 모델을 수동으로 다운로드하여 로컬 pathhuggingface-cli 다운로드 HF1BitLLM/Llama3-8B-1.58-100B-tokens --local-dir models/Llama3-8B-1.58-100B-tokens로 실행 python setup_env.py -md 모델/Llama3-8B-1.58-100B-tokens -q i2_s
사용법: setup_env.py [-h] [--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}] [--model-dir MODEL_DIR] [ --log-dir LOG_DIR] [--양자 유형 {i2_s,tl1}] [--양자-포함]
[--사용-사전 조정됨]
추론을 실행하기 위한 환경 설정
선택적 인수:
-h, --help 이 도움말 메시지를 표시하고 종료합니다.
--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}, -hr {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3- 8B-1.58-100B-토큰}
추론에 사용되는 모델
--모델-디렉토리 MODEL_DIR, -md MODEL_DIR
모델을 저장/로드할 디렉터리
--log-dir LOG_DIR, -ld LOG_DIR
로깅 정보를 저장할 디렉터리
--퀀트 유형 {i2_s,tl1}, -q {i2_s,tl1}
양자화 유형
--퀀트-임베딩을 f16으로 양자화합니다.
--use-pretuned, -p 미리 조정된 커널 매개변수 사용# 양자화된 모델로 추론 실행python run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Daniel은 정원으로 돌아갔습니다. Mary는 부엌으로 갔습니다. Sandra Sandra는 복도로 나갔습니다. John은 침실로 돌아갔습니다. Mary는 어디에 있습니까?n답변:" -n 6 -temp 0# 출력:# Daniel은 정원으로 돌아갔습니다. 메리는 부엌으로 갔다. 산드라는 부엌으로 갔다. 산드라는 복도로 갔다. 존은 침실로 갔다. 메리는 정원으로 돌아갔습니다. 메리는 어디에 있나요?# 답변: 메리는 정원에 있습니다.
사용법: run_inference.py [-h] [-m MODEL] [-n N_PREDICT] -p PROMPT [-t THREADS] [-c CTX_SIZE] [-temp TEMPERATURE]
추론 실행
선택적 인수:
-h, --help 이 도움말 메시지를 표시하고 종료합니다.
-m 모델, --model 모델
모델 파일 경로
-n N_PREDICT, --n-N_PREDICT 예측
텍스트 생성 시 예측할 토큰 수
-p 프롬프트, --프롬프트 프롬프트
다음에서 텍스트를 생성하라는 메시지 표시
-t 스레드, --스레드 스레드
사용할 스레드 수
-c CTX_SIZE, --ctx-size CTX_SIZE
프롬프트 컨텍스트의 크기
-온도 온도, --온도 온도
생성된 텍스트의 무작위성을 제어하는 하이퍼파라미터인 온도우리는 모델을 제공하는 추론 벤치마크를 실행하기 위한 스크립트를 제공합니다.
usage: e2e_benchmark.py -m MODEL [-n N_TOKEN] [-p N_PROMPT] [-t THREADS] Setup the environment for running the inference required arguments: -m MODEL, --model MODEL Path to the model file. optional arguments: -h, --help Show this help message and exit. -n N_TOKEN, --n-token N_TOKEN Number of generated tokens. -p N_PROMPT, --n-prompt N_PROMPT Prompt to generate text from. -t THREADS, --threads THREADS Number of threads to use.
각 인수에 대한 간략한 설명은 다음과 같습니다.
-m , --model : 모델 파일의 경로입니다. 스크립트를 실행할 때 제공해야 하는 필수 인수입니다.
-n , --n-token : 추론 중에 생성할 토큰 수입니다. 기본값이 128인 선택적 인수입니다.
-p , --n-prompt : 텍스트 생성에 사용할 프롬프트 토큰 수입니다. 이는 기본값이 512인 선택적 인수입니다.
-t , --threads : 추론을 실행하는 데 사용할 스레드 수입니다. 기본값이 2인 선택적 인수입니다.
-h , --help : 도움말 메시지를 표시하고 종료합니다. 사용법 정보를 표시하려면 이 인수를 사용하십시오.
예를 들어:
python utils/e2e_benchmark.py -m /path/to/model -n 200 -p 256 -t 4
이 명령은 /path/to/model 에 있는 모델을 사용하여 추론 벤치마크를 실행하고 4개의 스레드를 활용하여 256개 토큰 프롬프트에서 200개 토큰을 생성합니다.
공개 모델에서 지원하지 않는 모델 레이아웃의 경우 지정된 모델 레이아웃으로 더미 모델을 생성하고 시스템에서 벤치마크를 실행하는 스크립트를 제공합니다.
python utils/generate-dummy-bitnet-model.py models/bitnet_b1_58-large --outfile models/dummy-bitnet-125m.tl1.gguf --outtype tl1 --model-size 125M# 생성된 모델로 벤치마크를 실행하고 다음을 사용합니다. -m은 모델 경로를 지정하고, -p는 처리된 프롬프트를 지정하고, -n은 생성할 토큰 수를 지정합니다.python utils/e2e_benchmark.py -m models/dummy-bitnet-125m.tl1.gguf -p 512 -n 128