kotaemon
v0.7.6
문서 채팅을 위한 깔끔하고 사용자 정의 가능한 오픈 소스 RAG UI입니다. 최종 사용자와 개발자 모두를 염두에 두고 제작되었습니다.
라이브 데모 | 온라인 설치 | 사용자 가이드 | 개발자 가이드 | 피드백 | 연락하다
이 프로젝트는 문서에 대한 QA를 수행하려는 최종 사용자와 자체 RAG 파이프라인을 구축하려는 개발자 모두를 위한 기능적 RAG UI 역할을 합니다.
+------------------------------------------------- --------------+| 최종 사용자: `kotaemon`으로 구축된 앱을 사용하는 사용자입니다. || (위 데모와 같은 앱을 사용합니다) || +------------------------------------------------- ---------------+ || | 개발자 : `kotaemon`으로 만든 사람들. | || | (프로젝트 어딘가에 `import kotaemon`이 있습니다.) | || | +------------------------------------------------- ---+ | || | | 기여자: '코타에몬'을 더 좋게 만드는 사람들. | | || | | (이 저장소에 PR을 작성합니다.) | | || | +------------------------------------------------- ---+ | || +------------------------------------------------- ---------------+ |+------------------- ------------------+
Clean & Minimalistic UI : RAG 기반 QA를 위한 사용자 친화적인 인터페이스입니다.
다양한 LLM 지원 : LLM API 공급자(OpenAI, AzureOpenAI, Cohere 등) 및 로컬 LLM( ollama 및 llama-cpp-python 통해)과 호환됩니다.
쉬운 설치 : 빠르게 시작할 수 있는 간단한 스크립트입니다.
RAG 파이프라인용 프레임워크 : 자체 RAG 기반 문서 QA 파이프라인을 구축하기 위한 도구입니다.
사용자 정의 가능한 UI : Gradio로 구축된 제공된 UI를 통해 RAG 파이프라인이 작동하는 모습을 확인하세요.
Gradio 테마 : 개발에 Gradio를 사용하는 경우 여기에서 Kotaemon-Gradio-theme 테마를 확인하세요.
나만의 문서 QA(RAG) 웹 UI 호스팅 : 다중 사용자 로그인을 지원하고, 비공개/공개 컬렉션으로 파일을 정리하고, 다른 사람들과 즐겨 사용하는 채팅을 공동 작업하고 공유하세요.
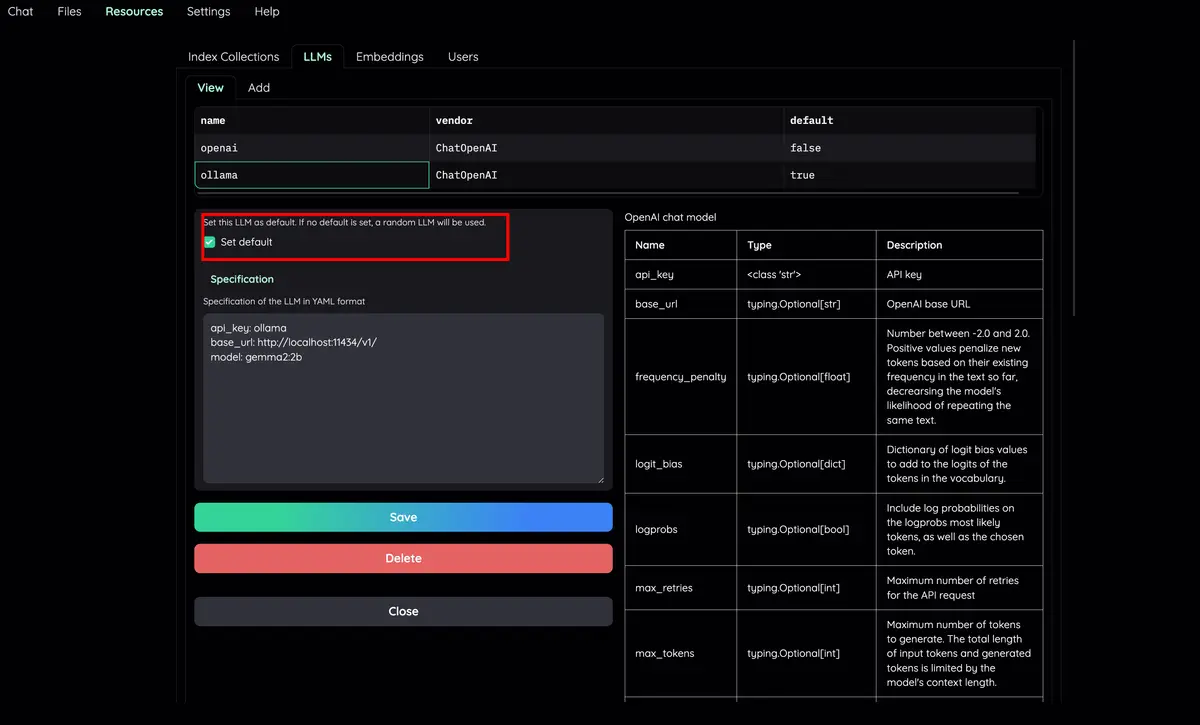
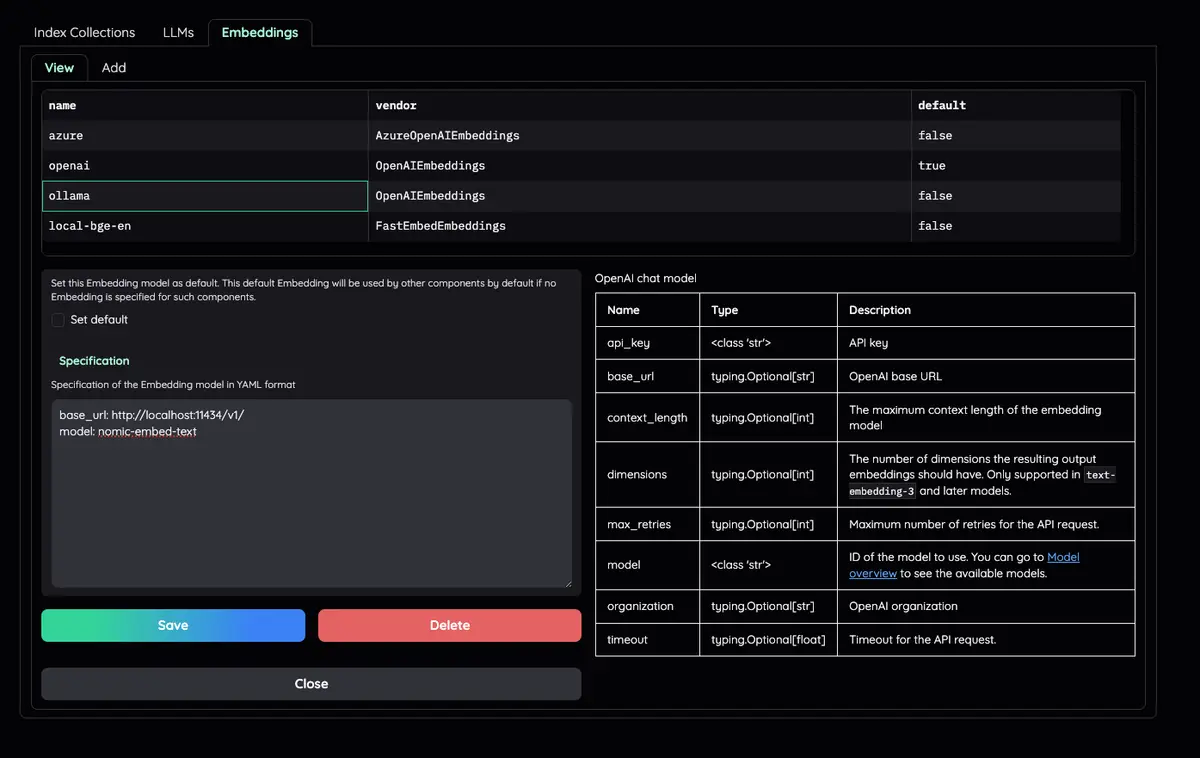
LLM 및 임베딩 모델 구성 : 로컬 LLM 및 인기 있는 API 공급자(OpenAI, Azure, Ollama, Groq)를 모두 지원합니다.
하이브리드 RAG 파이프라인 : 최상의 검색 품질을 보장하기 위해 하이브리드(전체 텍스트 및 벡터) 검색기와 순위 재지정 기능을 갖춘 정상적인 기본 RAG 파이프라인입니다.
멀티모달 QA 지원 : 그림과 표를 지원하여 여러 문서에 대한 질문 답변을 수행합니다. 다중 모달 문서 구문 분석을 지원합니다(UI에서 선택 가능한 옵션).
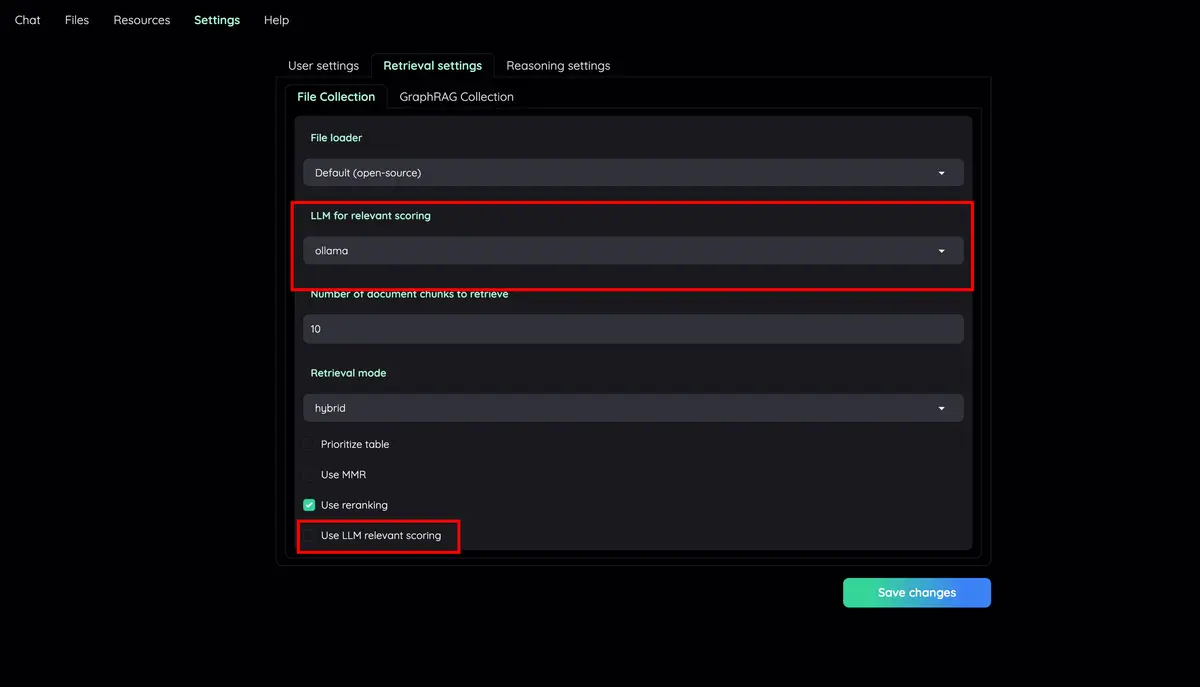
문서 미리보기가 포함된 고급 인용 : 기본적으로 시스템은 LLM 답변의 정확성을 보장하기 위해 자세한 인용을 제공합니다. 강조 표시가 있는 브라우저 내 PDF 뷰어 에서 직접 인용(관련 점수 포함)을 확인하세요. 검색 파이프라인이 관련성이 낮은 기사를 반환할 때 경고합니다.
복잡한 추론 방법 지원 : 질문 분해를 사용하여 복잡한/다중 홉 질문에 답변합니다. ReAct , ReWOO 및 기타 에이전트를 사용하여 에이전트 기반 추론을 지원합니다.
구성 가능한 설정 UI : UI(프롬프트 포함)에서 검색 및 생성 프로세스의 가장 중요한 측면을 조정할 수 있습니다.
확장 가능 : Gradio를 기반으로 구축되었으므로 원하는 대로 UI 요소를 자유롭게 맞춤 설정하거나 추가할 수 있습니다. 또한 문서 색인화 및 검색을 위한 다양한 전략을 지원하는 것을 목표로 합니다. GraphRAG 인덱싱 파이프라인이 예로 제공됩니다.
개발자가 아니고 단지 앱을 사용하고 싶다면 따라하기 쉬운 사용자 가이드를 확인하세요. 모든 최신 기능과 버그 수정을 받으려면 최신 릴리스에서
.zip파일을 다운로드하세요.
파이썬 >= 3.10
Docker: 선택 사항(Docker와 함께 설치하는 경우)
.pdf , .html , .mhtml 및 .xlsx 문서 이외의 파일을 처리하려는 경우 구조화되지 않습니다. 설치 단계는 운영 체제에 따라 다릅니다. 링크를 방문하여 거기에 제공된 특정 지침을 따르십시오.
우리는 Docker 이미지의 lite 과 full 버전을 모두 지원합니다. full 사용하면 unstructured 추가 패키지도 설치되며 추가 파일 형식( .doc , .docx , ...)을 지원할 수 있지만 비용은 도커 이미지 크기가 더 큽니다. 대부분의 사용자에게는 대부분의 경우 lite 이미지가 잘 작동합니다.
lite 버전을 사용하려면.
도커 실행 -e GRADIO_SERVER_NAME=0.0.0.0 -e GRADIO_SERVER_PORT=7860 -p 7860:7860 -it --rm ghcr.io/cinnamon/kotaemon:main-lite
full 버전을 사용하려면.
도커 실행 -e GRADIO_SERVER_NAME=0.0.0.0 -e GRADIO_SERVER_PORT=7860 -p 7860:7860 -it --rm ghcr.io/cinnamon/kotaemon:main-full
현재 우리는 linux/amd64 및 linux/arm64 (최신 Mac용)라는 두 가지 플랫폼을 지원하고 테스트합니다. docker run 명령에 --platform 전달하여 플랫폼을 지정할 수 있습니다. 예를 들어:
# 플랫폼 linux/arm64docker로 docker를 실행하려면 run -e GRADIO_SERVER_NAME=0.0.0.0 -e GRADIO_SERVER_PORT=7860 -p 7860:7860 -it --rm --플랫폼 리눅스/arm64 ghcr.io/cinnamon/kotaemon:main-lite
모든 것이 올바르게 설정되면 http://localhost:7860/ 으로 이동하여 WebUI에 액세스할 수 있습니다.
우리는 GHCR을 사용하여 도커 이미지를 저장합니다. 모든 이미지는 여기에서 찾을 수 있습니다.
새로운 Python 환경에 필요한 패키지를 복제하고 설치합니다.
# 선택 사항 (설정 환경)conda create -n kotaemon python=3.10 conda activate kotaemon# 이 repogit 복제 복제 https://github.com/Cinnamon/kotaemoncd kotaemon pip install -e "libs/kotaemon[모두]"pip install -e "libs/ktem"
이 프로젝트의 루트에 .env 파일을 만듭니다. .env.example 템플릿으로 사용
.env 파일은 사용자가 앱을 시작하기 전에 모델을 사전 구성하려는 사용 사례를 제공하기 위해 존재합니다(예: HF 허브에 앱 배포). 이 파일은 첫 번째 실행 시 DB를 한 번만 채우는 데 사용되며 이후 실행에서는 더 이상 사용되지 않습니다.
(선택 사항) 브라우저 내 PDF_JS 뷰어를 활성화하려면 PDF_JS_DIST를 다운로드한 다음 libs/ktem/ktem/assets/prebuilt 에 추출합니다.
웹 서버를 시작합니다.
파이썬 app.py
앱이 브라우저에서 자동으로 실행됩니다.
기본 사용자 이름과 비밀번호는 모두 admin 입니다. UI를 통해 직접 추가 사용자를 설정할 수 있습니다.
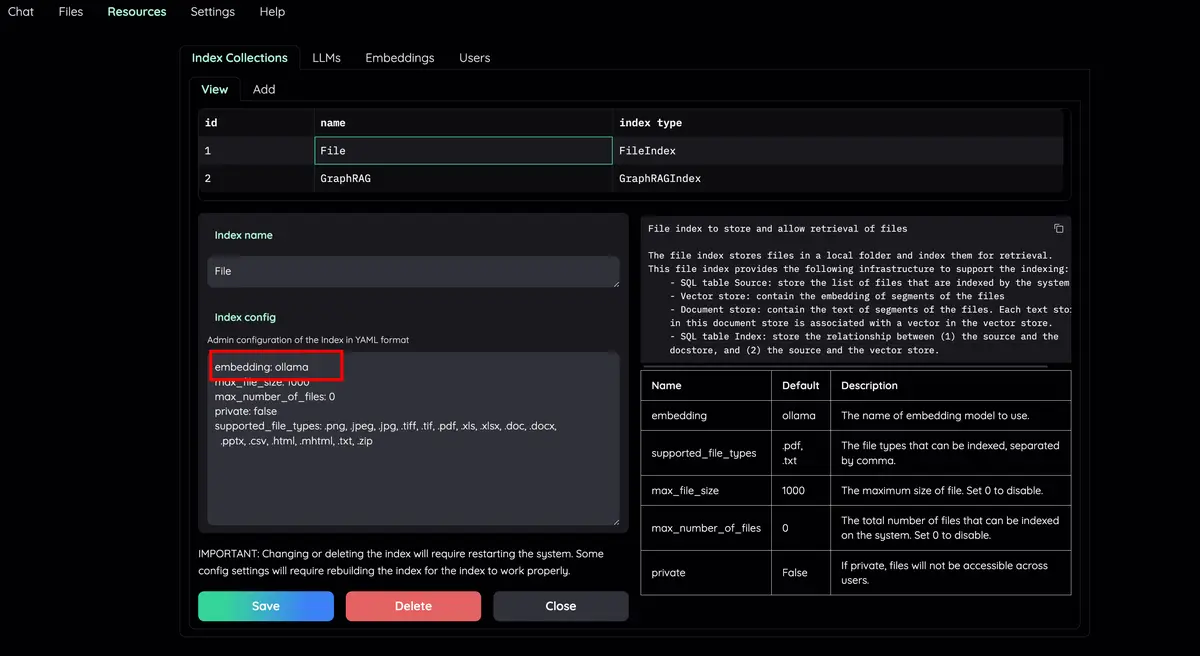
Resources 탭과 LLMs and Embeddings 확인하고 api_key 값이 .env 파일에서 올바르게 설정되었는지 확인하세요. 설정되지 않은 경우 해당 위치에서 설정할 수 있습니다.
메모
공식 MS GraphRAG 인덱싱은 OpenAI 또는 Ollama API에서만 작동합니다. 대부분의 사용자는 Kotaemon과의 직접적인 통합을 위해 NanoGraphRAG 구현을 사용하는 것이 좋습니다.
nano-GraphRAG 설치: pip install nano-graphrag
nano-graphrag 설치로 인해 버전 충돌이 발생할 수 있습니다. 이 문제를 참조하세요.
빠르게 수정하려면: pip uninstall hnswlib chroma-hnswlib && pip install chroma-hnswlib
USE_NANO_GRAPHRAG=true 환경 변수를 사용하여 Kotaemon을 시작합니다.
리소스 설정에서 기본 LLM 및 임베딩 모델을 설정하면 NanoGraphRAG에서 자동으로 인식됩니다.
Docker가 아닌 설치 : Docker를 사용하지 않는 경우 다음 명령을 사용하여 GraphRAG를 설치하십시오.
pip 설치 graphrag 미래
API KEY 설정 : GraphRAG 검색기 기능을 사용하려면 GRAPHRAG_API_KEY 환경 변수를 설정해야 합니다. 환경에서 직접 수행하거나 .env 파일에 추가하여 이 작업을 수행할 수 있습니다.
로컬 모델 및 사용자 정의 설정 사용 : 로컬 모델(예: Ollama )과 함께 GraphRAG를 사용하거나 기본 LLM 및 기타 구성을 사용자 정의하려면 USE_CUSTOMIZED_GRAPHRAG_SETTING 환경 변수를 true로 설정하세요. 그런 다음 settings.yaml.example 파일에서 설정을 조정합니다.
로컬 모델 설정을 참조하세요.
기본적으로 모든 애플리케이션 데이터는 ./ktem_app_data 폴더에 저장됩니다. 이 폴더를 백업하거나 복사하여 설치를 새 시스템으로 전송할 수 있습니다.
고급 사용자 또는 특정 사용 사례의 경우 다음 파일을 사용자 정의할 수 있습니다.
flowsettings.py
.env
flowsettings.py이 파일에는 애플리케이션 구성이 포함되어 있습니다. 여기의 예를 출발점으로 사용할 수 있습니다.
# 선호하는 문서 저장소 설정(전체 텍스트 검색 기능 포함)KH_DOCSTORE=(Elasticsearch | LanceDB | SimpleFileDocumentStore)# 선호하는 벡터 저장소 설정(벡터 기반 검색용)KH_VECTORSTORE=(ChromaDB | LanceDB | InMemory | Qdrant)# 활성화/비활성화 멀티모달 QAKH_REASONINGS_USE_MULTIMODAL=True# 새로운 추론 파이프라인을 설정하거나 기존 파이프라인을 수정합니다.KH_REASONINGS = ["ktem.reasoning.simple.FullQAPipeline","ktem.reasoning.simple.FullDecomposeQAPipeline","ktem.reasoning.react.ReactAgentPipeline","ktem .reasoning.rewoo.RewooAgentPipeline", ]
.env이 파일은 모델과 자격 증명을 구성하는 또 다른 방법을 제공합니다.
또는 LLM에 연결하는 데 필요한 정보가 포함된 .env 파일을 통해 모델을 구성할 수 있습니다. 이 파일은 응용 프로그램 폴더에 있습니다. 표시되지 않으면 새로 만들 수 있습니다.
현재 다음 공급자가 지원됩니다.
ollama OpenAI 호환 서버 사용:
llama-cpp-python 과 함께 GGUF 사용
Hugging Face Hub에서 로컬로 실행할 LLM을 검색하고 다운로드할 수 있습니다. 현재 다음 모델 형식이 지원됩니다.
ollama를 설치하고 애플리케이션을 시작하세요.
예를 들어 모델을 가져옵니다.
올라마 풀 라마3.1:8b ollama pull nomic-embed-text
웹 UI에서 모델 이름을 설정하고 기본값으로 설정합니다.
GGUF
크기가 기기 메모리보다 작고 약 2GB 정도 남겨두는 모델을 선택해야 합니다. 예를 들어, 총 RAM이 16GB이고 그 중 12GB를 사용할 수 있는 경우 최대 10GB의 RAM을 차지하는 모델을 선택해야 합니다. 더 큰 모델은 더 나은 생성을 제공하는 경향이 있지만 처리 시간도 더 많이 걸립니다.
다음은 몇 가지 권장 사항과 메모리 크기입니다.
Qwen1.5-1.8B-Chat-GGUF: 약 2GB
웹 UI에 제공된 모델 이름을 사용하여 새 LlamaCpp 모델을 추가합니다.
오픈AI
.env 파일에서 OpenAI 모델에 액세스할 수 있도록 OpenAI API 키로 OPENAI_API_KEY 변수를 설정합니다. 수정할 수 있는 다른 변수도 있으므로 상황에 맞게 자유롭게 수정하시기 바랍니다. 그렇지 않으면 기본 매개변수가 대부분의 사람들에게 작동합니다.
OPENAI_API_BASE=https://api.openai.com/v1 OPENAI_API_KEY=<여기에 OpenAI API 키>OPENAI_CHAT_MODEL=gpt-3.5-turbo OPENAI_EMBEDDINGS_MODEL=텍스트 임베딩-ada-002
Azure OpenAI
Azure 플랫폼을 통한 OpenAI 모델의 경우 Azure 엔드포인트와 API 키를 제공해야 합니다. Azure 개발 설정 방법에 따라 채팅 모델 및 포함 모델에 대한 개발 이름을 제공해야 할 수도 있습니다.
AZURE_OPENAI_ENDPOINT= AZURE_OPENAI_API_KEY= OPENAI_API_VERSION=2024-02-15-미리보기 AZURE_OPENAI_CHAT_DEPLOYMENT=gpt-35-터보 AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT=텍스트 포함-ada-002
지역 모델
여기에서 기본 파이프라인 구현을 확인하세요. 기본 QA 파이프라인의 작동 방식을 빠르게 조정할 수 있습니다.
libs/ktem/ktem/reasoning/ 에 새로운 .py 구현을 추가하고 나중에 flowssettings 에 포함하여 UI에서 활성화합니다.
libs/ktem/ktem/index/file/graph 에서 샘플 구현을 확인하세요.
(추가 지침 WIP).
우리 프로젝트는 활발하게 개발되고 있으므로 귀하의 피드백과 기여를 매우 소중하게 생각합니다. 시작하려면 기여 가이드를 참조하세요. 모든 기여자들에게 감사드립니다!