shap
v0.46.0
SHAP(SHapley Additive exPlanations) 는 기계 학습 모델의 출력을 설명하기 위한 게임 이론적 접근 방식입니다. 이는 게임 이론 및 관련 확장의 고전적인 Shapley 값을 사용하여 최적의 학점 할당을 로컬 설명과 연결합니다(자세한 내용 및 인용은 논문 참조).
SHAP는 PyPI 또는 conda-forge에서 설치할 수 있습니다.
pip 설치 모양 또는 conda install -c conda-forge shap
SHAP는 모든 기계 학습 모델의 출력을 설명할 수 있지만 트리 앙상블 방법을 위한 고속의 정확한 알고리즘을 개발했습니다(Nature MI 논문 참조). XGBoost , LightGBM , CatBoost , scikit-learn 및 pyspark 트리 모델에 대해 빠른 C++ 구현이 지원됩니다.
import xgboost
import shap
# train an XGBoost model
X , y = shap . datasets . california ()
model = xgboost . XGBRegressor (). fit ( X , y )
# explain the model's predictions using SHAP
# (same syntax works for LightGBM, CatBoost, scikit-learn, transformers, Spark, etc.)
explainer = shap . Explainer ( model )
shap_values = explainer ( X )
# visualize the first prediction's explanation
shap . plots . waterfall ( shap_values [ 0 ])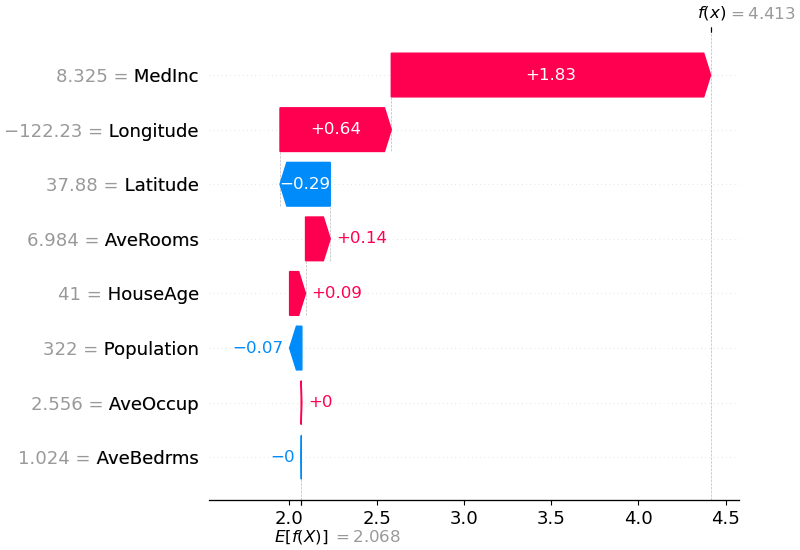
위의 설명은 모델 출력을 기본 값(우리가 전달한 훈련 데이터 세트에 대한 평균 모델 출력)에서 모델 출력으로 푸시하는 데 기여하는 각각의 기능을 보여줍니다. 예측을 높이는 기능은 빨간색으로 표시되고, 예측을 낮추는 기능은 파란색으로 표시됩니다. 동일한 설명을 시각화하는 또 다른 방법은 힘 플롯을 사용하는 것입니다(Nature BME 논문에 소개되어 있음).
# visualize the first prediction's explanation with a force plot
shap . plots . force ( shap_values [ 0 ])
위에 표시된 것과 같은 많은 힘 플롯 설명을 가져와 90도 회전한 다음 수평으로 쌓으면 전체 데이터세트에 대한 설명을 볼 수 있습니다(노트북에서 이 플롯은 대화형입니다).
# visualize all the training set predictions
shap . plots . force ( shap_values [: 500 ])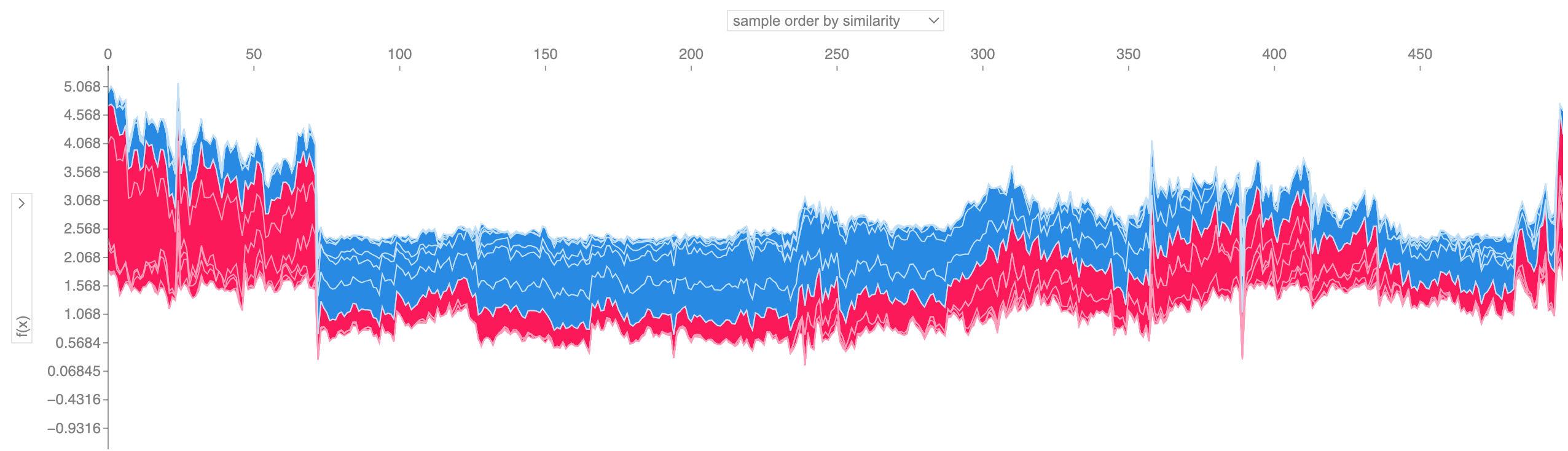
단일 기능이 모델의 출력에 어떻게 영향을 미치는지 이해하기 위해 해당 기능의 SHAP 값과 데이터 세트의 모든 예에 대한 기능 값을 플롯할 수 있습니다. SHAP 값은 모델 출력의 변화에 대한 특성의 책임을 나타내므로 아래 플롯은 위도 변화에 따른 예측 주택 가격의 변화를 나타냅니다. 단일 위도 값에서의 수직 분산은 다른 지형지물과의 상호 작용 효과를 나타냅니다. 이러한 상호 작용을 표시하는 데 도움이 되도록 다른 기능으로 색상을 지정할 수 있습니다. 전체 설명 텐서를 color 인수에 전달하면 산점도는 색상 기준으로 가장 적합한 기능을 선택합니다. 이 경우 경도를 선택합니다.
# create a dependence scatter plot to show the effect of a single feature across the whole dataset
shap . plots . scatter ( shap_values [:, "Latitude" ], color = shap_values )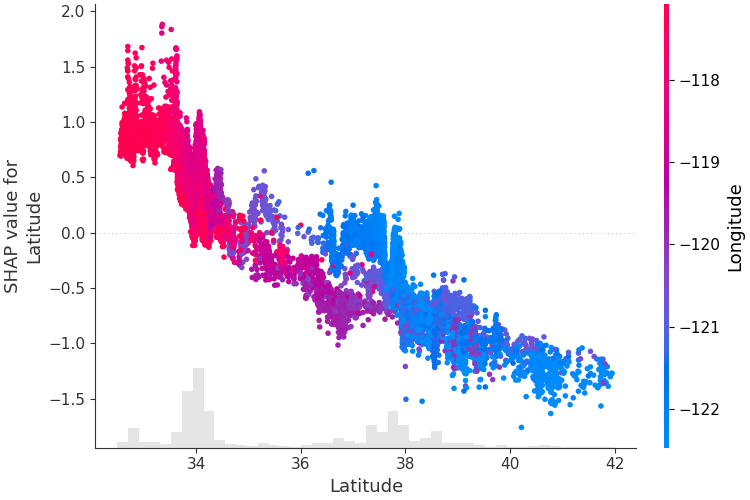
모델에 가장 중요한 기능이 무엇인지에 대한 개요를 얻으려면 모든 샘플에 대해 모든 기능의 SHAP 값을 플롯할 수 있습니다. 아래 플롯은 모든 샘플에 대한 SHAP 값 크기의 합을 기준으로 기능을 정렬하고 SHAP 값을 사용하여 각 기능이 모델 출력에 미치는 영향의 분포를 표시합니다. 색상은 특성 값(빨간색 높음, 파란색 낮음)을 나타냅니다. 예를 들어, 이는 중위소득이 높을수록 예상 주택 가격이 향상된다는 것을 보여줍니다.
# summarize the effects of all the features
shap . plots . beeswarm ( shap_values )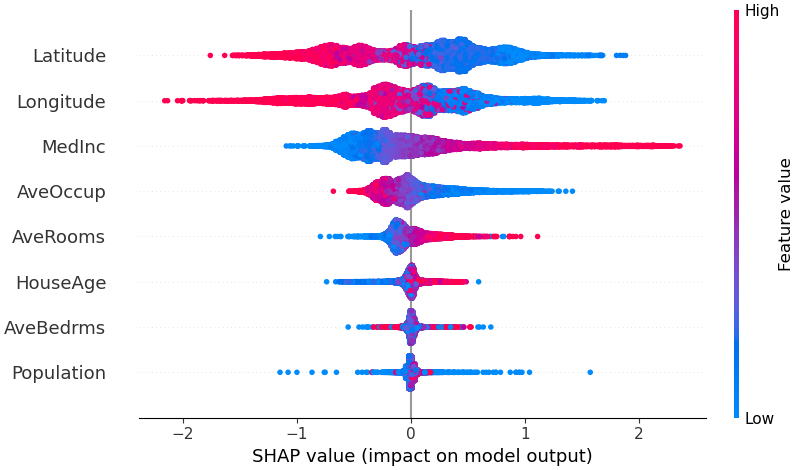
또한 각 기능에 대한 SHAP 값의 평균 절대값을 사용하여 표준 막대 그래프를 얻을 수도 있습니다(다중 클래스 출력에 대한 누적 막대 생성).
shap . plots . bar ( shap_values )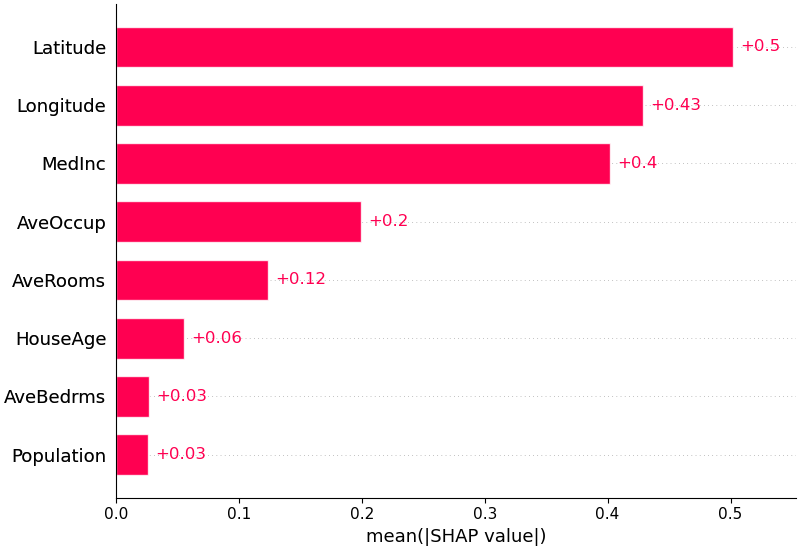
SHAP은 Hugging Face 변환기 라이브러리와 같은 자연어 모델을 구체적으로 지원합니다. 전통적인 Shapley 값에 연합 규칙을 추가함으로써 우리는 매우 적은 함수 평가를 사용하여 대규모 현대 NLP 모델을 설명하는 게임을 구성할 수 있습니다. 이 기능을 사용하는 것은 지원되는 변환기 파이프라인을 SHAP에 전달하는 것만큼 간단합니다.
import transformers
import shap
# load a transformers pipeline model
model = transformers . pipeline ( 'sentiment-analysis' , return_all_scores = True )
# explain the model on two sample inputs
explainer = shap . Explainer ( model )
shap_values = explainer ([ "What a great movie! ...if you have no taste." ])
# visualize the first prediction's explanation for the POSITIVE output class
shap . plots . text ( shap_values [ 0 , :, "POSITIVE" ])Deep SHAP은 SHAP NIPS 논문에 설명된 DeepLIFT와의 연결을 기반으로 구축된 딥 러닝 모델의 SHAP 값에 대한 고속 근사 알고리즘입니다. 여기서의 구현은 단일 참조 값 대신 배경 샘플 분포를 사용하고 Shapley 방정식을 사용하여 최대, 소프트맥스, 곱, 분할 등과 같은 구성 요소를 선형화한다는 점에서 원래 DeepLIFT와 다릅니다. 이러한 개선 사항 중 일부도 변경되었습니다. 이후 DeepLIFT에 통합되었습니다. TensorFlow 백엔드를 사용하는 TensorFlow 모델 및 Keras 모델이 지원됩니다(PyTorch에 대한 예비 지원도 있음).
# ...include code from https://github.com/keras-team/keras/blob/master/examples/demo_mnist_convnet.py
import shap
import numpy as np
# select a set of background examples to take an expectation over
background = x_train [ np . random . choice ( x_train . shape [ 0 ], 100 , replace = False )]
# explain predictions of the model on four images
e = shap . DeepExplainer ( model , background )
# ...or pass tensors directly
# e = shap.DeepExplainer((model.layers[0].input, model.layers[-1].output), background)
shap_values = e . shap_values ( x_test [ 1 : 5 ])
# plot the feature attributions
shap . image_plot ( shap_values , - x_test [ 1 : 5 ])위의 플롯은 4개의 서로 다른 이미지에 대한 10개의 출력(숫자 0-9)을 설명합니다. 빨간색 픽셀은 모델의 출력을 증가시키고 파란색 픽셀은 출력을 감소시킵니다. 입력 이미지는 왼쪽에 표시되며 각 설명 뒤에 거의 투명한 회색조 배경이 표시됩니다. SHAP 값의 합은 예상 모델 출력(백그라운드 데이터 세트에 대한 평균)과 현재 모델 출력 간의 차이와 같습니다. '0' 이미지의 경우 가운데 빈 공간이 중요한 반면, '4' 이미지의 경우 상단 연결이 부족하여 9가 아닌 4가 됩니다.
예상 그라디언트는 통합 그라디언트, SHAP 및 SmoothGrad의 아이디어를 단일 기대값 방정식으로 결합합니다. 이를 통해 전체 데이터 세트를 배경 분포(단일 참조 값이 아닌)로 사용할 수 있으며 로컬 평활화가 가능합니다. 각 배경 데이터 샘플과 설명할 현재 입력 사이의 선형 함수를 사용하여 모델을 근사화하고 입력 특성이 독립적이라고 가정하면 예상 기울기가 대략적인 SHAP 값을 계산합니다. 아래 예에서는 VGG16 ImageNet 모델의 7번째 중간 계층이 출력 확률에 어떻게 영향을 미치는지 설명했습니다.
from keras . applications . vgg16 import VGG16
from keras . applications . vgg16 import preprocess_input
import keras . backend as K
import numpy as np
import json
import shap
# load pre-trained model and choose two images to explain
model = VGG16 ( weights = 'imagenet' , include_top = True )
X , y = shap . datasets . imagenet50 ()
to_explain = X [[ 39 , 41 ]]
# load the ImageNet class names
url = "https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json"
fname = shap . datasets . cache ( url )
with open ( fname ) as f :
class_names = json . load ( f )
# explain how the input to the 7th layer of the model explains the top two classes
def map2layer ( x , layer ):
feed_dict = dict ( zip ([ model . layers [ 0 ]. input ], [ preprocess_input ( x . copy ())]))
return K . get_session (). run ( model . layers [ layer ]. input , feed_dict )
e = shap . GradientExplainer (
( model . layers [ 7 ]. input , model . layers [ - 1 ]. output ),
map2layer ( X , 7 ),
local_smoothing = 0 # std dev of smoothing noise
)
shap_values , indexes = e . shap_values ( map2layer ( to_explain , 7 ), ranked_outputs = 2 )
# get the names for the classes
index_names = np . vectorize ( lambda x : class_names [ str ( x )][ 1 ])( indexes )
# plot the explanations
shap . image_plot ( shap_values , to_explain , index_names ) 두 개의 입력 이미지에 대한 예측은 위의 플롯에 설명되어 있습니다. 빨간색 픽셀은 클래스의 확률을 높이는 양의 SHAP 값을 나타내고, 파란색 픽셀은 클래스의 확률을 줄이는 음의 SHAP 값을 나타냅니다. ranked_outputs=2 사용하면 각 입력에 대해 가장 가능성이 높은 두 개의 클래스만 설명됩니다(이렇게 하면 1,000개의 클래스를 모두 설명할 필요가 없습니다).
커널 SHAP는 특별히 가중치가 부여된 로컬 선형 회귀를 사용하여 모든 모델의 SHAP 값을 추정합니다. 아래는 클래식 붓꽃 데이터세트의 다중 클래스 SVM을 설명하는 간단한 예입니다.
import sklearn
import shap
from sklearn . model_selection import train_test_split
# print the JS visualization code to the notebook
shap . initjs ()
# train a SVM classifier
X_train , X_test , Y_train , Y_test = train_test_split ( * shap . datasets . iris (), test_size = 0.2 , random_state = 0 )
svm = sklearn . svm . SVC ( kernel = 'rbf' , probability = True )
svm . fit ( X_train , Y_train )
# use Kernel SHAP to explain test set predictions
explainer = shap . KernelExplainer ( svm . predict_proba , X_train , link = "logit" )
shap_values = explainer . shap_values ( X_test , nsamples = 100 )
# plot the SHAP values for the Setosa output of the first instance
shap . force_plot ( explainer . expected_value [ 0 ], shap_values [ 0 ][ 0 ,:], X_test . iloc [ 0 ,:], link = "logit" )위의 설명은 모델 출력을 기본 값(우리가 전달한 훈련 데이터 세트에 대한 평균 모델 출력)에서 0으로 밀어내는 데 각각 기여하는 네 가지 기능을 보여줍니다. 클래스 라벨을 더 높게 올리는 기능이 있는 경우 빨간색으로 표시됩니다.
위와 같이 많은 설명을 취해서 90도 회전시킨 후 가로로 쌓아 올리면 전체 데이터세트에 대한 설명을 볼 수 있습니다. 이것이 바로 홍채 테스트 세트의 모든 예에 대해 아래에서 수행하는 작업입니다.
# plot the SHAP values for the Setosa output of all instances
shap . force_plot ( explainer . expected_value [ 0 ], shap_values [ 0 ], X_test , link = "logit" ) SHAP 상호작용 값은 SHAP 값을 고차원 상호작용으로 일반화한 것입니다. shap.TreeExplainer(model).shap_interaction_values(X) 사용하여 트리 모델에 대해 쌍별 상호 작용의 빠르고 정확한 계산이 구현됩니다. 이는 주효과가 대각선에 있고 상호작용 효과가 대각선 밖에 있는 모든 예측에 대한 행렬을 반환합니다. 이러한 값은 종종 60세 남성의 사망 위험 증가가 최고조에 달하는 것과 같은 흥미로운 숨겨진 관계를 드러냅니다(자세한 내용은 NHANES 노트북 참조).
아래 노트북은 SHAP의 다양한 사용 사례를 보여줍니다. 원본 노트북을 직접 가지고 놀고 싶다면 저장소의 노트북 디렉토리를 살펴보세요.
트리 및 트리의 앙상블에 대한 SHAP 값을 계산하는 빠르고 정확한 알고리즘인 Tree SHAP의 구현입니다.
XGBoost 및 SHAP 상호 작용 값을 사용하는 NHANES 생존 모델 - 20년간의 추적 조사에서 얻은 사망률 데이터를 사용하여 이 노트북은 XGBoost 및 shap 사용하여 복잡한 위험 요인 관계를 찾아내는 방법을 보여줍니다.
LightGBM을 사용한 인구 조사 소득 분류 - 표준 성인 인구 조사 소득 데이터 세트를 사용하여 이 노트북은 LightGBM을 사용하여 경사 부스팅 트리 모델을 훈련한 다음 shap 사용하여 예측을 설명합니다.
XGBoost를 사용한 League of Legends 승리 예측 - League of Legends의 180,000개 순위 경기로 구성된 Kaggle 데이터 세트를 사용하여 플레이어가 경기에서 승리할지 예측하기 위해 XGBoost를 사용한 그래디언트 부스팅 트리 모델을 훈련하고 설명합니다.
SHAP와 DeepLIFT 알고리즘 간의 연결을 기반으로 하는 딥 러닝 모델의 SHAP 값을 계산하는 더 빠른(그러나 대략적인) 알고리즘인 Deep SHAP의 구현입니다.
Keras를 사용한 MNIST 숫자 분류 - MNIST 필기 인식 데이터세트를 사용하여 이 노트북은 Keras로 신경망을 훈련한 다음 shap 사용하여 예측을 설명합니다.
IMDB 감정 분류를 위한 Keras LSTM - 이 노트북은 IMDB 텍스트 감정 분석 데이터 세트에서 Keras를 사용하여 LSTM을 교육한 다음 shap 사용하여 예측을 설명합니다.
딥 러닝 모델의 SHAP 값을 근사화하기 위해 예상되는 기울기를 구현합니다. 이는 SHAP와 통합 그라데이션 알고리즘 간의 연결을 기반으로 합니다. GradientExplainer는 DeepExplainer보다 느리고 다른 근사 가정을 합니다.
독립적인 특징을 가진 선형 모델의 경우 정확한 SHAP 값을 분석적으로 계산할 수 있습니다. 특성 공분산 행렬을 추정하려는 경우 특성 상관 관계를 설명할 수도 있습니다. LinearExplainer는 이 두 가지 옵션을 모두 지원합니다.
모든 모델의 SHAP 값을 추정하는 모델 불가지론적 방법인 커널 SHAP의 구현입니다. 모델 유형에 대한 가정을 하지 않기 때문에 KernelExplainer는 다른 모델 유형별 알고리즘보다 느립니다.
scikit-learn을 사용한 인구 조사 소득 분류 - 표준 성인 인구 조사 소득 데이터 세트를 사용하여 이 노트북은 scikit-learn을 사용하여 k-최근접 이웃 분류기를 훈련한 다음 shap 사용하여 예측을 설명합니다.
Keras를 사용한 ImageNet VGG16 모델 - 이미지에 대한 기존 VGG16 컨벌루션 신경망의 예측을 설명합니다. 이는 모델에 구애받지 않는 커널 SHAP 방법을 슈퍼픽셀 분할 이미지에 적용하여 작동합니다.
붓꽃 분류 - 인기 있는 붓꽃 종 데이터세트를 사용한 기본 데모입니다. shap 사용하여 scikit-learn의 6가지 서로 다른 모델로부터의 예측을 설명합니다.
이 노트북은 특정 기능과 개체를 사용하는 방법을 포괄적으로 보여줍니다.
shap.decision_plot 및 shap.multioutput_decision_plot
shap.dependence_plot
라임: Ribeiro, Marco Tulio, Sameer Singh, Carlos Guestrin. "내가 왜 당신을 믿어야 할까요?: 분류기의 예측을 설명합니다." 지식 발견 및 데이터 마이닝에 관한 제22차 ACM SIGKDD 국제 컨퍼런스 간행물입니다. ACM, 2016.
Shapley 샘플링 값: Strumbelj, Erik 및 Igor Kononenko. "특징 기여를 통해 예측 모델과 개별 예측을 설명합니다." 지식정보시스템 41.3(2014): 647-665.
DeepLIFT: Shrikumar, Avanti, Peyton Greenside 및 Anshul Kundaje. "활성화 차이 전파를 통해 중요한 기능을 학습합니다." arXiv 사전 인쇄 arXiv:1704.02685 (2017).
QII: Datta, Anupam, Shayak Sen, Yair Zick. "정량적 입력 영향을 통한 알고리즘 투명성: 학습 시스템에 대한 이론 및 실험." 보안 및 개인 정보 보호(SP), 2016 IEEE 심포지엄. IEEE, 2016.
레이어별 관련성 전파: Bach, Sebastian, et al. "레이어별 관련성 전파에 의한 비선형 분류기 결정에 대한 픽셀별 설명." PloS one 10.7(2015): e0130140.
Shapley 회귀 값: Lipovetsky, Stan 및 Michael Conklin. "게임 이론 접근 방식의 회귀 분석." 비즈니스 및 산업에 확률론적 모델 적용 17.4(2001): 319-330.
트리 해석기: Saabas, Ando. 랜덤 포레스트 해석. http://blog.datadive.net/interpreting-random-forests/
이 패키지에 사용된 알고리즘과 시각화는 주로 워싱턴 대학의 이수인 연구실과 Microsoft Research의 연구에서 나온 것입니다. 연구에 SHAP를 사용하는 경우 해당 논문을 인용해 주시면 감사하겠습니다.
force_plot 시각화 및 의료 응용 분야의 경우 Nature Biomedical Engineering 논문을 읽거나 인용할 수 있습니다(bibtex, 무료 액세스).

