Awesome LLM 3D
1.0.0
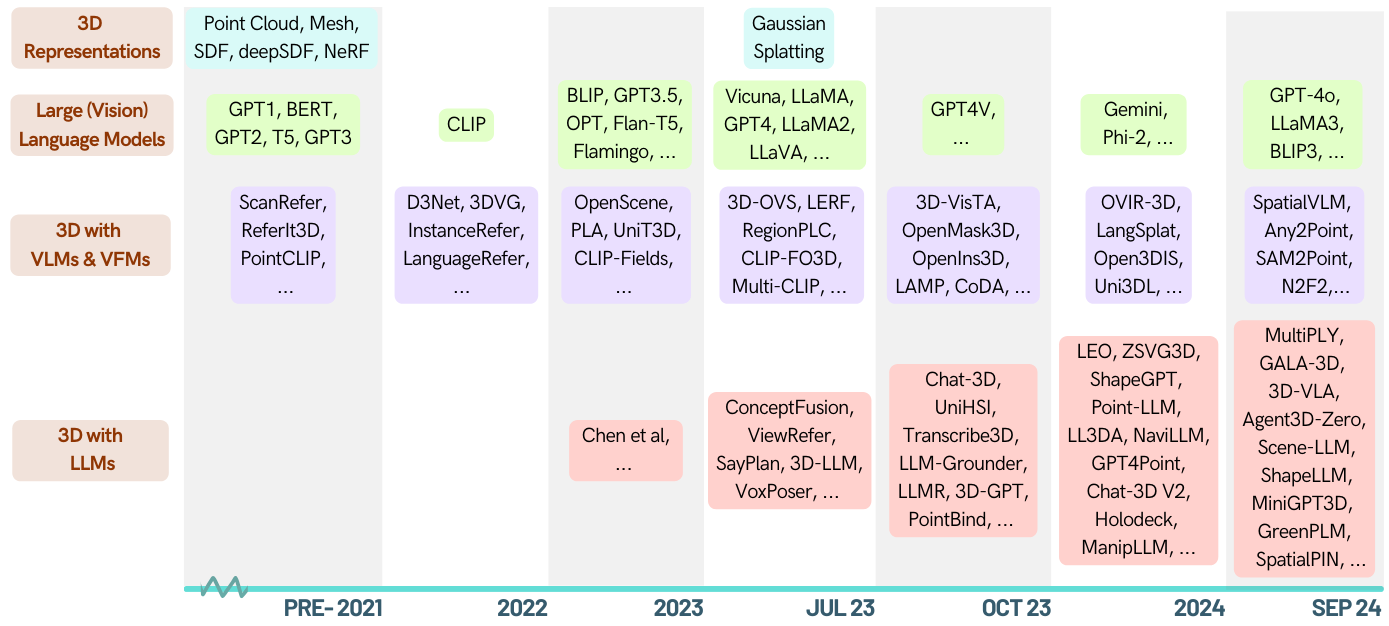
다음은 LLMS (Lange Language Models)에 의해 강화 된 3D 관련 작업에 대한 큐 레이트 된 논문 목록입니다. 여기에는 3D 이해, 추론, 세대 및 구체화 된 에이전트를 포함한 다양한 작업이 포함되어 있습니다. 또한, 우리는이 영역의 전체 그림에 대한 다른 기초 모델 (Clip, Sam)을 포함합니다.
이것은 활성 저장소이며 최신 발전을 따라갈 수 있습니다. 유용하다고 생각되면이 저장소를 친절하게별로 표현하고 논문을 인용하십시오.
[2024-05-16]? 3D-LLM 도메인의 첫 번째 설문 조사 논문을 확인하십시오 : LLM이 3D 세계로 향하는 경우 : 멀티 모달 큰 언어 모델을 통한 3D 작업의 설문 조사 및 메타 분석.
[2024-01-06] Runsen Xu는 연대순 정보를 추가했으며 Xianzheng Ma는 최신 발전에 이어 ZA Order로 재구성했습니다.
[2023-12-16] Xianzheng Ma와 Yash Bhalgat 은이 목록을 기획하고 첫 번째 버전을 게시했습니다.
멋진 -llm-3d
3D 이해 (LLM)
3D 이해 (기타 기초 모델)
3D 추론
3D 세대
3D 구체화제
3D 벤치 마크
기여
| 날짜 | 키워드 | 연구소 (첫 번째) | 종이 | 출판 | 기타 |
|---|---|---|---|---|---|
| 2024-10-12 | 상황 3d | UIUC | 상황 인식은 3D 비전 언어 추론에서 중요합니다 | CVPR '24 | 프로젝트 |
| 2024-09-28 | llava-3d | hku | LLAVA-3D : 3D 인식으로 LMM에 권한을 부여하는 간단하면서도 효과적인 경로 | arxiv | 프로젝트 |
| 2024-09-08 | MSR3D | bigai | 3D 장면에서 멀티 모달 위치 추론 | Neurips '24 | 프로젝트 |
| 2024-08-28 | Greenplm | 가슴 | 더 많은 텍스트, 적은 포인트 : 3D 데이터 효율적인 포인트 언어 이해를 향해 | arxiv | github |
| 2024-06-17 | llana | 유니보 | Llana : 대형 언어 및 NERF 보조 | Neurips '24 | 프로젝트 |
| 2024-06-07 | 공간 핀 | 옥스퍼드 | 공간 핀 : 3D 사전을 제기하고 상호 작용하여 비전 언어 모델의 공간 추론 능력 향상 | Neurips '24 | 프로젝트 |
| 2024-06-03 | Spatialrgpt | UCSD | SPATIALRGPT : 비전 언어 모델의 공간 추론 | Neurips '24 | github |
| 2024-05-02 | Minigpt-3d | 가슴 | MINIGPT-3D : 2D 사전을 사용하여 큰 언어 모델로 3D 포인트 구름을 효율적으로 정렬 | ACM MM '24 | 프로젝트 |
| 2024-02-27 | Shapellm | XJTU | Shapellm : 구체화 된 상호 작용에 대한 범용 3D 객체 이해 | arxiv | 프로젝트 |
| 2024-01-22 | 공간 VLM | Google Deepmind | SpatialVLM : 공간 추론 능력을 갖춘 비전 언어 모델을 부여합니다 | CVPR '24 | 프로젝트 |
| 2023-12-21 | LIDAR-LLM | PKU | LIDAR-LLM : 3D LIDAR 이해를위한 대형 언어 모델의 잠재력 탐색 | arxiv | 프로젝트 |
| 2023-12-15 | 3dap | 상하이 AI 실험실 | 3daxiesprompts : GPT-4V의 3D 공간 작업 기능을 해제합니다 | arxiv | 프로젝트 |
| 2023-12-13 | 대화 내전 | 즈 주 | Chat-Scene : 개체 식별자가있는 3D 장면 및 대형 언어 모델 브리징 | Neurips '24 | github |
| 2023-12-5 | gpt4point | hku | GPT4Point : 포인트 언어 이해 및 생성을위한 통합 프레임 워크 | arxiv | github |
| 2023-11-30 | ll3da | 후단 대학교 | LL3DA : OMNI-3D 이해, 추론 및 계획을위한 시각적 대화 형 교육 튜닝 | arxiv | github |
| 2023-11-26 | ZSVG3D | Cuhk (SZ) | Zero-Shot Open-Vocabulary 3D 시각적 접지에 대한 시각적 프로그래밍 | arxiv | 프로젝트 |
| 2023-11-18 | 사자 별자리 | bigai | 3D 세계의 구체화 된 일반 요원 | arxiv | github |
| 2023-10-14 | JM3D-LLM | Xiamen University | JM3D & JM3D-LLM : 관절 멀티 모달 신호로 3D 표현을 높이기 | ACM MM '23 | github |
| 2023-10-10 | Uni3d | 바이 | UNI3D : 규모에 따라 통합 3D 표현 탐색 | ICLR '24 | 프로젝트 |
| 2023-9-27 | - | 카우스트 | 제로 샷 3D 모양 대응 | Siggraph Asia '23 | - |
| 2023-9-21 | llm-grounder | U-Mich | LLM-Grounder : 에이전트로서 큰 언어 모델을 가진 개방형 3D 시각적 접지 | ICRA '24 | github |
| 2023-9-1 | 포인트 바인드 | Cuhk | Point-Bind & Point-LLM : 3D 이해, 생성 및 지시를위한 다중 유산과 포인트 클라우드를 정렬 | arxiv | github |
| 2023-8-31 | 포인트 | Cuhk | Pointllm : 포인트 구름을 이해하도록 큰 언어 모델을 강화합니다 | ECCV '24 | github |
| 2023-8-17 | 채팅 -3d | 즈 주 | Chat-3D : 3D 장면의 보편적 인 대화에 대한 대형 언어 모델 데이터 효율적으로 조정 | arxiv | github |
| 2023-8-8 | 3D-Vista | bigai | 3D-Vista : 3D 비전 및 텍스트 정렬을위한 미리 훈련 된 변압기 | ICCV '23 | github |
| 2023-7-24 | 3d-llm | UCLA | 3D-LLM : 3D 세계를 큰 언어 모델에 주입합니다 | Neurips '23 | github |
| 2023-3-29 | ViewRefer | Cuhk | ViewRefer : 3D 시각적 접지에 대한 멀티 뷰 지식을 파악하십시오 | ICCV '23 | github |
| 2022-9-12 | - | MIT | 로봇 3D 장면 이해를위한 대형 (시각적) 언어 모델 활용 | arxiv | github |
| ID | 키워드 | 연구소 (첫 번째) | 종이 | 출판 | 기타 |
|---|---|---|---|---|---|
| 2024-10-12 | Lexicon3d | UIUC | Lexicon3D : 복잡한 3D 장면 이해를위한 시각적 기초 모델 조사 | Neurips '24 | 프로젝트 |
| 2024-10-07 | diff2scene | CMU | 텍스트-이미지 확산 모델을 사용한 개방-보조 사우절 3D 시맨틱 세분화 | ECCV 2024 | 프로젝트 |
| 2024-04-07 | Any2point | 상하이 AI 실험실 | Any2Point : 효율적인 3D 이해를위한 대규모 모델의 권한을 부여합니다 | ECCV 2024 | github |
| 2024-03-16 | N2F2 | 옥스포드 -VGG | N2F2 : 중첩 된 신경 특징 필드를 사용한 계층 적 장면 이해 | arxiv | - |
| 2023-12-17 | SAI3D | PKU | SAI3D : 3D 장면에서 인스턴스를 분할하십시오 | arxiv | 프로젝트 |
| 2023-12-17 | Open3dis | 비나이 | Open3Dis : 2D 마스크 가이드를 사용한 Open-Vocabulary 3D 인스턴스 분할 | arxiv | 프로젝트 |
| 2023-11-6 | ovir-3d | Rutgers University | OVIR-3D : 3D 데이터에 대한 교육이없는 Open-Vocabulary 3D 인스턴스 검색 | Corl '23 | github |
| 2023-10-29 | OpenMask3d | ETH | OpenMask3d : Open-Vocabulary 3D 인스턴스 분할 | Neurips '23 | 프로젝트 |
| 2023-10-5 | 개방 퓨전 | - | 오픈 퓨전 : 실시간 오픈-비경사 3D 매핑 및 쿼리 가능한 장면 표현 | arxiv | github |
| 2023-9-22 | OV-3DDET | hkust | Coda : 개방형 변호사 3D 객체 감지를위한 공동 소설 상자 발견 및 교차 모달 정렬 | Neurips '23 | github |
| 2023-9-19 | 램프 | - | 언어에서 3D 세계로 : 포인트 클라우드 인식에 대한 언어 모델 적응 | OpenReview | - |
| 2023-9-15 | 오픈 너프 | - | Opennerf : 픽셀 특징 및 렌더링 된 새로운보기로 오픈 세트 3D 신경 장면 세분화 | OpenReview | github |
| 2023-9-1 | OpenIns3d | 케임브리지 | OpenIns3d : 3D Open-Vocabulary 인스턴스 세분화를위한 스냅 및 조회 | arxiv | 프로젝트 |
| 2023-6-7 | 대조적 인 리프트 | 옥스포드 -VGG | 대비 리프트 : 천천히 빠른 대비 융합에 의한 3D 객체 인스턴스 세분화 | Neurips '23 | github |
| 2023-6-4 | 멀티 클립 | ETH | 멀티 클립 : 대조적 인 비전 언어 사전 훈련 질문에 대한 3D 장면에서 작업에 응답하는 작업 | arxiv | - |
| 2023-5-23 | 3D-OVS | NTU | 약하게 감독 된 3D 개방-보조 분할 세그먼트 | Neurips '23 | github |
| 2023-5-21 | VL 필드 | 에든버러 대학교 | VL 필드 : 언어 지정 신경 암시 적 공간 표현으로 | ICRA '23 | 프로젝트 |
| 2023-5-8 | 클립 -FO3D | Tsinghua University | Clip-Fo3d : 2D 조밀 한 클립에서 무료 오픈 월드 3D 장면 표현 학습 | ICCVW '23 | - |
| 2023-4-12 | 3D-VQA | ETH | 3D 장면에서 질문에 대한 질문에 대한 클립 유도 비전 언어 사전 훈련 | CVPRW '23 | github |
| 2023-4-3 | Regionplc | hku | RegionPLC : 오픈 월드 3D 장면 이해를위한 지역 포인트-언어 대비 학습 | arxiv | 프로젝트 |
| 2023-3-20 | CG3D | JHU | 클립은 3D : 언어 접지 3D 인식에 대한 프롬프트 튜닝 활용 | arxiv | github |
| 2023-3-16 | 레프 | UC 버클리 | LERF : 언어 내장 방사선 필드 | ICCV '23 | github |
| 2023-2-14 | 개념화 | MIT | ConceptFusion : 오픈 세트 멀티 모달 3D 매핑 | RSS '23 | 프로젝트 |
| 2023-1-12 | Clip2Scene | hku | Clip2Scene : 클립 별 레이블 효율적인 3D 장면 이해를 향해 | CVPR '23 | github |
| 2022-12-1 | Unit3d | 종 | UNIT3D : 3D 고밀도 캡션 및 시각적 접지를위한 통합 변압기 | ICCV '23 | github |
| 2022-11-29 | PLA | hku | PLA : 언어 중심의 개방형 평균 3D 장면 이해 | CVPR '23 | github |
| 2022-11-28 | OpenScene | 에츠 | OpenScene : 개방형 어휘를 사용한 3D 장면 이해 | CVPR '23 | github |
| 2022-10-11 | 클립 필드 | NYU | 클립 필드 : 로봇 메모리를위한 약하게 감독 된 시맨틱 필드 | arxiv | 프로젝트 |
| 2022-7-23 | 시맨틱 추상화 | 콜롬비아 | 시맨틱 추상화 : 2D 비전 언어 모델의 오픈 월드 3D 장면 이해 | Corl '22 | 프로젝트 |
| 2022-4-26 | Scannet200 | 종 | 야생의 언어 지정 실내 3D 시맨틱 세분화 | ECCV '22 | 프로젝트 |
| 날짜 | 키워드 | 연구소 (첫 번째) | 종이 | 출판 | 기타 |
|---|---|---|---|---|---|
| 2023-5-20 | 3D-Clr | UCLA | 멀티 뷰 이미지의 3D 개념 학습 및 추론 | CVPR '23 | github |
| - | 전사 3D | 시카고 TTI | Transcribe3d : 자체 조정 된 양정을 사용한 3D 참조 추론을위한 전사 된 정보를 사용하여 LLM을 접지 | Corl '23 | github |
| 날짜 | 키워드 | 학회 | 종이 | 출판 | 기타 |
|---|---|---|---|---|---|
| 2023-11-29 | shapegpt | 후단 대학교 | ShapeGpt : 통합 된 멀티 모달 언어 모델을 가진 3D 모양 생성 | arxiv | github |
| 2023-11-27 | meshgpt | 종 | MESHGPT : 디코더 전용 변압기로 삼각형 메쉬 생성 | arxiv | 프로젝트 |
| 2023-10-19 | 3d-Gpt | anu | 3D-GPT : 대형 언어 모델을 갖춘 절차 적 3D 모델링 | arxiv | github |
| 2023-9-21 | llmr | MIT | LLMR : 대형 언어 모델을 사용하는 대화식 세계의 실시간 프롬프트 | arxiv | - |
| 2023-9-20 | Dreamllm | Megvii | Dreamllm : 시너지 효과적인 멀티 모달 이해력과 창조 | arxiv | github |
| 2023-4-1 | chatavatar | Deemos Tech | Dreamface : 텍스트 안내에 따라 애니메이션 3D 얼굴의 진보적 인 생성 | ACM TOG | 웹 사이트 |
| 날짜 | 키워드 | 학회 | 종이 | 출판 | 기타 |
|---|---|---|---|---|---|
| 2024-01-22 | 공간 VLM | 심해 | SpatialVLM : 공간 추론 능력을 갖춘 비전 언어 모델을 부여합니다 | CVPR '24 | 프로젝트 |
| 2023-11-27 | dobb-e | NYU | 로봇을 집으로 데려 오는 데 | arxiv | github |
| 2023-11-26 | 스티브 | 즈 주 | 보고 생각 : 가상 환경에서 구체화 된 에이전트 | arxiv | github |
| 2023-11-18 | 사자 별자리 | bigai | 3D 세계의 구체화 된 일반 요원 | arxiv | github |
| 2023-9-14 | unihsi | 상하이 AI 실험실 | 촉진 된 접촉을 통한 통합 된 인간 장면 상호 작용 | arxiv | github |
| 2023-7-28 | RT-2 | Google-Deepmind | RT-2 : 비전 언어 작용 모델은 웹 지식을 로봇 제어로 전달합니다 | arxiv | github |
| 2023-7-12 | SayPlan | 로봇 공학을위한 QUT 센터 | SayPlan : 확장 가능한 로봇 작업 계획을위한 3D 장면 그래프를 사용하여 대형 언어 모델 접지 | Corl '23 | github |
| 2023-7-12 | 수상자 | 스탠포드 | Voxposer : 언어 모델을 사용한 로봇 조작을위한 Composable 3D 값 맵 | arxiv | github |
| 2022-12-13 | RT-1 | RT-1 : 실제 규모의 실제 제어를위한 로봇 변압기 | arxiv | github | |
| 2022-12-8 | LLM-Planner | 오하이오 주립 대학 | LLM-PLANNER : 대형 언어 모델을 가진 구체화 된 에이전트를위한 소수의 기반 계획 | ICCV '23 | github |
| 2022-10-11 | 클립 필드 | NYU, 메타 | 클립 필드 : 로봇 메모리를위한 약하게 감독 된 시맨틱 필드 | RSS '23 | github |
| 2022-09-20 | nlmap-saycan | 실제 계획을위한 개방형 쿼리 가능한 장면 표현 | ICRA '23 | github |
| 날짜 | 키워드 | 학회 | 종이 | 출판 | 기타 |
|---|---|---|---|---|---|
| 2024-09-08 | MSQA / MSNN | bigai | 3D 장면에서 멀티 모달 위치 추론 | Neurips '24 | 프로젝트 |
| 2024-06-10 | 3D 그랜드 / 3D-pope | 움 미치 | 3D 그랜드 : 접지가 향상되고 환각이 적은 3D-LLMS 용 백만 규모의 데이터 세트 | arxiv | 프로젝트 |
| 2024-06-03 | SpatialRGPT-Bench | UCSD | SPATIALRGPT : 비전 언어 모델의 공간 추론 | Neurips '24 | github |
| 2024-1-18 | Sceneverse | bigai | Sceneverse : 기초 장면 이해를위한 3D 시력 학습 스케일링 | arxiv | github |
| 2023-12-26 | 구체화 된 | 상하이 AI 실험실 | 구체화 된 AI에 대한 전체적인 멀티 모달 3D 인식 제품군 | arxiv | github |
| 2023-12-17 | m3dbench | 후단 대학교 | M3DBENCH : 멀티 모달 3D 프롬프트가있는 대형 모델을 지시합시다 | arxiv | github |
| 2023-11-29 | - | 심해 | 3D 객체의 점수 기반의 멀티 프로브 주석에 대한 VLMS 평가 | arxiv | github |
| 2023-09-14 | 크로스 코어 런스 | 유니보 | 주의를 기울여 단어와 포인트보기 : 텍스트 대 모양의 일관성을위한 벤치 마크 | ICCV '23 | github |
| 2022-10-14 | sqa3d | bigai | SQA3D : 3D 장면에서 대답하는 위치에 대한 질문 | ICLR '23 | github |
| 2021-12-20 | Scanqa | Riken AIP | SCANQA : 공간 장면 이해를위한 3D 질문 답변 | CVPR '23 | github |
| 2020-12-3 | scan2cap | 종 | SCAN2CAP : RGB-D 스캔에서 컨텍스트 인식 조밀 한 캡션 | CVPR '21 | github |
| 2020-8-23 | 참조 3d | 스탠포드 | Referit3d : 실제 장면에서 세밀한 3D 객체 식별을위한 신경 청취자 | ECCV '20 | github |
| 2019-12-18 | Scanrefer | 종 | ScanRefer : 자연 언어를 사용하여 RGB-D 스캔의 3D 객체 현지화 | ECCV '20 | github |
당신의 기여는 항상 환영합니다!
3D LLM에 굉장한 지 확실하지 않으면 풀 요청을 열어 줄 것입니다. 추가하여 투표 할 수 있습니까? 그들에게.
이 의견이있는 목록에 대해 궁금한 점이 있으면 [email protected] 또는 wechat id : MXZ1997112로 연락하십시오.
이 저장소가 유용하다고 생각되면이 논문을 인용하는 것을 고려하십시오.
@misc{ma2024llmsstep3dworld,
title={When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models},
author={Xianzheng Ma and Yash Bhalgat and Brandon Smart and Shuai Chen and Xinghui Li and Jian Ding and Jindong Gu and Dave Zhenyu Chen and Songyou Peng and Jia-Wang Bian and Philip H Torr and Marc Pollefeys and Matthias Nießner and Ian D Reid and Angel X. Chang and Iro Laina and Victor Adrian Prisacariu},
year={2024},
journal={arXiv preprint arXiv:2405.10255},
}이 repo는 Awesome-Llm에서 영감을 받았습니다


