IncarnaMind
1.0.0
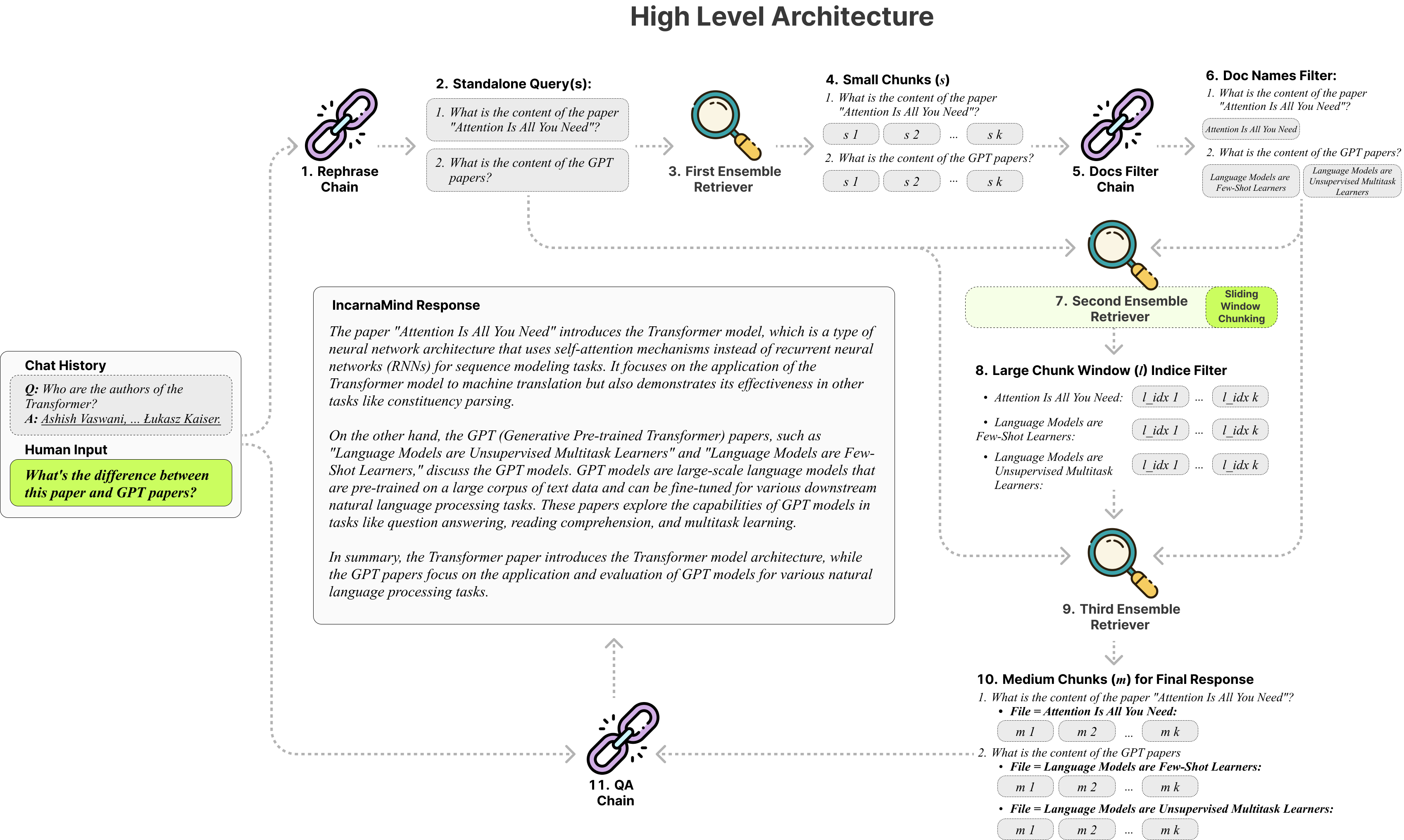
InCarnamind는 개인 문서와 채팅 할 수 있습니까? (PDF, TXT) GPT (아키텍처 개요)와 같은 대형 언어 모델 (LLMS)을 사용하는 (PDF). OpenAI는 최근 GPT 모델을위한 미세 조정 API를 출시했지만 기본 사전 제기 된 모델이 새로운 데이터를 배울 수 없으며 반응은 사실적인 환각에 걸릴 수 있습니다. 슬라이딩 윈도우 청크 메커니즘과 앙상블 리트리버를 사용하면 지상 진실 문서 내에서 세밀한 입자와 거친 정보를 모두 효율적으로 쿼리하여 LLM을 증대시킬 수 있습니다.
자유롭게 사용하고 피드백과 새로운 기능 제안을 환영합니까?.
다음은 참조 만 테스트 한 다른 모델의 비교 테이블입니다.
| 메트릭 | GPT-4 | GPT-3.5 | 클로드 2.0 | llama2-70b | llama2-70b-gguf | llama2-70B-API |
|---|---|---|---|---|---|---|
| 추리 | 높은 | 중간 | 높은 | 중간 | 중간 | 중간 |
| 속도 | 중간 | 높은 | 중간 | 매우 낮습니다 | 낮은 | 중간 |
| GPU 램 | N/A | N/A | N/A | 매우 높습니다 | 높은 | N/A |
| 안전 | 낮은 | 낮은 | 낮은 | 높은 | 높은 | 낮은 |
고정 청크 : 전통적인 래그 도구는 고정 청크 크기에 의존하여 다양한 데이터 복잡성 및 컨텍스트를 처리 할 때 적응성을 제한합니다.
정밀성 대 의미론 : 현재 검색 방법은 일반적으로 의미 론적 이해 또는 정확한 검색에 중점을 두지 만 거의 둘 다 거의 없습니다.
단일 문서 제한 : 많은 솔루션이 한 번에 하나의 문서 만 쿼리하여 다중 문서 정보 검색을 제한 할 수 있습니다.
안정성 : InCarnamind는 OpenAi GPT, Anthropic Claude, LLAMA2 및 기타 오픈 소스 LLM과 호환되어 안정적인 구문 분석을 보장합니다.
적응 형 청크 : 슬라이딩 윈도우 청킹 기술은 헝겊의 창 크기와 위치를 동적으로 조정하여 데이터 복잡성과 컨텍스트를 기반으로 세밀하고 거친 데이터 액세스를 균형 잡습니다.
멀티 문서 대화 QA : 여러 문서에서 간단하고 멀티 홉 쿼리를 동시에 지원하여 단일 문서 제한을 중단합니다.
파일 호환성 : PDF 및 TXT 파일 형식을 모두 지원합니다.
LLM 모델 호환성 : OpenAI GPT, Anthropic Claude, LLAMA2 및 기타 오픈 소스 LLM을 지원합니다.

설치는 간단합니다. 몇 가지 명령 만 실행하면됩니다.
git clone https://github.com/junruxiong/IncarnaMind
cd IncarnaMind콘다 가상 환경 만들기 :
conda create -n IncarnaMind python=3.10활성화 :
conda activate IncarnaMind모든 요구 사항 설치 :
pip install -r requirements.txt정량화 된 로컬 LLM을 실행하려면 llama-cpp를 speratly로 설치하십시오.
NVIDIA GPUS 지원의 경우 cuBLAS 사용하십시오 CMAKE_ARGS= " -DLLAMA_CUBLAS=on " FORCE_CMAKE=1 pip install llama-cpp-python==0.1.83 --no-cache-dirM1/M2 ) 지원의 경우 사용을 사용하십시오 CMAKE_ARGS= " -DLLAMA_METAL=on " FORCE_CMAKE=1 pip install llama-cpp-python==0.1.83 --no-cache-dirconfigparser.ini 파일에서 하나/모든 API 키를 설정하십시오.
[tokens]
OPENAI_API_KEY = (replace_me)
ANTHROPIC_API_KEY = (replace_me)
TOGETHER_API_KEY = (replace_me)
# if you use full Meta-Llama models, you may need Huggingface token to access.
HUGGINGFACE_TOKEN = (replace_me)(선택 사항) configparser.ini 파일에서 사용자 정의 매개 변수를 설정합니다.
[parameters]
PARAMETERS 1 = (replace_me)
PARAMETERS 2 = (replace_me)
...
PARAMETERS n = (replace_me)모든 파일을 /데이터 디렉토리에 넣고 다음 명령을 실행하여 모든 데이터를 수집하려면 다음 명령을 실행하십시오. (명령을 실행하기 전에 /데이터 디렉토리에서 예제 파일을 삭제할 수 있습니다)
python docs2db.py대화를 시작하려면 다음과 같은 명령을 실행하십시오.
python main.py스크립트가 아래와 같이 입력을 요구할 때까지 기다리십시오.
Human:채팅을 시작하면 시스템이 자동으로 InCarnamind.log 파일을 생성합니다. 로깅을 편집하려면 configparser.ini 파일에서 편집하십시오.
[logging]
enabled = True
level = INFO
filename = IncarnaMind.log
format = %(asctime)s [%(levelname)s] %(name)s: %(message)s오픈 소스 커뮤니티에 대한 귀중한 기여를 한 Langchain, Chroma DB, LocalGpt, Llama-CPP에게 특별한 감사를드립니다. 그들의 작업은 InCarnamind 프로젝트를 현실로 만드는 데 중요한 역할을 해왔습니다.
우리의 작업을 인용하려면 다음 Bibtex 항목을 사용하십시오.
@misc { IncarnaMind2023 ,
author = { Junru Xiong } ,
title = { IncarnaMind } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub Repository } ,
howpublished = { url{https://github.com/junruxiong/IncarnaMind} }
}Apache 2.0 라이센스


