
[관련 권장사항: JavaScript 비디오 튜토리얼, 웹 프런트엔드]
어떤 프로그래밍 언어를 사용하든 문자열은 중요한 데이터 유형입니다. JavaScript 문자열에 대해 자세히 알아보려면 저를 팔로우하세요!
문자열은 문자로 구성된 문자열입니다. C 와 Java 공부했다면 문자 자체도 독립적인 유형이 될 수 있다는 것을 알아야 합니다. 그러나 JavaScript 단일 문자 유형이 없으며 길이가 1 인 문자열만 있습니다.
JavaScript 문자열은 고정 UTF-16 인코딩을 사용합니다. 프로그램을 작성할 때 어떤 인코딩을 사용하더라도 영향을 받지 않습니다.
작은따옴표, 큰따옴표, 백틱의 세 가지가 있습니다.
let Single = 'abcdefg';//작은 따옴표 let double = "asdfghj";//큰 따옴표 let backti = `zxcvbnm`;//백틱
작은 따옴표와 큰 따옴표는 동일한 상태이므로 구별하지 않습니다.
문자열 형식
백틱을 사용하면 문자열 추가를 사용하는 대신 ${...} 사용하여 문자열 형식을 우아하게 지정할 수 있습니다.
let str = `저는 ${Math.round(18.5)} 살입니다.`;console.log(str) ;

여러 줄 문자열
백틱을 사용하면 문자열을 여러 줄로 확장할 수 있는데, 이는 여러 줄 문자열을 작성할 때 매우 유용합니다.
let ques = '저자는 잘생겼나요? A. 정말 잘생겼어요. B. 너무 잘생겼어요; C. Super handsome;`;console.log(ques);
코드 실행 결과:
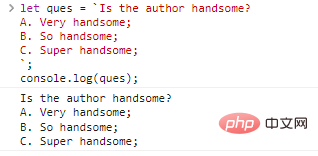
별거 없어 보이는데요? 그러나 작은따옴표와 큰따옴표를 사용하면 이를 달성할 수 없습니다. 동일한 결과를 얻으려면 다음과 같이 작성할 수 있습니다.
let ques = '저자가 잘생겼나요?n매우 잘생겼습니다.nC. Super handsome;'; console.log(ques);
위의 코드에는 프로그래밍 프로세스에서 가장 일반적인 특수 문자인 n 이 포함되어 있습니다.
"개행 문자"라고도 n
엔진이 문자열을 출력할 때 n 만나면 계속해서 다른 줄에 출력하여 여러 줄의 문자열을 구현합니다.
n 두 개의 문자로 보이지만 한 문자 위치만 차지합니다. 이는 가 문자열에서 이스케이프 문자 이고 이 이스케이프 문자로 수정된 문자가 특수 문자가 되기 때문입니다.
특수 문자 목록
| 특수 문자 | 설명 | |
|---|---|---|
n | 출력 텍스트의 새 줄을 시작하는 데 사용되는 개행 문자입니다. | |
r | 캐리지 리턴 문자는 커서를 줄의 시작 부분으로 이동합니다. Windows 시스템에서 rn 줄 바꿈을 나타내는 데 사용됩니다. 즉, 커서가 줄의 시작 부분으로 먼저 이동해야 함을 의미합니다. 새 줄로 변경되기 전에 다음 줄로 이동하세요. 다른 시스템에서는 n 직접 사용할 수 있습니다. | |
' " | 작은 따옴표와 큰 따옴표는 주로 작은 따옴표와 큰 따옴표가 특수 문자이기 때문입니다. 문자열에 작은 따옴표와 큰 따옴표를 사용하려면 이스케이프해야 합니다. | |
\ | 백슬래시, 또한 | |
| ||
b f v | 백스페이스, 페이지 피드, 세로 레이블을 이스케이프해야 합니다. xXX는 더 이상 사용되지 않습니다. | |
xXX | 를 들어 XX 로 인코딩된 16진수 Unicode 문자입니다. : x7A z 의미합니다( z 의 16진수 Unicode 인코딩은 7A 입니다). | |
uXXXX | XXXX 의 16진수 Unicode 문자로 인코딩됩니다. 예: u00A9 는 © | |
( 1-6 기본 문자 u{X...X} | UTF-32 | 의미합니다. 인코딩은 X...X 의 Unicode 기호입니다. |
예:
console.log('I'ma Student.');// 'console.log(""I love U. "");/ / "console.log("\n은 개행 문자입니다.");// nconsole.log('u00A9')// ©console.log('u{1F60D} ');// 코드 실행 결과:
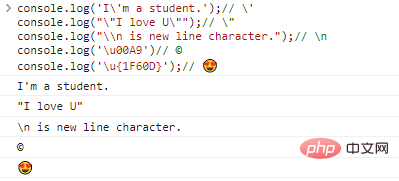
이스케이프 문자 가 있으면 이론적으로 해당 인코딩을 찾는 한 모든 문자를 출력할 수 있습니다.
' 및 " 사용하지 마세요
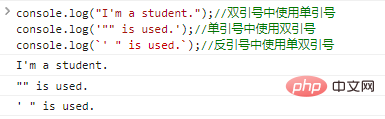
. 작은따옴표 안에 큰따옴표를 사용하거나, 큰따옴표 안에 작은따옴표를 사용하거나, 백틱 안에 작은따옴표와 큰따옴표를 직접 사용할 수 있습니다. 이스케이프 문자를 사용하지 마세요. 예를 들면 다음과 같습니다.
console.log("저는 학생입니다.");
//큰따옴표 안에 작은따옴표를 사용하세요. console.log('""가 사용됩니다.');
//작은따옴표 안에 큰따옴표를 사용하세요. console.log(`' "가 사용됩니다.`);
//백틱에 작은따옴표와 큰따옴표를 사용한 코드 실행 결과는 다음과 같습니다.
문자열의 .length 속성을 통해 문자열의 길이를 얻을 수 있습니다.
console.log("HelloWorldn".length);//11 n 여기서는 한 문자만 차지합니다.
"기본 유형의 메소드" 장에서
JavaScript의 기본 유형에 속성과 메소드가 있는 이유를 살펴보았습니다.
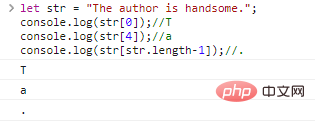
string 문자에 액세스하는 것은 문자 문자열입니다. [字符下标] 아래 첨자는 0 부터 시작합니다.
let str = "The Author is handsome."; console.log(str[0]);//Tconsole.log(str[4]);//aconsole.log(str[str.length-1]);//
코드 실행 결과:
charAt(post) 함수를 사용하여 문자를 얻을 수도 있습니다:
let str = "저자는 잘생겼습니다.";console.log(str.charAt(0)); //Tconsole.log(str.charAt(4)); //aconsole.log(str.charAt(str.length-1));//.
둘의 실행 효과는 정확히 동일하며 유일한 차이점은 범위를 벗어난 문자에 액세스할 때입니다.
let str = "01234"; console.log(str[ 9]);//undefoundconsole.log(str.charAt(9));//"" (빈 문자열)
for ..of 사용하여 문자열을 탐색할 수도 있습니다:
for(let c of '01234'){
console.log(c);} JavaScript 의 문자열은 일단 정의되면 변경할 수 없습니다.
let str = "Const";str[0] = 'c' ;console.log(str)
; 결과:
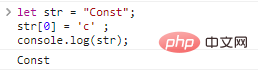
다른 문자열을 얻으려면 새 문자열만 만들 수 있습니다.
let str = "Const";str = str.replace('C','c');console.log(str) ; String 문자를 변경했지만 실제로 원래 문자열은 변경되지 않았으며, 우리가 얻는 것은 replace 메소드에 의해 반환된 새 문자열입니다.
문자열의 대소문자를 변환하거나 문자열에서 단일 문자의 대소문자를 변환합니다.
이 두 문자열에 대한 메서드는 예제에 표시된 것처럼 상대적으로 간단합니다.
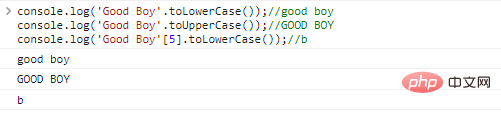
console.log('Good Boy'.toLowerCase());//good
boyconsole.log('Good Boy'.toUpperCase());//GOOD
BOYconsole.log('Good Boy'[5].toLowerCase());//b 코드 실행 결과:
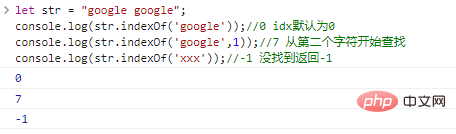
.indexOf(substr,idx) 함수는 문자열의 idx 위치에서 시작하여 하위 문자열 substr 의 위치를 검색하고 해당 문자열의 첫 번째 문자의 아래 첨자를 반환합니다. 성공하면 하위 문자열이고, 실패하면 -1 입니다.
let str = "google google";console.log(str.indexOf('google'));
//0 idx의 기본값은 0console.log(str.indexOf('google',1));
//7 두 번째 문자부터 검색 console.log(str.indexOf('xxx'));
//-1을 찾을 수 없음은 -1 코드 실행 결과를 반환합니다.
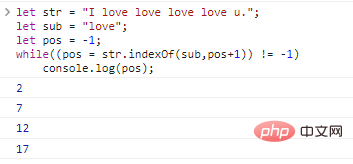
문자열의 모든 하위 문자열 위치를 쿼리하려면 루프를 사용할 수 있습니다.
let str = "I love love love love u.";let sub = "love";let pos = -1;while((pos = str.indexOf (하위,위치+1)) != -1)
console.log(pos); 코드 실행 결과는 다음과 같습니다.
.lastIndexOf(substr,idx) 는 하위 문자열을 거꾸로 검색하여 먼저 일치하는 마지막 문자열을 찾습니다.
let str = "google google";console.log(str.lastIndexOf('google'));//7 idx 기본값은 0입니다 하면 indexOf() 및 lastIndexOf() 메서드가 -1 반환하고 ~-1 === 0 반환하기 때문입니다. 즉, ~ 사용하는 것은 쿼리 결과가 -1 아닌 경우에만 적용됩니다. 따라서 다음과 같이 할 수 있습니다.
let str = "google google";if(~indexOf('google',str)){
...} 일반적으로 구문 특성이 명확하게 반영될 수 없는 구문은 사용하지 않는 것이 좋습니다. 이는 가독성에 영향을 미치기 때문입니다. 다행스럽게도 위의 코드는 이전 버전의 코드에만 나타납니다. 이전 코드를 읽을 때 모든 사람이 혼동하지 않도록 여기에 언급합니다.
보충:
~는 비트 부정 연산자입니다. 예를 들어 십진수2의 이진수 형식은0010이고~2의 이진수 형식은1101(보수), 즉-3입니다.간단히 이해하면
~n은-(n+1)과 동일합니다. 예:~2 === -(2+1) === -3
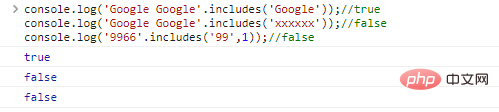
.includes(substr,idx) 는 substr 문자열에 있는지 확인하는 데 사용됩니다. idx 는 쿼리의 시작 위치입니다.
console.log('Google Google'.includes('Google'));//trueconsole.log( 'Google Google'.include('xxxxxx'));//falseconsole.log('9966'.includes('99',1));//false 코드 실행 결과:
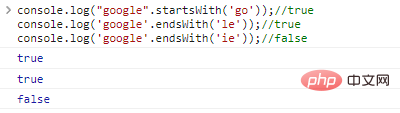
.startsWith('substr') 및 .endsWith('substr') 각각 문자열이 substr 로 시작하는지 아니면 끝나는지를 결정합니다.
console.log("google".startsWith('go'));//trueconsole.log('google' .endsWith('le'));//trueconsole.log('google'.endsWith('ie'));//false 코드 실행 결과:
.substr() , .substring() , .slice() 는 모두 문자열의 하위 문자열을 가져오는 데 사용되지만 사용법은 다릅니다.
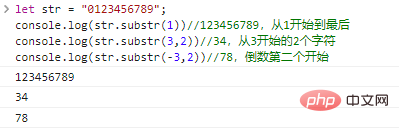
.substr(start,len)
start 부터 시작하는 len 문자로 구성된 문자열을 반환합니다. len 생략하면 원래 문자열의 끝까지 가로채게 됩니다. start 음수일 수 있으며 뒤에서 앞으로 start 문자를 나타냅니다.
let str = "0123456789";console.log(str.substr(1))//123456789, 1부터 끝까지 console.log(str.substr(3,2))//34, 2부터 3자 console.log(str.substr(-3,2))//78, 두 번째 시작
코드 실행 결과:
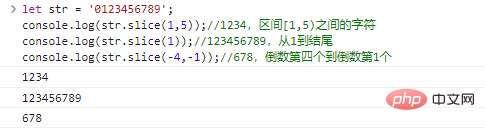
.slice(start,end)
start 에서 시작하여 end 에서 끝나는 문자열(제외)을 반환합니다. start 및 end 에서 두 번째 start/end 문자를 나타내는 음수일 수 있습니다.
let str = '0123456789';console.log(str.slice(1,5));//1234, 간격 [1,5) 사이의 문자 console.log(str.slice(1));//123456789 , 1부터 끝까지 console.log(str.slice(-4,-1));//678, 네 번째에서 마지막
코드 실행 결과:
.substring(start,end)
.slice() 와 거의 동일합니다. 차이점은 두 가지입니다.
end > start 허용되지0 으로 간주됩니다.
let str = '0123456789'; console.log(str .substring(1,3));//12console.log(str.substring(3,1));//12console.log(str.substring(-1, 3));//012, -1은 Make 0 코드 실행 결과로 처리됩니다
.
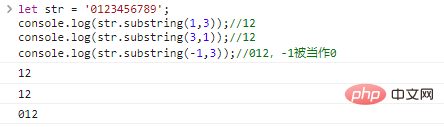
세 가지의 차이점을 비교하십시오.
| 메소드 | 설명 | 매개변수.slice |
|---|---|---|
.slice(start,end) | [start,end) | 는 음수일 수 있습니다.substring |
.substring(start,end) | [start,end) 음수 0 | [start,end) |
.substr(start,len) |
| 부정적인 |
때문에 당연히 선택하기가 어렵습니다. 다른 두 가지보다 더 유연한
.slice()기억하는 것이 좋습니다.
이전 기사에서 문자열 비교에 대해 이미 언급했습니다. 문자열은 각 문자 뒤에 코드가 있으며 ASCII 코드는 중요한 참조입니다.
예:
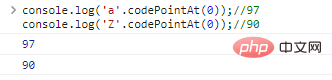
console.log('a'>'Z');// 실제 문자 간의 비교는 본질적으로 문자를 나타내는 인코딩 간의 비교입니다. JavaScript UTF-16 사용하여 문자열을 인코딩합니다. 각 문자는 16 비트 코드입니다. 비교의 특성을 알고 싶다면 .codePointAt(idx) 사용하여 문자 인코딩을 가져와야 합니다
. '.codePointAt( 0));//97console.log('Z'.codePointAt(0));//90 코드 실행 결과:
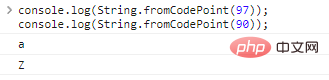
String.fromCodePoint(code) 사용하여 인코딩을 문자로 변환합니다.
console.log(String.fromCodePoint(97));console.log(String.fromCodePoint(90));
코드 실행 결과는 다음과 같습니다.
이 프로세스는 다음과 같이 이스케이프 문자 u 사용하여 수행할 수 있습니다.
console.log('u005a');//Z, 005a는 90 console.log('u0061');//a의 16진수 표기법입니다. 0061 97의 16진수 표기법입니다. [65,220] 범위에 인코딩된 문자를 살펴보겠습니다.
let str = '';for(let i = 65; i<=220; i++){
str+=String.fromCodePoint(i);}console.log(str); 코드 실행 부분의 결과는 다음과 같습니다.

위 사진에는 결과가 모두 나와있지 않으니, 가서 시험해 보세요.
국제 표준 ECMA-402 기반으로 합니다. JavaScript str1.localeCompare(str2) 사용하여 다양한 문자열을 비교하는 특수 메서드( .localeCompare() )를 구현했습니다.
str1 < str2 를 반환합니다.str1 > str2 , 양수를 반환합니다.str1 == str2 이면 0을 반환합니다.예:
console.log("abc".localeCompare('def'));//-1 비교 연산자를 직접 사용하지 않는 이유는 무엇입니까?
이는 영어 문자에 몇 가지 특별한 쓰기 방식이 있기 때문입니다. 예를 들어 á a 의 변형입니다.
console.log('á' < 'z');// false도 a 이지만 z 보다 큽니다. !
이때 .localeCompare() 메소드를 사용해야 합니다:
console.log('á'.localeCompare('z'));//-1 str.trim() 은 앞뒤의 공백 문자를 제거합니다. string, str.trimStart() , str.trimEnd() 시작과 끝의 공백을 삭제합니다.
let str = " 999 "; //999
str.repeat(n) 반복 문자열을 n 번;
let str = ' 6';console.log(str.repeat(3));//666
str.replace(substr,newstr) 첫 번째 하위 문자열을 대체하고, str.replaceAll() 모두를 대체하는 데 사용됩니다. 하위 문자열;
let str = '9 +9';console.log(str.replace('9','6'));//6+9console.log(str.replaceAll('9','6')) ;//6+6은 여전히 다른 방법이 많이 있으며 자세한 내용은 매뉴얼을 참조하세요.
JavaScript 문자열을 인코딩하는 데 UTF-16 사용합니다. 즉, 2바이트( 16 비트)가 한 문자를 나타내는 데 사용됩니다. 따라서 16 비트 데이터는 65536 자만 표현할 수 있습니다. 일반 문자는 당연히 포함되지 않지만, 희귀 문자(한자), emoji , 희귀 수학 기호 등은 부족합니다.
이 경우 특수 문자를 나타내려면 더 긴 숫자( 32 비트)를 확장하고 사용해야 합니다(예:
console.log(''.length);//2console.log('?'.length);//2). 코드 실행 결과:
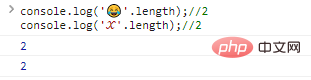
결과적으로 기존 방법으로는 처리할 수 없습니다. 각 바이트를 개별적으로 출력하면 어떻게 되나요?
console.log(''[0]);console.log(''[1]); 코드 실행 결과:
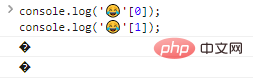
보시다시피 개별 출력 바이트는 인식되지 않습니다.
다행히 String.fromCodePoint() 및 .codePointAt() 메서드는 최근에 추가되었기 때문에 이 상황을 처리할 수 있습니다. 이전 버전의 JavaScript 에서는 String.fromCharCode() 및 .charCodeAt() 메서드만 사용하여 인코딩과 문자를 변환할 수 있지만 특수 문자에는 적합하지 않습니다.
문자의 인코딩 범위를 판단하여 특수 문자인지 여부를 판단하여 특수 문자를 처리할 수 있습니다. 문자 코드가 0xd800~0xdbff 사이에 있으면 32 비트 문자의 첫 번째 부분이고 두 번째 부분은 0xdc00~0xdfff 사이에 있어야 합니다.
예:
console.log(''.charCodeAt(0).toString(16));//d83
dconsole.log('?'.charCodeAt(1).toString(16));//de02 코드 실행 결과:

영어에는 문자 기반 변형이 많이 있습니다. 예를 들어 문자 a àáâäãåā 의 기본 문자일 수 있습니다. 변형 조합이 너무 많기 때문에 이러한 변형 기호가 모두 UTF-16 인코딩에 저장되지는 않습니다.
모든 변형 조합을 지원하기 위해 여러 Unicode 문자를 사용하여 단일 변형 문자를 나타냅니다. 프로그래밍 프로세스 중에 기본 문자와 "장식 기호"를 사용하여 특수 문자를 표현할 수 있습니다:
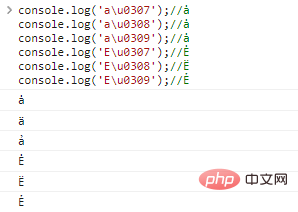
console.log('au0307 ' );//১
console.log('au0308');//å
console.log('au0309');//å
console.log('Eu0307');//Ė
console.log('Eu0308');//E
console.log('Eu0309');//Ẻ코드 실행 결과:
기본 문자에는 여러 장식이 있을 수도 있습니다. 예:
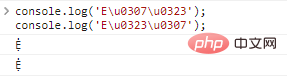
console.log('Eu0307u0323');//Ẹ̇
console.log('Eu0323u0307');//Ẹ̇코드 실행 결과:
여기서 문제가 되는 것은 장식이 여러 개인 경우 장식의 순서가 다르지만 실제로 표시되는 문자는 동일하다는 것입니다.
이 두 표현을 직접 비교하면 잘못된 결과를 얻게 됩니다.
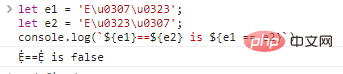
let e1 = 'Eu0307u0323';
e2 = 'Eu0323u0307';
console.log(`${e1}==${e2} is ${e1 == e2}`) 코드 실행 결과:
이 상황을 해결하기 위해 문자열을 범용 형식으로 변환할 수 있는 ** Unicode 정규화 알고리즘이 있으며, 이는 str.normalize() 로 구현됩니다.
let e1 = 'Eu0307u0323';
e2 = 'Eu0323u0307';
console.log(`${e1}==${e2}는 ${e1.normalize() == e2.normalize()}`)
코드 실행 결과:

[관련 권장사항: JavaScript 비디오 튜토리얼, 웹 프론트엔드]
위는 JavaScript 문자열의 일반적인 기본 방법에 대한 자세한 내용이며, 자세한 내용은 PHP 중국어 웹사이트의 다른 관련 기사를 참고하세요!