이전 섹션에서 웹페이지의 모든 정보를 크롤링했습니다. 이제 html 코드에서 필요한 콘텐츠를 찾아야 합니다. 따라서 문제에 따라 웹사이트에 들어가 웹페이지의 정보를 구문 분석해야 합니다.
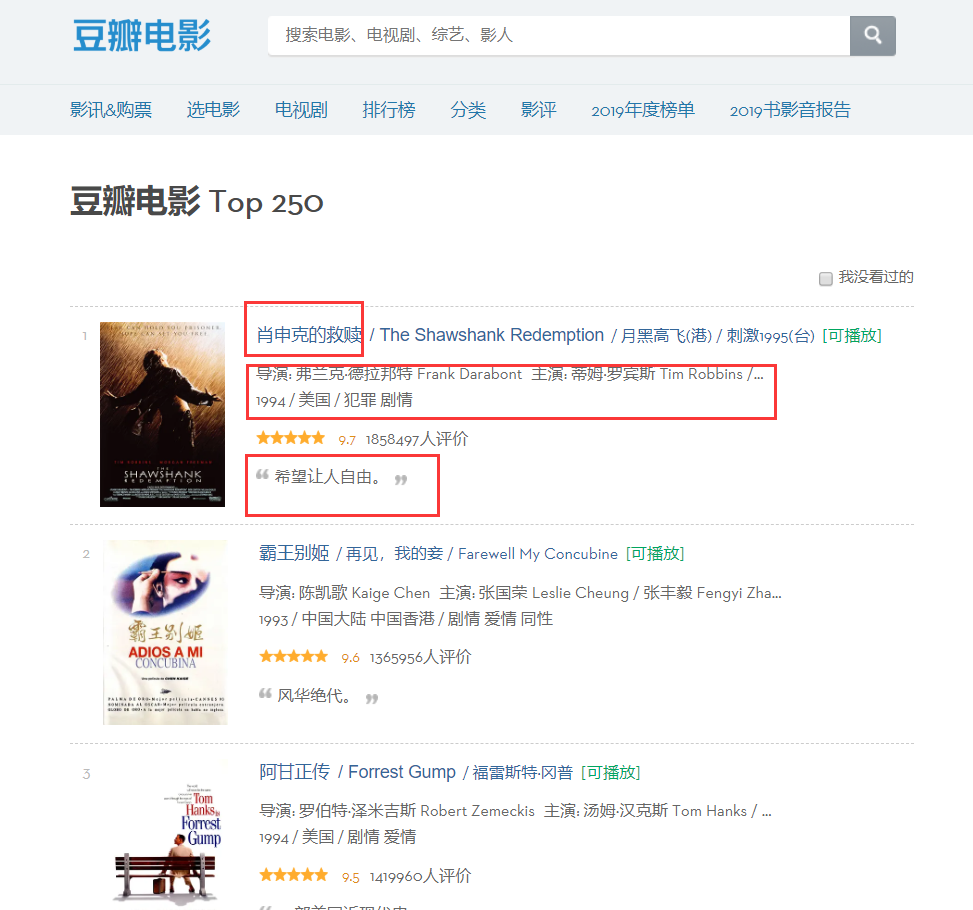
크롤링해야 할 정보가 서로 다른 파티션에 존재한다는 것을 페이지에서 확인할 수 있으므로 페이지의 요소를 확인하고 페이지를 마우스 오른쪽 버튼으로 클릭하여 웹 페이지 소스 코드를 확인하거나 F12를 누릅니다.

웹 페이지를 분석하기 전에 먼저 구문 분석 후 저장 방법을 지정합니다. 여기서는 목록을 사용하여 모든 정보를 저장한 다음 목록의 각 항목은 사전에 해당하고 각 사전은 여러 유형의 정보에 해당합니다.
movie=[]#먼저 모든 정보를 저장할 목록을 정의합니다.
분석을 통해 제목의 위치가 'hd'라는 'div' 아래 첫 번째 'a'의 첫 번째 'span'임을 확인할 수 있으므로 다음 코드를 통해 각 영화의 이름을 잠글 수 있으며, 사전에.
moviename=each.find('div',class_='hd').a.span.text.strip()movie['title']=moviename#사전에 있는 항목마찬가지로 감독 이름의 소스코드도 포지셔닝을 기준으로 찾을 수 있는데, 이 소스코드에는 많은 정보가 포함되어 있기 때문에 정규식을 통해 필터링해야 합니다.
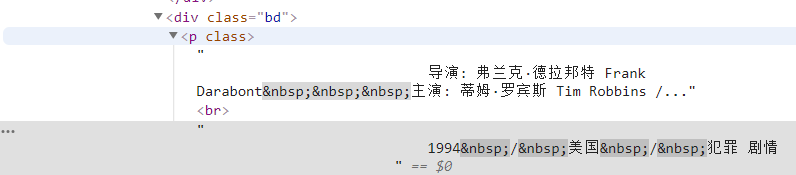
info=each.find('div',class_='bd').p.text.strip()먼저 이 태그 아래의 모든 콘텐츠를 찾은 다음 정규식을 통해 관련 없는 정보를 필터링합니다.
info=info.replace('n',)#캐리지 반환 필터링 info=info.replace(,)#공백 필터링 info=info.replace(xa0,)#줄바꿈하지 않는 공백 문자 필터링 Director=re.findall( r '[감독:].+[주연:]',info)[0]director=감독[3:len(감독)-6]그런 다음 사전의 항목으로 정의합니다.
movie['director']=director#사전에 있는 항목
영화 유형도 이 'p' 태그에 있음을 알 수 있으며 정규 표현식을 통해 이 정보를 직접 얻을 수도 있습니다.
줄거리=re.findall(r'[0-9]*[/].+[/].+',info)[0]plot=plot[1:]plot=plot[plot.index('/') +1:]plot=plot[plot.index('/')+1:]movie['plot']=plot#사전에 항목으로 추가마지막으로 등급 정보를 잠급니다.
star=each.find('div',class_='star')star=star.find('span',class_=' rating_num').text.strip()그런 다음 계속해서 사전 형태로 저장합니다.
영화['스타']=스타
마지막으로 이 사전을 목록에 추가하고 출력을 반복합니다.
Movies.append(movie)#목록에 사전을 추가합니다. foriinmovies:#출력을 탐색합니다. print(i)
importreimportrequestsfrombs4importBeautifulSoupforiinrange(1):headers={# 'user-agent'에 액세스하기 위한 브라우저 시뮬레이션:'Mozilla/5.0(WindowsNT6.1;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/52.0.2743.82Safari/537.36' , '호스트':'movie.douban.com'}res='https://movie.douban.com/top250?start='+str(25*i)#25회 r=requests.get(res,headers = headers,timeout=10)#타임아웃 설정 수프=BeautifulSoup(r.text,html.parser)#파싱 방법을 설정합니다. 다른 방법도 사용할 수 있습니다. div_list=soup.find_all('div',class_='item')movies=[]foreachindiv_list:movie={}moviename=each.find('div',class_='hd').a.span.text.strip ()movie['title']=movienamerank=each.find('div',class_='pic').em.text.strip()movie['rank']=rankinfo=each.find('div', class_='bd').p.text.strip()info=info.replace('n',)info=info.replace(,)info=info.replace(xa0,)director=re.findall( r'[감독:].+[주연:]',info)[0]director=director[3:len(director)-6]movie['director']=directorrelease_date=re.findall(r'[0- 9]{4}',info)[0]영화['release_date']=release_dateplot=re.findall(r'[0-9]*[/].+[/].+',info)[0] 플롯=플롯[1:]플롯=플롯[plot.index('/')+1:]플롯=플롯[plot.index('/')+1:]영화['플롯']=plotstar=각. find('div',class_='star')star=star.find('span',class_=' rating_num').text.strip()movie['star']=starmovies.append(movie)foriinmovies:print (나)콘솔:

이 예에서는 주로 웹 페이지의 소스 코드에서 해당 정보를 찾는 방법을 배웁니다. BeautifulSoup을 사용하면 해당 정보를 빠르게 찾은 다음 정규 표현식과 결합하여 정보 일치를 완료할 수 있습니다. 이 데이터를 데이터베이스에 저장합니다.