이전 섹션에서는 사전 방법에 대해 배웠습니다. 이번 장에서는 하이브리드 사전, 사전 순회 및 사전 파생에 대해 알아봅니다.
소위 혼합 사전은 사전에 저장된 데이터가 다양한 유형이 혼합되어 있음을 의미합니다. 키는 불변 데이터 유형이어야 하지만 값은 모든 유형의 객체가 될 수 있습니다.
먼저 혼합 사전을 살펴보겠습니다.
my_dcit={'샤오밍': ['키: 170cm', '체중: 65kg'], '샤오리': '배움을 사랑하고 스포츠를 사랑합니다', '샤오화': ('거주지:쑤저우', '출생지:상하이 ')}이 사전의 값은 목록, 문자열 및 튜플로 구성됩니다. 이전 섹션의 방법을 통해 이 혼합 사전에 액세스할 수 있습니다. 다음 코드를 보세요
my_dcit={'샤오밍': ['키: 170cm', '체중: 65kg'], '샤오리': '배움을 사랑하고 스포츠를 사랑합니다', '샤오화': ('거주지:쑤저우', '출생지:상하이 ')}print('액세스 키='Xiao Ming'->',my_dcit['Xiao Ming'])print('액세스 키='Xiaohua'->',my_dcit['Xiao Li'])print(' 액세스 key='Xiaohua'->',my_dcit['Xiaohua'])print('itmes() 메서드:',my_dcit.items())#전체 액세스 print('keys() 메서드:',my_dcit.keys() )#모든 keyprint('values() 메소드:',my_dcit.values())에만 액세스됨#valueprint('get() 메소드:',my_dcit.get('Xiao Ming'))#get 액세스하기 위한 메소드에만 액세스됨 지정된 키 my_dcit.pop('Xiao Ming') # 이 단계는 pop() 메서드로, key = 'Xiao Ming'과 쌍을 이루는 요소를 삭제합니다. print(' pop() 메서드 뒤의 my_dict: ', my_dcit) # 삭제 후 사전 보기출력을 살펴보십시오.
접속키='샤오밍'->['키: 170cm', '체중: 65kg'] 접속키='샤오화'->배움을 사랑하고 운동을 사랑 접속키='샤오화'->('거주지:쑤저우', '출생지: 상하이') itmes() 메소드: dict_items([('샤오밍', ['키: 170cm', '체중: 65kg']), ('샤오리', '배우기를 좋아하고 스포츠를 좋아함' ), ('Xiaohua',('거주지: 쑤저우', '출생지: 상하이'))])keys() 메서드: dict_keys(['Xiaoming','Xiaoli','Xiaohua'])values () 메서드: dict_values([ ['키: 170cm', '체중: 65kg'], '공부를 좋아하고 운동을 좋아합니다', ('거주지: 쑤저우', '출생지: 상하이')]) get() method :['키: 170cm', ' Weight: 65kg'] my_dict after pop() method: {'Xiao Li': '배우는 것을 좋아하고 스포츠를 좋아합니다', 'Xiaohua': ('거주지: 쑤저우', '출생지: 상하이')}사전을 사용할 때 사전을 순회해야 하는 경우가 종종 있습니다. 일반적으로 사전의 모든 키를 순회하려면 for 루프를 사용합니다.
일반적으로 순회 액세스를 살펴보겠습니다.
>>>my_dict={1001:'Xiaoming',1002:'Xiaohua',1003:'Xiaozhang'}>>>foriinmy_dict:print(i,my_dict[i])#출력 키 및 키에 해당하는 값 1001Xiao Ming 1002 샤오화 1003 샤오장또한 객체를 가져올 때 요소 쌍을 가져오기 위해 items() 메서드를 사용할 것입니다.
>>>my_dict={1001:'샤오밍',1002:'샤오화',1003:'샤오장'}>>>foriinmy_dict.items():print(i)(1001,'샤오밍')(1002 ,'샤오화')(1003,'샤오장')이 접근 방법은 반대 사전에 있는 데이터 쌍이며, 출력 결과는 튜플 형태로 출력됨과 동시에 루프 순회를 통해 각 순회에 대한 키와 값을 직접 얻을 수 있습니다.
>>>my_dict={1001:'샤오밍',1002:'샤오화',1003:'샤오장'}>>>fori,jinmy_dict.items():print('해당 키:',i,'해당 value :',j) 대응키 : 1001 대응값 : Xiao Ming 대응키 : 1002 대응값 : Xiao Hua 대응키 : 1003 대응값 : Xiao Zhang마지막으로 연습을 통해 사전순회를 연습해 보세요.
리스트 파생에 대해서는 이전에 배웠습니다. 튜플 파생은 별다른 소개 없이 리스트 파생과 유사합니다. 왜냐하면 사전은 상대적으로 특별하기 때문입니다. 여기서는 사전 파생을 설명하겠습니다.
먼저 간단한 사용법을 살펴보겠습니다.
>>>my_dict={i:'dotcpp'foriinrange(1,5)}>>>my_dict{1:'dotcpp',2:'dotcpp',3:'dotcpp',4:'dotcpp'}여기서는 사전 파생의 구조를 살펴보겠습니다. 첫 번째 부분은 'dotcpp'를 사용하여 각 i의 값 개체를 할당하는 것과 동일합니다. 먼저 목록을 정의하고 목록의 값을 할당할 수도 있습니다.
>>>my_list=[10,20,30,40,50]>>>my_dict={i:my_list[i]foriinrange(1,5)}>>>my_dict{1:20,2:30,3: 40,4:50}아래 그림을보십시오 :
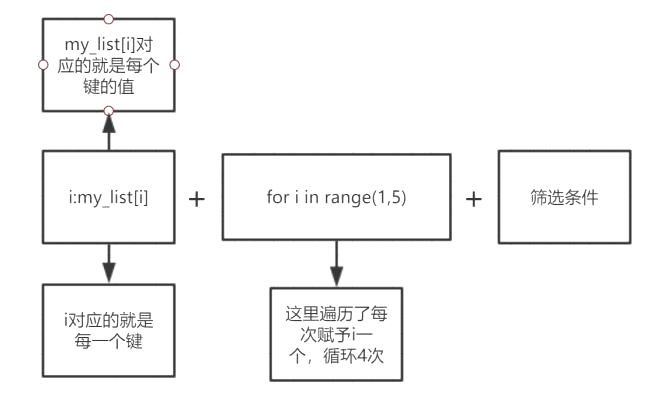
사전 파생을 사용할 때 가장 큰 문제는 키와 값의 일치입니다. 나중에 함수를 배우고 나면 zip() 함수를 사용하여 사전을 더 편리하게 결합할 수 있습니다. 여기서는 이에 대해 너무 많이 소개하지 않겠습니다.
사용자는 총 자산을 입력해야 합니다(예: 3000). 그러면 장바구니 목록이 표시되고 장바구니에 있는 항목의 총 금액이 총 자산보다 큰 경우 계산됩니다. 계정 잔액이 부족하다는 메시지가 표시됩니다. 그렇지 않으면 구매가 성공한 것입니다. 장바구니 목록은 다음과 같습니다: carts=[{name: 침대, 가격: 1999, "num": 1}, {name: 베개, 가격: 10, " num ": 2}, {name: 이불, 가격: 20, " 번호”:1}].
해결책은 끝에 있습니다.
사전은 Python을 학습할 때 비교적 일반적으로 사용되는 데이터 구조입니다. 그러나 그 고유성으로 인해 경쟁 문제에서는 사전에 대한 단어가 상대적으로 적을 수 있지만 Python 강좌 학습 및 검사에서는 사전을 사용하여 도움을 받을 수 있습니다. 해당 데이터를 정확하게 찾고, 목록과 사전을 능숙하게 익히면 Python을 더 잘 배울 수 있습니다.
카트=[{name:bed,price:1999,"num":1},{name:pillow,price:10,"num":2},{name:quilt,price:20,"num":1} ]. m=int(input())sum=0foriinrange(len(carts)):sum=carts[i]['price']*carts[i]['num']+sumifm>=sum:print('구매 성공 ')else:print('계좌 잔고 부족')