과학 연구 효율성 아티팩트 OpenScholar가 출시되어 과학 연구자의 문헌 검토 경험이 완전히 바뀌었습니다! Downcodes의 편집자는 이 AI 기반 과학 연구 도구를 제공합니다. 여기에는 4억 5천만 개의 공개 액세스 논문과 2억 3천 7백만 개의 기사 단락 삽입이 포함되어 있으며 과학 연구 질문과 관련된 문서를 빠르고 정확하게 필터링하고 참조에 대한 완전한 답변을 생성할 수 있습니다. OpenScholar는 강력할 뿐만 아니라 스스로 학습하고 개선할 수 있으며 답변의 질을 지속적으로 향상시켜 궁극적으로 가장 완벽한 과학 연구 결과를 제시할 수 있습니다. 또한 더 작고 더 효율적인 모델을 훈련하는 데 사용할 수 있어 과학 연구 분야에 혁명적인 변화를 가져올 수 있습니다!
문헌을 검토하기 위해 늦게까지 머물고 계십니까? 당황하지 마십시오! AI2의 과학 연구 전문가가 최신 걸작인 OpenScholar를 통해 여러분을 구해 드립니다. 공원을 걷는 것처럼!
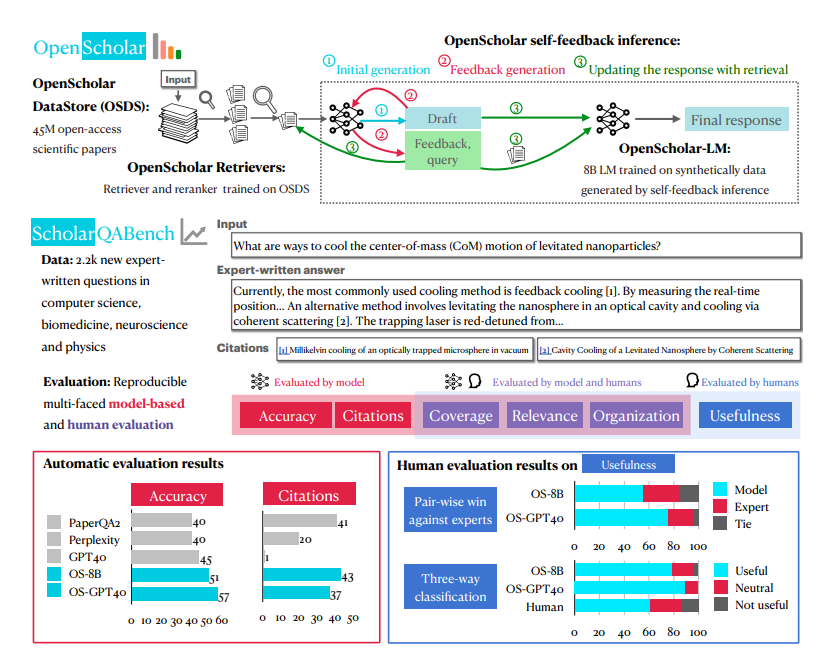
OpenScholar의 가장 큰 비밀 무기는 4억 5천만 개의 오픈 액세스 논문과 2억 3천 7백만 개의 삽입된 기사 문단을 보유한 OpenScholar-Datastore(OSDS)라는 시스템입니다. 이러한 강력한 지식 기반을 통해 OpenScholar는 다양한 과학 연구 문제에 쉽게 대처할 수 있습니다.
과학적 연구 문제가 발생하면 OpenScholar는 먼저 강력한 도구(검색기 및 재정렬기)를 보내 문제와 관련된 기사 단락을 OSDS에서 신속하게 필터링합니다. 다음으로 언어 모델(LM)에는 참조에 대한 완전한 답변이 포함됩니다. 더욱 강력한 점은 OpenScholar가 귀하의 자연어 피드백을 기반으로 답변을 지속적으로 개선하고 귀하가 만족할 때까지 누락된 정보를 보완한다는 것입니다.
OpenScholar는 그 자체로 강력할 뿐만 아니라 더 작고 효율적인 모델을 훈련하는 데도 도움이 됩니다. 연구원들은 OpenScholar의 프로세스를 사용하여 대량의 고품질 교육 데이터를 생성하고 이 데이터를 사용하여 OpenScholar-8B라는 80억 개의 매개변수 언어 모델과 기타 검색 모델을 교육했습니다.
OpenScholar의 전투 효율성을 종합적으로 테스트하기 위해 연구원들은 SCHOLARQABENCH라는 새로운 테스트 경기장도 특별히 만들었습니다. 폐쇄 분류, 객관식, 긴 형식 생성을 포함하여 컴퓨터 과학, 생물의학, 물리학, 신경과학 등 여러 분야를 포괄하는 다양한 과학 문헌 검토 작업이 이 분야에서 설정됩니다. 대회의 공정성과 정의를 보장하기 위해 SCHOLARQABENCH는 전문가 검토, 자동 지표 및 사용자 경험 테스트를 포함한 다각적인 평가 방법도 사용합니다.
여러 차례의 치열한 경쟁 끝에 OpenScholar가 마침내 두각을 나타냈습니다! 실험 결과는 다양한 작업에서 인간 전문가를 능가하는 성능을 보여주었습니다. 이 획기적인 결과는 확실히 과학 연구 분야에 혁명을 일으키고 과학자들에게 작별을 고하게 할 것입니다. 과학의 신비를 탐구하는 데 중점을 둔 문헌 검토 작업!
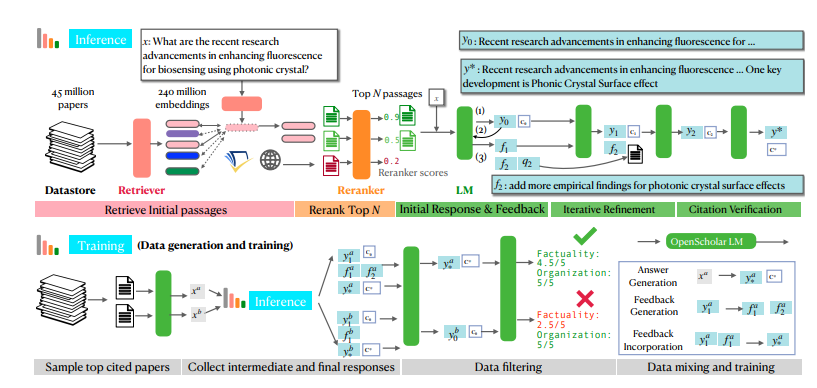
OpenScholar의 강력한 기능은 주로 고유한 자체 피드백 검색 강화 추론 메커니즘의 이점을 활용합니다. 간단히 말하면, 먼저 스스로에게 질문을 던지고, 자신의 답변을 바탕으로 지속적으로 답변을 개선하고, 최종적으로 가장 완벽한 답변을 제시합니다. 놀랍지 않나요?
구체적으로 OpenScholar의 셀프 피드백 추론 과정은 초기 답변 생성, 피드백 생성, 피드백 통합의 세 단계로 나누어집니다. 첫째, 언어 모델은 검색된 기사 구절을 기반으로 초기 답변을 생성합니다. 그런 다음 엄격한 심사관처럼 답변을 스스로 비판하고 단점을 식별하며 "답변에는 질문 및 답변 작업에 대한 실험 결과만 포함되어 있습니다. 다른 유형의 작업 결과를 보완해 주세요."와 같은 자연어 피드백을 생성합니다. . 마지막으로 언어 모델은 이 피드백을 기반으로 관련 문헌을 다시 검색하고 모든 정보를 통합하여 보다 완전한 답변을 생성합니다.
더 작지만 똑같이 강력한 모델을 훈련하기 위해 연구원들은 OpenScholar의 자체 피드백 추론 프로세스를 사용하여 대량의 고품질 훈련 데이터를 생성했습니다. 그들은 먼저 데이터베이스에서 가장 많이 인용된 논문을 선택한 다음 이러한 논문의 초록을 기반으로 몇 가지 정보 질의 질문을 생성하고 마지막으로 OpenScholar의 추론 프로세스를 사용하여 고품질 답변을 생성했습니다. 이러한 답변과 그 과정에서 생성되는 피드백 정보는 귀중한 훈련 데이터를 구성합니다. 연구원들은 이 데이터를 기존 일반 도메인 명령어 미세 조정 데이터 및 과학 도메인 명령어 미세 조정 데이터와 혼합하여 OpenScholar-8B라는 80억 개의 매개변수 언어 모델을 훈련했습니다.
OpenScholar 및 기타 유사한 모델의 성능을 보다 완벽하게 평가하기 위해 연구원들은 SCHOLARQABENCH라는 새로운 벤치마크도 만들었습니다. 이 벤치마크에는 컴퓨터 과학, 물리학, 생물의학, 신경과학 등 4개 분야의 전문가가 작성한 2,967개의 문헌 검토 질문이 포함되어 있습니다. 각 질문에는 전문가가 작성한 긴 답변이 있으며, 각 답변을 완료하는 데 평균적으로 전문가가 약 1시간이 걸립니다. SCHOLARQABENCH는 또한 모델에서 생성된 답변의 품질에 대한 보다 포괄적인 측정을 제공하기 위해 자동화된 측정항목과 수동 평가를 결합하는 다면적인 평가 접근 방식을 사용합니다.
실험 결과에 따르면 SCHOLARQABENCH의 OpenScholar 성능은 다른 모델을 훨씬 능가하고 일부 측면에서는 인간 전문가를 능가합니다. 예를 들어 컴퓨터 과학 분야에서 OpenScholar-8B의 정확도는 GPT-4o보다 5% 더 높습니다. PaperQA2는 GPT-4o보다 7% 더 높습니다. 또한 OpenScholar에서 생성된 답변의 인용 정확도는 인간 전문가의 정확도와 비슷하지만 GPT-4o는 78-90% 허공에서 조작되었습니다.
OpenScholar의 출현은 의심할 여지 없이 과학 연구 분야에 큰 도움이 됩니다. 이는 과학 연구자들이 많은 시간과 에너지를 절약하는 데 도움이 될 뿐만 아니라 문헌 검토의 품질과 효율성도 향상시킬 수 있습니다. 저는 가까운 미래에 OpenScholar가 과학 연구자들에게 없어서는 안 될 조력자가 될 것이라고 믿습니다!
논문 주소: https://arxiv.org/pdf/2411.14199
프로젝트 주소: https://github.com/AkariAsai/OpenScholar
전체적으로 OpenScholar는 강력한 기능과 효율적인 성능을 통해 과학 연구자들에게 전례 없는 편의성을 제공하고 과학 연구 효율성을 크게 향상시켰습니다. 이는 도구일 뿐만 아니라 과학 연구 분야의 혁명이기도 합니다. 앞으로의 개발과 적용을 기대해볼 가치가 있습니다.