다운코드 편집자가 프린스턴 대학교와 예일 대학교의 최신 연구 결과를 설명해 드립니다! 본 연구는 대규모 언어 모델(LLM)의 "CoT(사상 사슬)" 추론 기능을 깊이 탐구하여 CoT 추론이 단순히 논리적 규칙을 적용하는 것이 아니라 기억, 확률, 논리 등 여러 요소의 복잡한 융합임을 보여줍니다. 소음 추론. 연구진은 교대 암호 해독 작업을 선택하고 GPT-4, Claude3, Llama3.1 세 가지 LLM에 대한 심층 분석을 수행했으며, 마지막으로 CoT 추론 효과에 영향을 미치는 세 가지 핵심 요소를 발견하고 LLM의 추론 메커니즘을 제안했습니다. 새로운 통찰력.
프린스턴 대학과 예일 대학의 연구자들은 최근 LLM(대형 언어 모델)의 "CoT(사상 사슬)" 추론 능력에 대한 보고서를 발표하여 CoT 추론의 비밀을 밝혔습니다. CoT 추론은 단순히 논리적 규칙에 기반한 상징적 추론이 아니라, 이는 메모리, 확률, 노이즈 추론과 같은 여러 요소를 결합합니다.
연구원들은 교대 암호 해독을 테스트 작업으로 사용하고 GPT-4, Claude3 및 Llama3.1의 세 가지 LLM 성능을 분석했습니다. 시프트 암호는 각 문자를 알파벳에서 고정된 숫자만큼 앞으로 이동한 문자로 대체하는 간단한 인코딩입니다. 예를 들어, 알파벳을 3자리 앞으로 이동하면 CAT는 FDW가 됩니다.
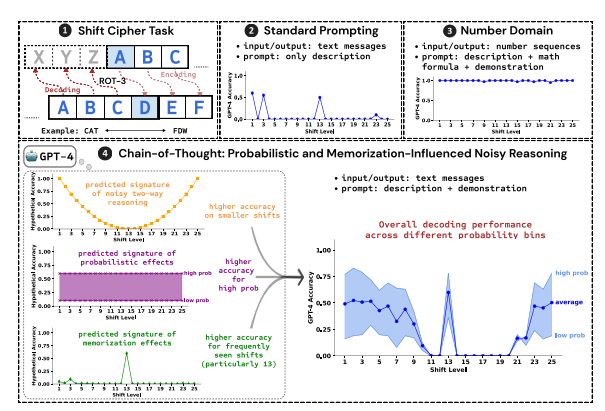
연구 결과에 따르면 CoT 추론 효과에 영향을 미치는 세 가지 주요 요소는 다음과 같습니다.
확률적: LLM은 추론 단계에서 더 낮은 확률의 답변이 나오더라도 더 높은 확률의 출력을 생성하는 것을 선호합니다. 예를 들어 추론 단계가 STAZ를 가리키지만 STAY가 더 일반적인 단어인 경우 LLM은 "자체 수정"하여 STAY를 출력할 수 있습니다.
메모리: LLM은 사전 학습 중에 대량의 텍스트 데이터를 기억하며 이는 CoT 추론의 정확성에 영향을 미칩니다. 예를 들어, rot-13은 가장 일반적인 시프트 암호이며, rot-13에 대한 LLM의 정확도는 다른 유형의 시프트 암호보다 훨씬 높습니다.
노이즈 추론: LLM의 추론 프로세스는 완전히 정확하지는 않지만 어느 정도 노이즈가 있습니다. 시프트 암호의 시프트 양이 증가함에 따라 디코딩에 필요한 중간 단계도 증가하고 잡음 추론의 영향이 더욱 분명해지며 LLM의 정확도가 감소합니다.
연구원들은 또한 LLM의 CoT 추론이 자체 조건화에 의존한다는 사실을 발견했습니다. 즉, LLM은 후속 추론 단계의 컨텍스트로 텍스트를 명시적으로 생성해야 합니다. LLM에 텍스트를 출력하지 않고 "조용히 생각"하도록 지시하면 추론 능력이 크게 저하됩니다. 또한 시연 단계의 효율성은 CoT 추론에 거의 영향을 미치지 않습니다. 시연 단계에 오류가 있더라도 LLM의 CoT 추론 효과는 여전히 안정적으로 유지될 수 있습니다.
본 연구는 LLM의 CoT 추론이 완벽한 상징적 추론이 아니라 기억, 확률, 잡음 추론과 같은 여러 요소를 통합하고 있음을 보여줍니다. LLM은 CoT 추론 과정에서 메모리 마스터와 확률 마스터의 특성을 모두 보여줍니다. 이 연구는 LLM의 추론 기능을 더 깊이 이해하는 데 도움이 되며 향후 더욱 강력한 AI 시스템을 개발하기 위한 귀중한 통찰력을 제공합니다.
논문 주소: https://arxiv.org/pdf/2407.01687
이 연구 보고서는 대규모 언어 모델의 '사고 사슬' 추론 메커니즘을 이해하는 데 귀중한 참고 자료를 제공하고 미래 AI 시스템의 설계 및 최적화를 위한 새로운 방향을 제시합니다. Downcodes의 편집자는 인공 지능 분야의 최첨단 개발에 계속해서 관심을 기울이고 더욱 흥미로운 콘텐츠를 제공할 것입니다!