Downcodes의 편집자는 중국 연구팀이 최대 규모의 공개 다중 모드 AI 데이터 세트인 "Infinity-MM"을 성공적으로 생성했으며 이 데이터 세트를 기반으로 뛰어난 성능으로 소형 모델 Aquila-VL-2B를 훈련했다는 사실을 알게 되었습니다. 이 모델은 여러 벤치마크 테스트에서 탁월한 결과를 얻었으며, AI 모델의 성능을 향상시키는 데 있어 합성 데이터의 엄청난 잠재력을 입증했습니다. Infinity-MM 데이터 세트에는 이미지 설명, 시각적 지시 데이터 등 다양한 유형의 데이터가 포함되어 있습니다. 생성 프로세스는 RAM++ 및 MiniCPM-V와 같은 오픈 소스 AI 모델을 활용하고 데이터 품질과 다양성을 보장하기 위해 다단계 처리를 거칩니다. Aquila-VL-2B 모델은 LLaVA-OneVision 아키텍처를 기반으로 하며 Qwen-2.5를 언어 모델로 사용합니다.
최근 여러 중국 기관의 연구팀은 현재 최대 규모의 공개 다중 모드 AI 데이터 세트 중 하나인 "Infinity-MM" 데이터 세트를 성공적으로 생성하고 뛰어난 성능을 갖춘 작은 새 모델인 —Aquila-VL-2B를 훈련했습니다. .
데이터 세트에는 주로 1,000만 개의 이미지 설명, 2,440만 개의 일반 시각적 지침 데이터, 600만 개의 선별된 고품질 지침 데이터, GPT-4 및 기타 AI 모델에서 생성된 300만 개의 데이터 등 4가지 주요 데이터 범주가 포함되어 있습니다.
세대 측면에서 연구팀은 기존 오픈소스 AI 모델을 활용했습니다. 먼저 RAM++ 모델은 이미지를 분석하고 중요한 정보를 추출한 후 관련 질문과 답변을 생성합니다. 또한 팀은 생성된 데이터의 품질과 다양성을 보장하기 위해 특별한 분류 시스템을 구축했습니다.
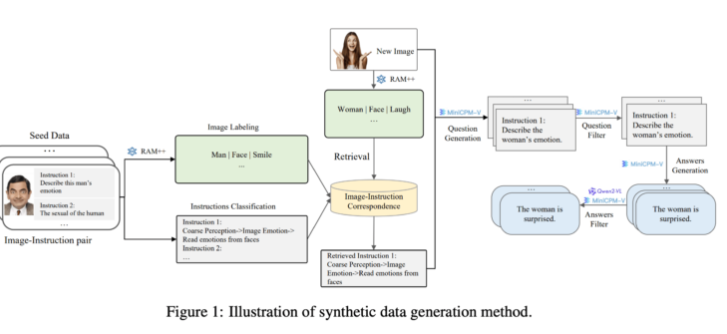
이 합성 데이터 생성 방법은 RAM++와 MiniCPM-V 모델을 결합한 다단계 처리 방법을 사용하여 이미지 인식, 명령 분류 및 응답 생성을 통해 AI 시스템에 대한 정확한 훈련 데이터를 제공합니다.
Aquila-VL-2B 모델은 LLaVA-OneVision 아키텍처를 기반으로 하며 Qwen-2.5를 언어 모델로 사용하고 이미지 처리를 위해 SigLIP을 사용합니다. 모델 훈련은 4단계로 나누어져 점차 복잡도가 높아집니다. 첫 번째 단계에서 모델은 기본적인 이미지-텍스트 연관성을 학습하고, 후속 단계에는 일반적인 비전 작업, 특정 명령 실행, 마지막으로 합성된 생성 데이터의 통합이 포함됩니다. 훈련 중에 이미지 해상도도 점차 향상됩니다.
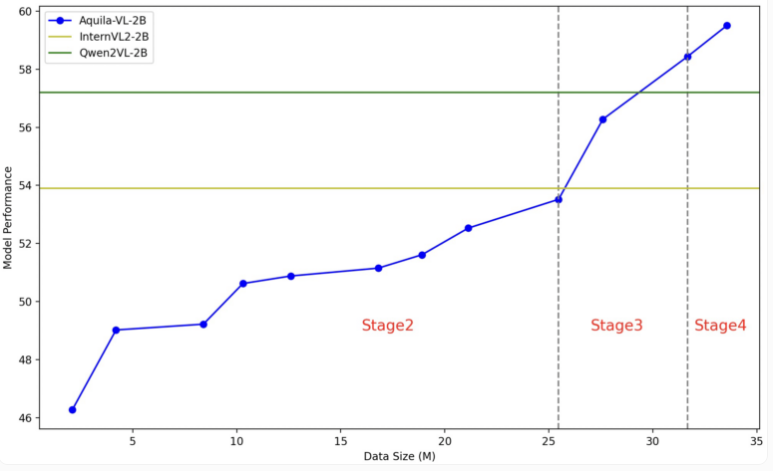
테스트에서 Aquila-VL-2B는 다중 모달 MMStar 기반 테스트에서 단 20억 개의 매개변수로 54.9%의 점수로 최고의 결과를 달성했습니다. 또한 이 모델은 MathVista 테스트에서 59%를 기록하여 유사한 시스템을 훨씬 능가하는 수학 작업에서 특히 좋은 성능을 보였습니다.
일반 이미지 이해 테스트에서도 Aquila-VL-2B는 HallusionBench 점수 43%, MMBench 점수 75.2%로 좋은 성능을 보였습니다. 연구원들은 합성으로 생성된 데이터를 추가하면 모델 성능이 크게 향상되었다고 말했습니다. 이 추가 데이터를 사용하지 않았다면 모델의 평균 성능이 2.4% 떨어졌을 것입니다.
이번에 연구팀은 데이터 세트와 모델을 연구 커뮤니티에 공개하기로 결정했습니다. 훈련 과정은 주로 Nvidia A100GPU와 중국 로컬 칩을 사용했습니다. Aquila-VL-2B의 성공적인 출시는 오픈 소스 모델이 AI 연구에서 전통적인 폐쇄 소스 시스템의 추세를 점차 따라가고 있음을 의미하며, 특히 합성 훈련 데이터 활용에 있어 좋은 전망을 보여줍니다.
Infinity-MM 논문 입구: https://arxiv.org/abs/2410.18558
Aquila-VL-2B 프로젝트 입구: https://huggingface.co/BAAI/Aquila-VL-2B-llava-qwen
Aquila-VL-2B의 성공은 AI 분야에서 중국의 기술적 강점을 입증할 뿐만 아니라 오픈 소스 커뮤니티에 귀중한 리소스를 제공합니다. 효율적인 성능과 개방형 전략은 멀티모달 AI 기술의 발전을 촉진할 것이며, 향후 더 많은 분야에서 활용될 것으로 기대됩니다.