다중 모드 대형 언어 모델(MLLM)에서는 매우 긴 비디오 이해가 항상 어려운 문제였습니다. 기존 모델은 최대 컨텍스트 길이를 초과하는 비디오 데이터를 처리하기 어렵고 정보 감쇠 및 높은 계산 비용도 주요 과제였습니다. Downcodes의 편집자는 Zhiyuan 연구소와 여러 대학에서 시간 수준의 비디오 이해 문제를 효율적으로 처리하도록 설계된 Video-XL이라는 매우 긴 시각적 언어 모델을 제안했다는 사실을 알게 되었습니다. 이 모델의 핵심 기술은 "시각적 컨텍스트 잠재 요약"입니다. 이는 LLM의 컨텍스트 모델링 기능을 교묘하게 활용하여 소 한 마리를 쇠고기 본질 한 그릇에 압축하는 것과 유사하게 긴 시각적 표현을 보다 컴팩트한 형태로 압축하여 모델을 만듭니다. 더 효율적으로 주요 정보를 흡수합니다.
현재 MLLM(Multimodal Large Language Model)은 비디오 이해 분야에서 상당한 진전을 이루었지만 매우 긴 비디오를 처리하는 것은 여전히 어려운 과제입니다. 이는 MLLM이 일반적으로 최대 컨텍스트 길이를 초과하는 수천 개의 시각적 토큰을 처리하는 데 어려움을 겪고 토큰 집계로 인한 정보 붕괴로 인해 어려움을 겪기 때문입니다. 동시에, 비디오 태그 수가 많으면 계산 비용도 높아집니다.
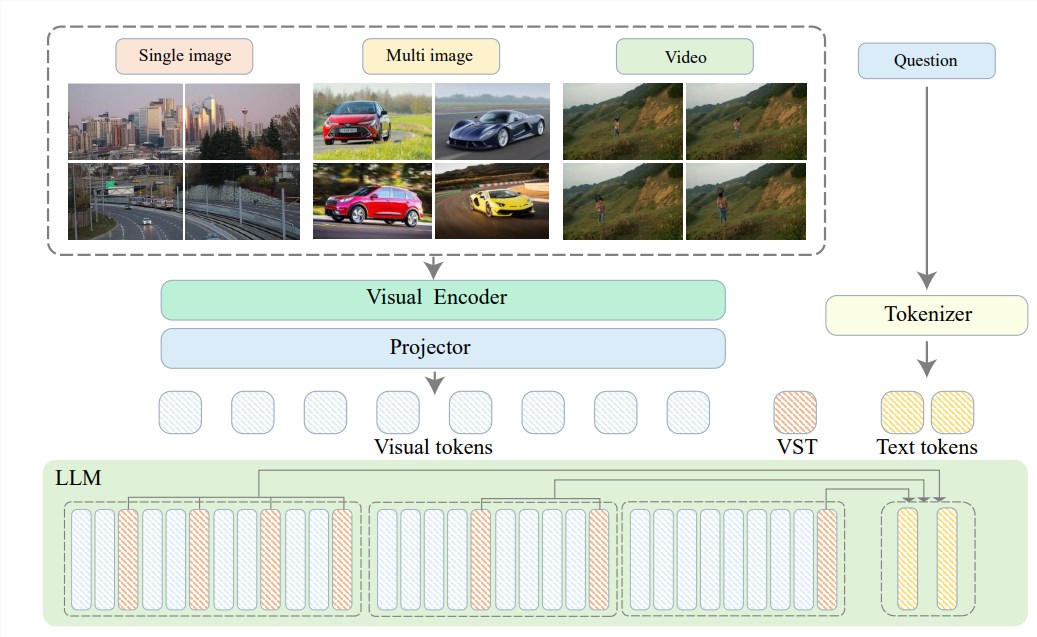
이러한 문제를 해결하기 위해 Zhiyuan 연구소는 Shanghai Jiao Tong University, 중국 인민 대학교, Peking University, Beijing University of Posts and Telecommunications 및 기타 대학과 팀을 이루어 초고화질 시스템인 Video-XL을 제안했습니다. 효율적인 시간 수준 비디오 이해 긴 시각적 언어 모델. Video-XL의 핵심은 LLM의 고유한 컨텍스트 모델링 기능을 활용하여 긴 시각적 표현을 보다 컴팩트한 형식으로 효과적으로 압축하는 "시각적 컨텍스트 잠재 요약" 기술에 있습니다.
쉽게 말하면, 마치 소 한 마리를 쇠고기 진액 한 그릇에 담는 것처럼, 영상 콘텐츠를 좀 더 유선형적인 형태로 압축해 모델이 소화하고 흡수하기 쉽게 하는 것입니다.
이러한 압축 기술은 효율성을 향상시킬 뿐만 아니라 영상의 주요 정보를 효과적으로 보존합니다. 아시다시피, 긴 동영상은 노부인의 족보처럼 길고 냄새나는 중복된 정보로 가득 차 있는 경우가 많습니다. Video-XL은 이러한 불필요한 정보를 정확하게 제거하고 필수 부분만 유지하므로 긴 비디오 콘텐츠를 이해할 때 모델이 길을 잃지 않도록 보장합니다.
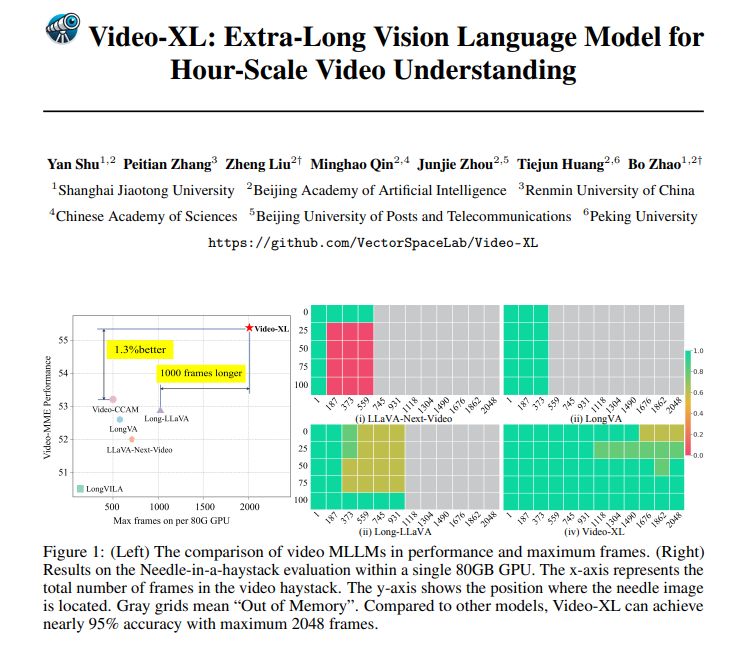
Video-XL은 이론적으로 훌륭할 뿐만 아니라 실제로도 매우 유능합니다. Video-XL은 여러 개의 긴 비디오 이해 벤치마크, 특히 VNBench 테스트에서 최고의 결과를 얻었으며 정확도는 기존 최고의 방법보다 거의 10% 더 높습니다.
더욱 인상적인 점은 Video-XL이 단일 80GB GPU에서 2048 프레임의 비디오를 처리하는 동시에 "건초 더미 속의 바늘" 평가에서 거의 95%의 정확도를 유지할 수 있어 효율성과 효율성 사이에서 놀라운 균형을 이루고 있다는 것입니다.
Video-XL은 또한 광범위한 응용 가능성을 가지고 있습니다. 일반적인 장편 영상을 이해할 수 있을 뿐만 아니라 영화 요약, 감시 이상 탐지, 광고 게재 위치 인식 등 특정 작업도 수행할 수 있습니다.
이는 앞으로 영화를 볼 때 더 이상 긴 줄거리를 참을 필요가 없다는 것을 의미합니다. Video-XL을 직접 사용하여 간소화된 요약을 생성하여 시간과 노력을 절약하거나 감시 영상을 모니터링하고 비정상적인 이벤트를 자동으로 식별할 수 있습니다. , 이는 수동 추적보다 훨씬 효율적입니다.
프로젝트 주소: https://github.com/VectorSpaceLab/Video-XL
논문: https://arxiv.org/pdf/2409.14485
Video-XL은 초장편 영상 이해 분야에서 획기적인 발전을 이루었습니다. 효율성과 정확성의 완벽한 조합은 장편 영상 처리를 위한 새로운 솔루션을 제공하며 앞으로 폭넓은 응용 가능성을 기대해 볼 가치가 있습니다.