Downcodes의 편집자는 Peking University와 기타 과학 연구팀이 랜드마크 다중 모드 오픈 소스 모델인 LLaVA-o1을 출시했다는 사실을 알게 되었습니다. 이 모델은 여러 벤치마크 테스트에서 Gemini, GPT-4o-mini 및 Llama와 같은 경쟁사를 능가했으며 "느린 사고" 추론 메커니즘을 통해 GPT-o1에 필적하는 더 복잡한 추론을 수행할 수 있었습니다. LLaVA-o1의 오픈 소스는 다중 모드 AI 분야의 연구 및 응용에 새로운 활력을 불어넣을 것입니다.
최근 북경대학교 등 과학 연구팀은 GPT-o1에 필적할 만큼 자연스럽고 체계적인 추론이 가능한 최초의 시각적 언어 모델인 LLaVA-o1이라는 다중 모드 오픈 소스 모델을 출시했다고 발표했습니다.
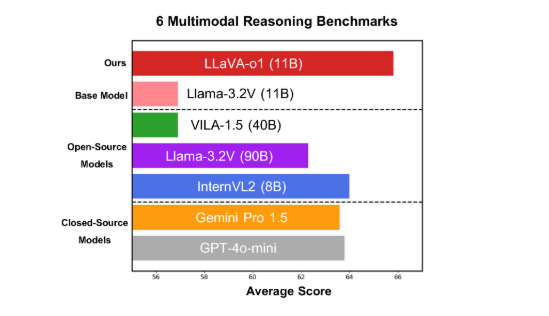
이 모델은 11B 매개변수 버전이 Gemini-1.5-pro, GPT-4o-mini 및 Llama-3.2-90B-Vision-Instruct와 같은 다른 경쟁사보다 뛰어난 6가지 까다로운 다중 모드 벤치마크에서 좋은 성능을 발휘합니다.
LLaVA-o1은 Llama-3.2-Vision 모델을 기반으로 하며 "느린 사고" 추론 메커니즘을 채택하여 전통적인 사고 체인 프롬프트 방법을 능가하여 더 복잡한 추론 프로세스를 독립적으로 수행할 수 있습니다.
다중 모드 추론 벤치마크에서 LLaVA-o1은 기본 모델보다 8.9% 더 나은 성능을 보였습니다. 이 모델은 추론 프로세스가 요약, 시각적 설명, 논리적 추론 및 결론 생성의 4단계로 나누어져 있다는 점에서 독특합니다. 기존 모델에서는 추론 프로세스가 상대적으로 단순하고 쉽게 오답으로 이어질 수 있는 반면, LLaVA-o1은 구조화된 다단계 추론을 통해 보다 정확한 출력을 보장합니다.
예를 들어 "밝고 작은 공과 보라색 물체를 모두 빼고 나면 몇 개의 물체가 남나요?"라는 문제를 해결할 때 LLaVA-o1은 먼저 문제를 요약한 다음 이미지에서 정보를 추출한 다음 단계별 추론을 수행합니다. , 그리고 마지막으로 답변을 제공합니다. 이러한 단계적 접근 방식은 모델의 체계적인 추론 기능을 향상시켜 복잡한 문제를 보다 효율적으로 처리할 수 있게 해줍니다.

LLaVA-o1은 추론 과정에서 스테이지 레벨 빔 검색 방법을 도입한다는 점은 언급할 가치가 있습니다. 이 접근 방식을 사용하면 모델이 각 추론 단계에서 여러 후보 답변을 생성하고 가장 좋은 답변을 선택하여 추론의 다음 단계로 진행할 수 있으므로 전반적인 추론 품질이 크게 향상됩니다. 감독된 미세 조정 및 합리적인 교육 데이터를 통해 LLaVA-o1은 더 큰 모델이나 비공개 소스 모델과 비교하여 우수한 성능을 발휘합니다.
북경대학교 팀의 연구 결과는 다중 모드 AI의 개발을 촉진할 뿐만 아니라 미래의 시각적 언어 이해 모델을 위한 새로운 아이디어와 방법을 제공합니다. 팀은 LLaVA-o1의 코드, 사전 훈련 가중치 및 데이터 세트가 완전히 오픈 소스가 될 것이며 더 많은 연구자와 개발자가 이 혁신적인 모델을 공동으로 탐색하고 적용하기를 기대한다고 밝혔습니다.
논문: https://arxiv.org/abs/2411.10440
GitHub:https://github.com/PKU-YuanGroup/LLaVA-o1
LLaVA-o1의 오픈 소스는 의심할 여지 없이 다중 모드 AI 분야의 기술 개발과 애플리케이션 혁신을 촉진할 것입니다. 효율적인 추론 메커니즘과 우수한 성능은 향후 시각 언어 모델 연구에 중요한 참고 자료가 되며 주목과 기대를 불러일으킬 가치가 있습니다. 더 많은 개발자들이 참여하여 인공지능 기술의 발전을 함께 추진해 나가기를 기대합니다.