Downcodes의 편집자는 Meta가 최근 능력 평가 벤치마크 테스트인 Multi-IF에 이어 새로운 다국어 다중 회전 대화 명령을 출시했다는 사실을 알게 되었습니다. 이 벤치마크는 8개 언어를 다루며 4501개의 3라운드 대화 작업을 포함하고 있어 대규모 평가를 보다 포괄적으로 수행하는 것을 목표로 합니다. 실제 응용 프로그램에서의 언어 모델(LLM) 성능. 주로 단일 턴 대화 및 단일 언어 작업에 중점을 둔 기존 평가 표준과 달리 Multi-IF는 복잡한 다중 턴 및 다중 언어 시나리오에서 모델의 능력을 검토하는 데 중점을 두어 LLM 개선을 위한 보다 명확한 방향을 제시합니다.
Meta는 최근 다중 대화 및 다국어 환경에서 LLM(대형 언어 모델)의 지시 따르기 능력을 평가하도록 설계된 Multi-IF라는 새로운 벤치마크 테스트를 출시했습니다. 이 벤치마크는 8개 언어를 다루며 4501개의 3턴 대화 작업을 포함하며 복잡한 다중 턴 및 다중 언어 시나리오에서 현재 모델의 성능에 중점을 둡니다.
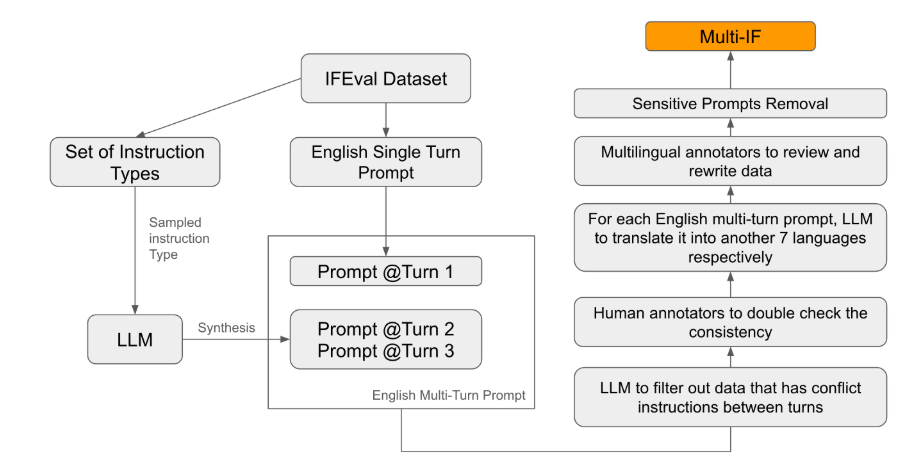
기존 평가 기준 중 대부분이 단일 회전 대화 및 단일 언어 작업에 중점을 두어 실제 적용에서 모델의 성능을 완전히 반영하기 어렵습니다. Multi-IF의 출시는 이러한 격차를 메우는 것입니다. 연구팀은 단일 지침을 여러 단계의 지침으로 확장하여 복잡한 대화 시나리오를 생성했으며, 각 지침이 논리적으로 일관되고 점진적인지 확인했습니다. 또한 데이터 세트는 자동 번역 및 수동 교정과 같은 단계를 통해 다국어 지원도 달성합니다.
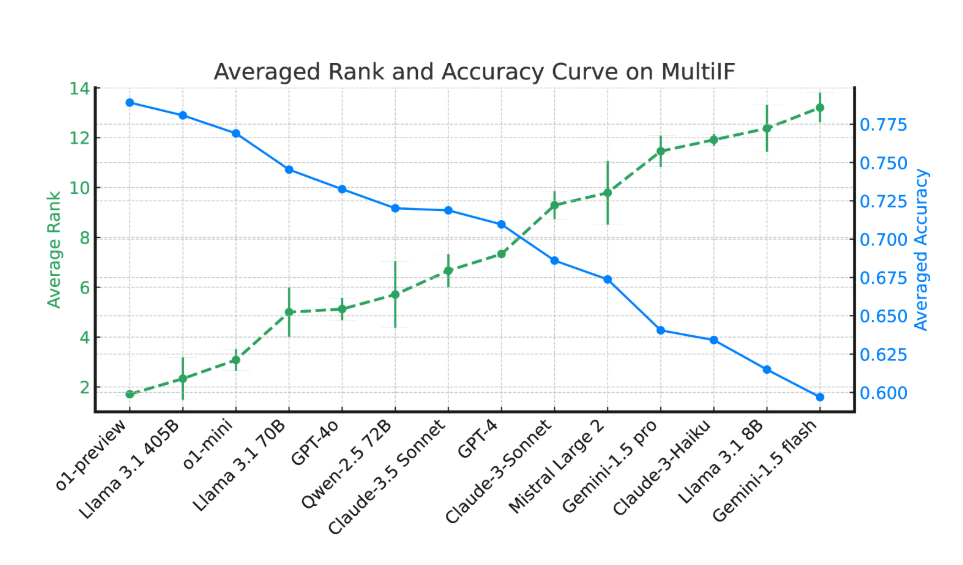
실험 결과에 따르면 대부분의 LLM의 성능은 여러 대화 라운드에 걸쳐 크게 저하됩니다. o1-preview 모델을 예로 들면, 1라운드 평균 정확도는 87.7%였지만, 3라운드에서는 70.7%로 떨어졌습니다. 특히 힌디어, 러시아어, 중국어 등 비라틴 문자를 사용하는 언어에서는 일반적으로 모델의 성능이 영어에 비해 낮아 다국어 작업에 한계를 보입니다.
14개 최첨단 언어 모델 평가에서는 o1-preview와 Llama3.1405B가 3회 명령어 평균 정확도가 각각 78.9%와 78.1%로 가장 좋은 성능을 보였습니다. 그러나 여러 라운드의 대화에서 모든 모델은 복잡한 작업에서 모델이 직면한 어려움을 반영하여 지침을 따르는 능력이 전반적으로 감소한 것으로 나타났습니다. 연구팀은 또한 여러 라운드의 대화에서 모델의 지시 망각 현상을 정량화하기 위해 '명령 망각율'(IFR)을 도입했습니다. 결과는 이와 관련하여 고성능 모델이 상대적으로 좋은 성능을 발휘한다는 것을 보여줍니다.
Multi-IF의 출시는 연구자들에게 도전적인 벤치마크를 제공하고 세계화 및 다국어 응용 프로그램에서 LLM의 개발을 촉진합니다. 이 벤치마크의 출시는 다중 라운드 및 다중 언어 작업에서 현재 모델의 단점을 드러낼 뿐만 아니라 향후 개선을 위한 명확한 방향도 제공합니다.
논문: https://arxiv.org/html/2410.15553v2
Multi-IF 벤치마크 테스트의 출시는 다중 회전 대화 및 다중 언어 처리에서 대규모 언어 모델 연구에 대한 중요한 참고 자료를 제공하고 향후 모델 개선을 위한 길을 제시합니다. 복잡한 다중 라운드 다중 언어 작업의 과제에 더 잘 대처하기 위해 앞으로 점점 더 강력한 LLM이 등장할 것으로 예상됩니다.