Zhiyuan 연구소의 Emu3 팀은 전통적인 다중 모드 모델 아키텍처를 뒤집고 다음 토큰 예측에만 기반하여 훈련하며 생성 및 인식 작업에서 SOTA 성능을 달성하는 혁신적인 다중 모드 모델 Emu3를 출시했습니다. Emu3 팀은 이미지, 텍스트 및 비디오를 개별 공간으로 영리하게 토큰화하고 혼합 다중 모드 시퀀스에서 단일 Transformer 모델을 훈련하여 확산 또는 조합 아키텍처에 의존하지 않고 다중 모드 작업의 통합을 달성합니다. 새로운 돌파구.
Zhiyuan Research Institute의 Emu3 팀은 새로운 다중 모드 모델 Emu3을 출시했습니다. 이 모델은 다음 토큰 예측만을 기반으로 학습되어 기존 확산 모델과 조합 모델 아키텍처를 뒤집고 생성 및 인식 작업 모두에서 결과를 달성합니다. -최첨단 성능.
다음 토큰 예측은 오랫동안 인공지능(AGI)을 향한 유망한 경로로 여겨져 왔지만 다중 모드 작업에서는 제대로 수행되지 않았습니다. 현재 다중 모드 분야는 여전히 확산 모델(예: 안정 확산) 및 조합 모델(예: CLIP 및 LLM 조합)이 지배하고 있습니다. Emu3 팀은 이미지, 텍스트 및 비디오를 개별 공간으로 토큰화하고 혼합 다중 모드 시퀀스에서 단일 Transformer 모델을 처음부터 훈련함으로써 확산 또는 조합 아키텍처에 의존하지 않고 다중 모드 작업을 통합합니다.
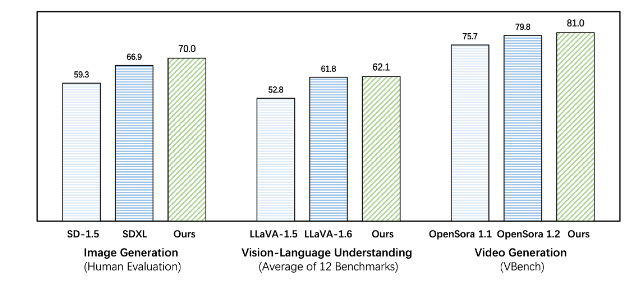
Emu3은 생성 및 인식 작업 모두에서 기존 작업별 모델보다 성능이 뛰어나며 심지어 SDXL 및 LLaVA-1.6과 같은 주력 모델을 능가합니다. Emu3는 또한 비디오 시퀀스에서 다음 토큰을 예측하여 충실도가 높은 비디오를 생성할 수 있습니다. 비디오 확산 모델을 사용하여 노이즈로부터 비디오를 생성하는 Sora와 달리 Emu3는 비디오 시퀀스에서 다음 토큰을 예측하여 인과적인 방식으로 비디오를 생성합니다. 이 모델은 실제 환경, 사람, 동물의 특정 측면을 시뮬레이션하고 비디오의 맥락을 바탕으로 다음에 무슨 일이 일어날지 예측할 수 있습니다.
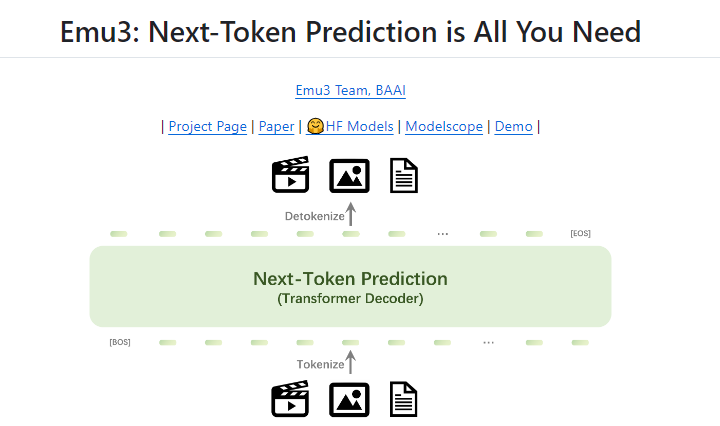
Emu3는 복잡한 다중 모드 모델 설계를 단순화하고 토큰에 초점을 맞춰 훈련 및 추론 중에 엄청난 확장 가능성을 열어줍니다. 연구 결과는 다음 토큰 예측이 언어를 넘어 일반적인 다중 모드 지능을 구축하는 효과적인 방법임을 보여줍니다. 이 분야에 대한 추가 연구를 지원하기 위해 Emu3 팀은 이전에 공개적으로 사용할 수 없었던 비디오와 이미지를 개별 토큰으로 변환할 수 있는 강력한 시각적 토크나이저를 포함하여 오픈 소스 핵심 기술과 모델을 보유하고 있습니다.
Emu3의 성공은 다중 모드 모델의 향후 개발 방향을 제시하고 AGI 실현에 대한 새로운 희망을 제시합니다.
프로젝트 주소: https://github.com/baaivision/Emu3
다운코드 편집기 요약: Emu3 모델의 출현은 다중 모드 분야의 새로운 이정표를 표시합니다. 단순한 아키텍처와 강력한 성능은 미래 AGI 연구에 대한 새로운 아이디어와 방향을 제시합니다. 오픈소스 전략은 학계와 산업계의 공동 발전도 촉진합니다. 앞으로 더 많은 발전을 기대할 가치가 있습니다!