"그림을 보고 말하는 것"으로 알려진 이 아티팩트인 GPT-4V는 그래픽 인터페이스에 대한 이해가 부족하다는 비판을 받아왔습니다. 그것은 종종 잘못된 버튼을 클릭하는 "화면맹인" 사람과 같아서 화가 납니다. 하지만 마이크로소프트가 출시한 OmniParser 모델은 이 문제를 완벽하게 해결할 것으로 예상됩니다! OmniParser는 스크린샷을 GPT-4V의 이해하기 쉬운 구조화된 언어로 변환하여 GPT-4V의 "시력"을 더욱 선명하게 만드는 "화면 번역기"와 같습니다. Downcodes의 편집자는 여러분에게 이 마법의 모델에 대한 심층적인 이해를 제공하고, GPT-4V가 "눈맹"이라는 결함을 극복하는 데 어떻게 도움이 되는지, 그리고 그 뒤에 숨은 놀라운 기술을 알아볼 것입니다.
그림을 보고 말하는 인공물인 GPT-4V를 아직도 기억하시나요? 그림의 내용을 이해하고 그림을 기반으로 작업을 수행할 수 있습니다. 하지만 게으른 사람들에게는 치명적인 이점이 있습니다. 약점: 시력이 별로 좋지 않아요 !
GPT-4V에게 버튼을 클릭하라고 요청했지만 "스크린 블라인드"처럼 여기저기서 클릭한다고 상상해 보세요. 미친 짓이 아닌가요?
오늘은 GPT-4V를 더욱 멋지게 만들 수 있는 아티팩트인 OmniParser를 소개하겠습니다. 이는 그래픽 사용자 인터페이스(GUI)의 자동 상호 작용 문제를 해결하기 위해 Microsoft에서 출시한 새로운 모델입니다.
OmniParser는 무엇을 합니까?
간단히 말해서 OmniParser는 스크린샷을 GPT-4V가 이해할 수 있는 "구조화된 언어"로 구문 분석할 수 있는 "화면 번역기"입니다. OmniParser는 미세 조정된 대화형 아이콘 감지 모델, 미세 조정된 아이콘 설명 모델 및 OCR 모듈의 출력을 결합합니다.

이 조합은 구조화된 DOM과 같은 UI 표현뿐만 아니라 잠재적으로 상호 작용할 수 있는 요소의 경계 상자를 덮는 스크린샷을 생성합니다. 연구원들은 먼저 인기 있는 웹 페이지와 아이콘 설명 데이터 세트를 사용하여 대화형 아이콘 감지 데이터 세트를 만들었습니다. 이러한 데이터 세트는 화면에서 상호 작용 가능한 영역을 구문 분석하기 위한 감지 모델과 감지된 요소의 기능적 의미를 추출하기 위한 설명 모델 등 특수 모델을 미세 조정하는 데 사용됩니다.
특히 OmniParser는 다음을 수행합니다.
화면의 모든 대화형 아이콘과 버튼을 식별하고 상자로 표시하고 각 상자에 고유 ID를 부여합니다.
텍스트를 사용하여 "설정" 및 "최소화"와 같은 각 아이콘의 기능을 설명합니다. 화면의 텍스트를 인식하고 추출합니다.
이러한 방식으로 GPT-4V는 화면에 무엇이 있는지, 각 기능이 무엇인지 명확하게 알 수 있습니다. 클릭하려는 버튼의 ID만 알려주면 됩니다.
OmniParser는 얼마나 멋진가요?
연구원들은 OmniParser를 테스트하기 위해 다양한 테스트를 사용했으며, 이것이 실제로 GPT-4V를 "더 좋게" 만들 수 있다는 것을 발견했습니다!
ScreenSpot 테스트에서 OmniParser는 GPT-4V의 정확도를 크게 향상시켜 그래픽 인터페이스용으로 특별히 훈련된 일부 모델을 능가했습니다. 예를 들어 ScreenSpot 데이터세트에서 OmniParser는 정확도를 73% 향상시켜 기본 HTML 구문 분석에 의존하는 모델보다 성능이 뛰어납니다. 특히, UI 요소의 로컬 의미론을 통합하면 예측 정확도가 크게 향상되었습니다. OmniParser의 출력을 사용할 때 GPT-4V 아이콘의 레이블이 70.5%에서 93.8%로 올바르게 표시되었습니다.
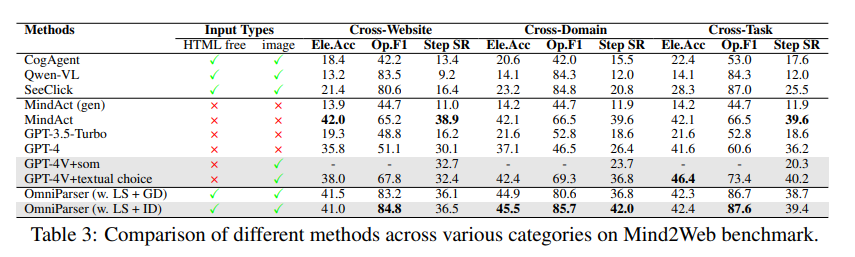
Mind2Web 테스트에서 OmniParser는 웹 검색 작업에서 GPT-4V의 성능을 향상시켰으며 그 정확도는 HTML 정보 지원을 사용하는 GPT-4V를 훨씬 능가했습니다.
AITW 테스트에서 OmniParser는 휴대폰 내비게이션 작업에서 GPT-4V의 성능을 크게 향상시켰습니다.
OmniParser의 단점은 무엇입니까?
OmniParser는 매우 강력하지만 다음과 같은 몇 가지 사소한 결함도 있습니다.
반복되는 아이콘이나 텍스트를 접할 경우 혼동되기 쉬우며 , 이를 구별하기 위해서는 보다 자세한 설명이 필요합니다.
때때로 프레임이 충분히 정확하게 그려지지 않아 GPT-4V가 잘못된 위치에서 클릭되는 경우가 있습니다.
아이콘 해석은 때때로 잘못될 수 있으며 보다 정확한 설명을 위해서는 컨텍스트가 필요합니다.
그러나 연구원들은 OmniParser를 개선하기 위해 열심히 노력하고 있으며 OmniParser가 점점 더 강력해지고 결국 GPT-4V의 최고의 파트너가 될 것이라고 믿습니다!
모델 경험: https://huggingface.co/microsoft/OmniParser
논문 입구: https://arxiv.org/pdf/2408.00203
공식 소개: https://www.microsoft.com/en-us/research/articles/omniparser-for-pure-vision-based-gui-agent/
가장 밝은 부분:
✨OmniParser는 GPT-4V가 화면 내용을 더 잘 이해하고 작업을 더 정확하게 수행하는 데 도움이 됩니다.
OmniParser는 다양한 테스트에서 좋은 성능을 보여 그 효과를 입증했습니다.
?️OmniParser에는 아직 개선할 부분이 있지만 앞으로는 희망이 있습니다.
전체적으로 OmniParser는 GPT-4V와 그래픽 사용자 인터페이스의 상호 작용을 혁신적으로 개선합니다. 아직 몇 가지 단점이 있지만 잠재력은 엄청나며 향후 발전을 기대해 볼 가치가 있습니다. Downcodes의 편집자는 지속적인 기술 발전으로 OmniParser가 인공 지능 분야에서 빛나는 별이 될 것이라고 믿습니다!