최근 인공지능은 다양한 분야에서 눈부신 발전을 이루었지만 수학적 추론 능력은 늘 장애물이 되어왔다. 오늘날 FrontierMath라는 새로운 벤치마크의 출현은 AI의 수학적 추론 능력을 전례 없는 한계까지 끌어올리고 기존 AI 모델에 심각한 도전을 제기하는 새로운 척도를 제공합니다. Downcodes의 편집자는 FrontierMath에 대한 심층적인 이해를 돕고 이것이 AI의 수학적 능력에 대한 우리의 이해를 어떻게 전복시키는지 보여줍니다.
광대한 인공지능의 세계에서 수학은 한때 기계지능의 마지막 보루로 여겨졌다. 오늘날 FrontierMath라는 새로운 벤치마크 테스트가 등장하여 AI의 수학적 추론 능력을 전례 없는 한계까지 끌어올렸습니다.
Epoch AI는 수학계 최고의 두뇌 60여 명과 손을 잡고 수학 올림피아드라고 할 수 있는 AI 챌린지 분야를 공동으로 만들었습니다. 이는 기술적 테스트일 뿐만 아니라 인공지능의 수학적 지혜에 대한 궁극적인 테스트이기도 합니다.
평범한 사람들의 상상을 뛰어넘는 수백 가지의 수학 퍼즐을 만든 세계 최고의 수학자들로 가득 찬 실험실을 상상해 보세요. 이러한 문제는 정수론, 실수 분석, 대수 기하학, 범주 이론과 같은 최첨단 수학 분야에 걸쳐 있으며 엄청나게 복잡합니다. 국제 수학 올림피아드 금메달을 딴 수학 천재라도 문제를 해결하려면 몇 시간, 심지어 며칠이 걸립니다.
놀랍게도 현재 최첨단 AI 모델은 이 벤치마크에서 실망스러운 성능을 보였습니다. 어떤 모델도 문제의 2% 이상을 해결할 수 없었습니다. 이 결과는 마치 모닝콜처럼 AI의 뺨을 때렸다.
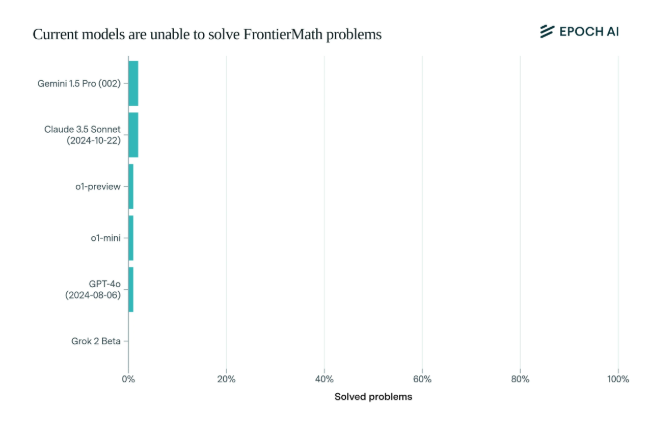
FrontierMath를 독특하게 만드는 것은 엄격한 평가 메커니즘입니다. MATH 및 GSM8K와 같은 기존 수학 테스트 벤치마크는 AI에 의해 최대한 활용되었으며, 이 새로운 벤치마크는 새로운 미공개 질문과 자동화된 검증 시스템을 사용하여 데이터 오염을 효과적으로 방지하고 AI의 수학적 추론 기능을 실제로 테스트합니다.
그동안 많은 관심을 끌었던 오픈AI(OpenAI), 앤트로픽(Anthropic), 구글 딥마인드(Google DeepMind) 등 상위 AI 기업들의 플래그십 모델이 이번 테스트에서 일괄적으로 뒤집혔다. 이는 심오한 기술 철학을 반영합니다. 컴퓨터의 경우 겉으로는 복잡해 보이는 수학적 문제는 쉬울 수 있지만 인간이 단순하다고 생각하는 작업은 AI를 무력하게 만들 수 있습니다.
Andrej Karpathy가 말했듯이 이는 Moravec의 역설을 확증합니다. 인간과 기계 사이의 지능적 작업의 어려움은 종종 반직관적입니다. 이번 벤치마크 테스트는 AI 역량을 엄격하게 시험할 뿐만 아니라 AI가 더 높은 차원으로 진화하는 촉매제이기도 하다.
수학 커뮤니티와 AI 연구자들에게 FrontierMath는 정복되지 않은 에베레스트 산과 같습니다. 지식과 기술을 테스트할 뿐만 아니라 통찰력과 창의적 사고도 테스트합니다. 미래에는 이 지능의 정점을 오르는 데 앞장서는 사람이 인공지능 발전의 역사에 기록될 것이다.
FrontierMath 벤치마크 테스트의 등장은 기존 AI 기술 수준에 대한 엄중한 테스트일 뿐만 아니라, 향후 AI 발전 방향을 제시하는 것이기도 하다. 이는 수학적 추론 분야에서 AI가 아직 갈 길이 멀다는 것을 보여준다. 이는 또한 연구를 촉진하여 기존 기술의 병목 현상을 극복하기 위해 계속해서 탐색하고 혁신합니다.