다운코드 편집자 보고서: Shanghai Jiao Tong University, Cambridge University 및 Geely Automobile Research Institute의 연구팀은 최근 F5-TTS라는 새로운 텍스트 음성 변환(TTS) 시스템을 출시했습니다. 이 시스템은 흐름 일치 및 확산 변환기(DiT)와 결합된 자동 회귀 없는 방법을 사용합니다. 이는 기존 TTS 모델의 복잡한 프로세스를 효과적으로 단순화하고 합성 품질과 추론 속도 모두에서 상당한 혁신을 달성합니다. 기존 TTS 모델과 비교하여 F5-TTS는 처리 속도와 견고성 측면에서 뛰어난 성능을 발휘하여 음성 합성 기술에 새로운 가능성을 제시합니다.
최근 Shanghai Jiao Tong University, Cambridge University 및 Geely Automobile Research Institute의 연구팀은 F5-TTS라는 새로운 텍스트 음성 변환(TTS) 시스템을 출시했습니다. 이 시스템의 특별한 점은 흐름 일치와 확산 변환기(DiT)를 결합한 자동 회귀 없는 방법을 사용하여 기존 TTS 모델의 복잡한 단계를 성공적으로 단순화한다는 것입니다.

우리 모두 알고 있듯이 기존 TTS 모델에는 복잡한 기간 모델링, 음소 정렬 및 특수 텍스트 인코딩이 필요한 경우가 많으며 이로 인해 합성 프로세스가 더욱 복잡해집니다. 특히 E2TTS와 같은 이전 모델은 수렴 속도가 느리고 텍스트와 음성의 정렬이 부정확한 등의 문제에 직면하는 경우가 많아 실제 시나리오에 효율적으로 적용하기가 어렵습니다. F5-TTS의 등장은 바로 이러한 과제를 해결하기 위한 것입니다.
F5-TTS의 작동 원리는 간단합니다. 첫째, 입력 텍스트는 ConvNeXt 아키텍처를 통해 처리되어 음성과 더 쉽게 정렬됩니다. 그런 다음 패딩된 문자 시퀀스가 입력 음성의 시끄러운 버전과 함께 모델에 입력됩니다.
시스템 훈련은 흐름 일치를 통해 간단한 초기 분포를 데이터 분포에 효과적으로 매핑하는 DiT(확산 변환기)에 의존합니다. 또한 F5-TTS는 추론 중에 Sway Sampling 전략을 혁신적으로 도입하여 추론 단계의 초기 흐름 단계에 우선 순위를 지정하여 생성된 음성과 입력 텍스트 간의 정렬을 향상할 수 있습니다.
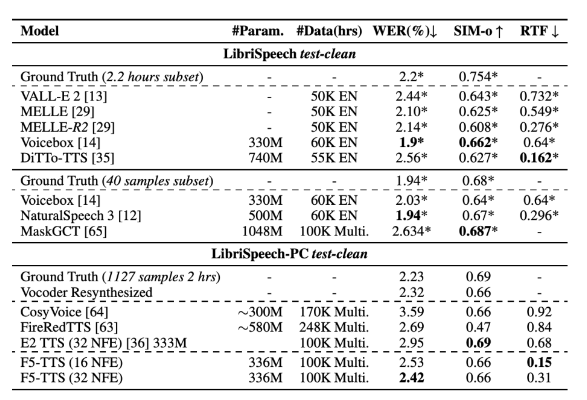
연구 결과에 따르면 F5-TTS는 합성 품질과 추론 속도 모두에서 현재의 많은 TTS 시스템을 능가합니다. LibriSpeech-PC 데이터세트에서 모델은 추론 시 단어 오류율(WER) 2.42, 실시간 인자(RTF) 0.15를 달성했는데, 이는 처리 성능이 더 좋았던 이전 확산 모델 E2TTS보다 훨씬 뛰어났습니다. 속도와 견고성에 단점이 있습니다.
동시에 Sway 샘플링 전략은 생성된 음성의 자연스러움과 이해성을 크게 향상시켜 모델이 훈련 없이 부드럽고 표현력 있는 생성을 달성할 수 있도록 해줍니다.
F5-TTS는 프로세스를 단순화하고 기간 예측, 음소 정렬 및 명시적 텍스트 인코딩의 필요성을 제거하여 정렬 견고성과 합성 품질을 향상시킵니다. 또한 연구진은 윤리적 고려 사항도 강조하고, 모델이 악용되는 것을 방지하기 위해 워터마킹 및 탐지 시스템 구축의 필요성도 제안했습니다.
프로젝트 입구: https://github.com/SWivid/F5-TTS
가장 밝은 부분:
F5-TTS는 기존 TTS 모델의 복잡성을 단순화하는 새로운 유형의 자동 회귀 텍스트 음성 변환 시스템입니다.
시스템은 ConvNeXt 및 DiT 아키텍처를 활용하여 텍스트와 음성의 정렬을 개선하고 합성 품질을 크게 향상시킵니다.
? 연구원들은 윤리적 문제에 주의를 기울여야 함을 강조하고 잠재적인 남용을 방지하기 위해 워터마킹 및 탐지 메커니즘의 도입을 제안했습니다.
F5-TTS 시스템의 등장은 문자 음성 변환 기술에 새로운 돌파구를 마련했으며, 효율적인 성능과 단순화된 프로세스는 다양한 분야에서 널리 사용될 것으로 예상됩니다. 그러나 윤리적 문제에도 주의가 필요하며, 책임 있는 기술 개발을 보장하기 위해 건전한 규제 메커니즘을 확립하는 데 후속 연구를 집중해야 합니다.