다운코드 편집자는 AI 분야의 충격적인 현상인 모델 붕괴를 이해하도록 안내합니다. AI 모델이 자신이 요리한 음식을 먹기 시작하는 음식 블로거와 같다고 상상해 보십시오. 더 많이 먹을수록 그 음식에 중독되고 결국 그는 "나쁜" 음식이 됩니다. 모델이 무너지는 순간입니다. 이는 AI 모델이 생성된 데이터에 너무 많이 의존하여 모델 품질이 저하되거나 심지어 완전한 실패로 이어질 때 발생합니다. 이 기사에서는 원인, 결과 및 모델 붕괴를 방지하는 방법을 자세히 살펴보겠습니다.
최근 AI계에 이상한 일이 일어났다. 푸드 블로거가 자신이 만든 음식을 갑자기 먹기 시작했고, 먹으면 먹을수록 중독이 되고, 음식이 점점 맛없어지는 일이 벌어졌다. 이것을 전문 용어로 모델 붕괴라고 부르기가 꽤 무섭습니다.
모델 붕괴란 간단히 말하면, AI 모델이 학습 과정에서 자체 생성 데이터를 대량으로 사용하게 되면 악순환에 빠지게 되어 모델 생성 품질이 점점 더 나빠지게 되고, 결국에는 실패하다.
이것은 폐쇄된 생태계와 같습니다. AI 모델은 이 시스템에서 유일한 생명체이고, 그것이 생산하는 음식은 데이터입니다. 처음에는 여전히 일부 천연 성분(실제 데이터)을 찾을 수 있었지만, 시간이 지남에 따라 자신이 생산한 "인공" 성분(합성 데이터)에 점점 더 의존하기 시작했습니다. 문제는 이러한 "인공" 성분이 영양학적으로 부족하고 모델 자체의 일부 결함을 갖고 있다는 것입니다. 너무 많이 먹으면 AI 모델의 '몸'이 무너지고 생성되는 것들이 점점 더 터무니없어진다.
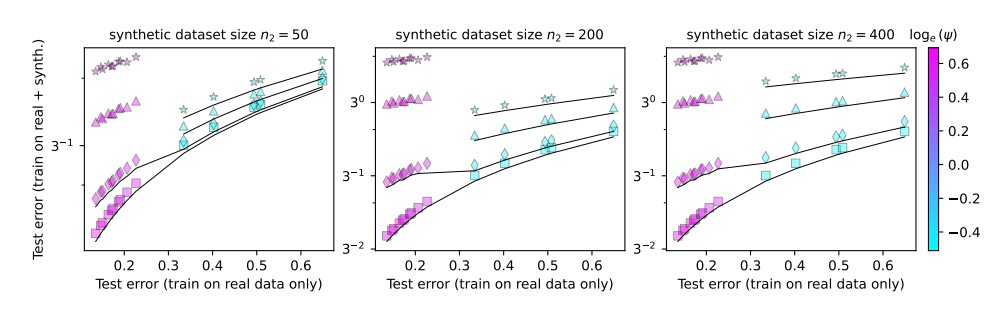
이 논문에서는 모델 붕괴 현상을 연구하고 다음 두 가지 주요 질문에 답하려고 합니다.
모델 붕괴는 불가피한가? 실제 데이터와 합성 데이터를 혼합해 문제를 해결할 수 있을까?
모델이 클수록 충돌이 더 쉬워지나요?
이러한 문제를 연구하기 위해 논문의 저자는 일련의 실험을 설계하고 무작위 투영 모델을 사용하여 신경망의 훈련 과정을 시뮬레이션했습니다. 그들은 합성 데이터의 작은 부분(예: 1%)만 사용해도 모델이 붕괴될 수 있다는 사실을 발견했습니다. 설상가상으로 모델의 크기가 커질수록 모델 붕괴 현상은 더욱 심각해진다.
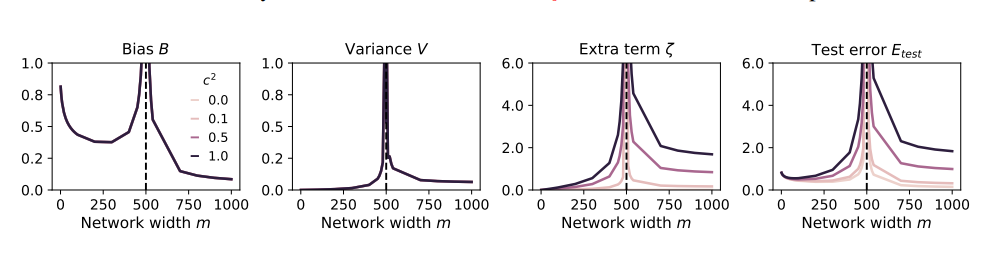
이것은 관심을 끌기 위해 온갖 이상한 재료를 시도했지만 결국 위장이 나빠진 푸드 블로거와 같습니다. 손실을 만회하기 위해 음식 섭취량을 늘리고 점점 더 이상한 음식을 먹을 수밖에 없었고, 그 결과 위장은 점점 더 악화되었고, 결국 먹는 일과 방송의 세계를 그만둘 수밖에 없었다.
그렇다면 모델 붕괴를 어떻게 방지해야 할까요?
논문의 저자는 다음과 같은 몇 가지 제안을 했습니다.
실제 데이터 사용 우선순위 지정: 실제 데이터는 자연 식품과 같고 영양분이 풍부하며 AI 모델의 건강한 성장의 열쇠입니다.
합성 데이터를 주의해서 사용하세요. 합성 데이터는 일부 영양소를 보충할 수 있지만 너무 많이 의존해서는 안 됩니다. 그렇지 않으면 역효과를 낳을 수 있습니다.
모델의 크기 조절: 모델이 클수록 식욕이 왕성해지고, 위가 안 좋아지기 쉽습니다. 합성 데이터를 사용할 때 과잉 공급을 방지하기 위해 모델 크기를 제어하십시오.
모델 붕괴는 AI 개발 과정에서 직면하게 되는 새로운 과제입니다. 이는 모델 규모와 효율성을 추구하는 동시에 데이터의 품질과 모델의 상태에도 주의를 기울여야 함을 상기시켜 줍니다. 그래야만 AI 모델이 계속해서 건강하게 발전하고 인류 사회를 위해 더 큰 가치를 창출할 수 있습니다.
논문: https://arxiv.org/pdf/2410.04840
전체적으로 모델 붕괴는 AI 개발에서 주목할 만한 문제이다. 합성 데이터를 주의 깊게 다루고, 실제 데이터의 품질에 주의를 기울이고, 'AI' 현상을 피하기 위해 모델의 규모를 제어해야 한다. 너무 많이 먹어." 이 분석이 모든 사람이 모델 붕괴를 더 잘 이해하고 AI의 건전한 발전에 기여하는 데 도움이 되기를 바랍니다.