Downcodes의 편집자가 큰 소식을 전해 드립니다! 인공지능 분야에 새로운 멤버가 등장했습니다. Zyphra가 소형 언어 모델 Zamba2-7B를 공식 출시했습니다! 이 70억 개의 매개변수 모델은 특히 효율성과 적응성 측면에서 획기적인 성능을 달성하여 인상적인 이점을 보여줍니다. 고성능 컴퓨팅 환경에 적합할 뿐만 아니라, 더 중요한 것은 Zamba2-7B가 소비자급 GPU에서도 실행될 수 있어 더 많은 사용자가 고급 AI 기술의 매력을 쉽게 경험할 수 있다는 것입니다. 이 기사에서는 Zamba2-7B의 혁신과 그것이 자연어 처리 분야에 미치는 영향을 자세히 살펴보겠습니다.
최근 Zyphra는 매개변수 수가 7B에 달하는 전례 없는 성능을 갖춘 작은 언어 모델인 Zamba2-7B를 공식 출시했습니다.
이 모델은 Mistral-7B, Google의 Gemma-7B 및 Meta의 Llama3-8B를 포함하여 품질과 속도면에서 현재 경쟁사를 능가한다고 주장합니다.
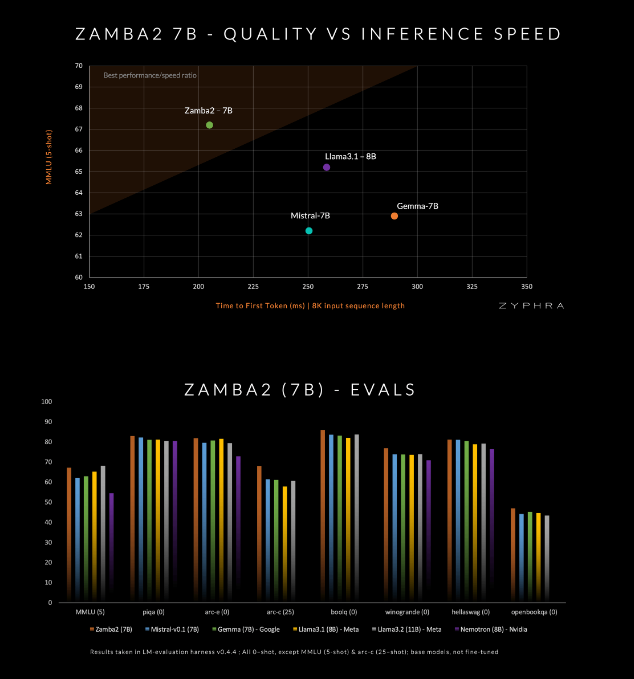
Zamba2-7B는 강력한 언어 처리 기능이 필요하지만 온디바이스 처리 또는 소비자급 GPU 사용과 같은 하드웨어 조건에 의해 제한되는 환경의 요구를 충족하도록 설계되었습니다. Zyphra는 품질 저하 없이 효율성을 향상함으로써 기업이든 개인 개발자든 더 넓은 범위의 사용자가 고급 AI의 편리함을 누릴 수 있기를 희망합니다.
Zamba2-7B는 모델의 효율성과 표현 능력을 향상시키기 위해 아키텍처에 많은 혁신을 이루었습니다. 이전 세대 모델 Zamba1과 달리 Zamba2-7B는 두 개의 공유 주의 블록을 사용합니다. 이 설계는 정보 흐름과 시퀀스 간의 종속성을 더 잘 처리할 수 있습니다.
Mamba2 블록은 전체 아키텍처의 핵심을 형성하므로 기존 변환기 모델보다 모델의 매개변수 활용도가 높아집니다. 또한 Zyphra는 공유 MLP 블록에 LoRA(저위 적응) 투영을 사용하여 모델의 컴팩트함을 유지하면서 각 레이어의 적응성을 더욱 향상시킵니다. 이러한 혁신 덕분에 Zamba2-7B의 첫 번째 응답 시간은 25% 단축되었으며, 초당 처리되는 토큰 수는 20% 증가했습니다.
Zamba2-7B의 효율성과 적응성은 엄격한 테스트를 통해 검증되었습니다. 이 모델은 3조 개의 토큰이 포함된 대규모 데이터 세트에서 사전 훈련되었으며, 이는 고품질이고 엄격하게 선별된 공개 데이터입니다.
또한 Zyphra는 고품질 토큰을 보다 효율적으로 처리하기 위해 학습 속도를 빠르게 줄이는 "어닐링" 사전 훈련 단계도 도입합니다. 이 전략을 통해 Zamba2-7B는 벤치마크에서 좋은 성능을 발휘하여 추론 속도와 품질에서 경쟁사를 능가하며 기존 고품질 모델에 필요한 대규모 컴퓨팅 리소스가 필요하지 않은 자연어 이해 및 생성과 같은 작업에 적합합니다.
amba2-7B는 접근성에 특별한 주의를 기울이는 동시에 높은 품질과 성능을 유지하면서 소규모 언어 모델의 주요 발전을 나타냅니다. 혁신적인 아키텍처 설계와 효율적인 훈련 기술을 통해 Zyphra는 사용하기 쉬울 뿐만 아니라 다양한 자연어 처리 요구 사항을 충족할 수 있는 모델을 성공적으로 만들었습니다. Zamba2-7B의 오픈 소스 릴리스는 연구원, 개발자 및 기업이 그 잠재력을 탐구하도록 초대하며 더 넓은 커뮤니티 내에서 고급 자연어 처리 개발을 발전시킬 것으로 예상됩니다.
프로젝트 입구: https://www.zyphra.com/post/zamba2-7b
https://github.com/Zyphra/transformers_zamba2
Zamba2-7B의 오픈 소스 릴리스는 자연어 처리 분야에 새로운 활력을 불어넣고 개발자에게 더 많은 가능성을 제공했습니다. 앞으로 Zamba2-7B가 더욱 널리 활용되어 인공지능 기술의 지속적인 발전을 도모해 나가기를 기대합니다!