Downcodes의 편집자는 Meta, University of California, Berkeley 및 New York University의 과학자들이 LLM(대형 언어 모델)의 성능 향상을 목표로 하는 "Thinking Preference Optimization(TPO)"이라는 새로운 기술을 공동으로 개발했다는 사실을 알게 되었습니다. 이 기술은 모델이 질문에 대답하기 전에 일련의 사고 단계를 생성하도록 하고, 평가 모델을 사용하여 최종 답변의 품질을 최적화함으로써 AI의 '사고' 능력을 향상시켜 다양한 작업에서 더 나은 성능을 발휘할 수 있도록 합니다. 전통적인 '체인 사고' 기술과 달리 TPO는 응용 범위가 더 넓으며 특히 창의적 글쓰기, 상식 추론 등에 상당한 이점을 보여줍니다.
최근 Meta, University of California, Berkeley 및 New York University의 과학자들은 TPO(Thought Preference Optimization)라는 새로운 기술을 개발하기 위해 협력했습니다. 이 기술의 목표는 다양한 작업을 수행할 때 LLM(대형 언어 모델)의 성능을 향상시켜 AI가 응답하기 전에 응답을 더 신중하게 고려할 수 있도록 하는 것입니다.
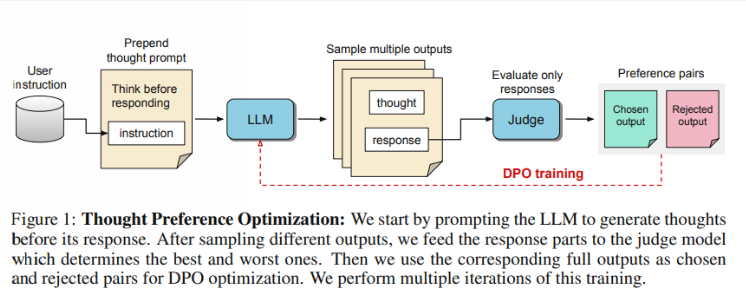
연구자들은 사고가 폭넓은 유용성을 가져야 한다고 말합니다. 예를 들어, 창의적인 글쓰기 작업에서 AI는 내부 사고 과정을 사용하여 전반적인 구조와 캐릭터 개발을 계획할 수 있습니다. 이 방법은 이전의 "사고 사슬"(CoT) 프롬프트 기술과 크게 다릅니다. 후자는 주로 수학적 및 논리적 작업에 사용되는 반면 TPO는 더 넓은 범위의 응용 프로그램을 가지고 있습니다. 연구원들은 OpenAI의 새로운 o1 모델을 언급했으며 사고 과정이 더 넓은 범위의 작업에도 도움이 된다고 믿습니다.
그렇다면 TPO는 어떻게 작동합니까? 먼저, 모델은 질문에 대답하기 전에 일련의 사고 단계를 생성합니다. 다음으로, 여러 출력을 생성한 다음 사고 단계 자체가 아닌 최종 답변에 대해서만 평가 모델에 의해 평가됩니다. 마지막으로, 이러한 평가 결과에 대한 선호도 최적화를 통해 모델을 학습시킵니다. 연구자들은 사고 과정을 개선함으로써 답변의 질을 향상시킬 수 있고, 이를 통해 모델이 암묵적 학습에서 보다 효과적인 추론 능력을 얻을 수 있기를 바라고 있습니다.
테스트에서 TPO를 사용하는 Llama38B 모델은 명시적 추론이 없는 버전보다 벤치마크 이후의 일반 명령에서 더 나은 성능을 보였습니다. AlpacaEval과 Arena-Hard 벤치마크에서 TPO의 승률은 각각 52.5%와 37.3%에 달했습니다. 더욱 흥미로운 점은 상식, 마케팅, 건강 등 일반적으로 명시적인 사고가 필요하지 않은 영역에서도 TPO가 진전을 이루고 있다는 점입니다.
그러나 연구팀은 TPO가 실제로 이러한 작업에 대한 기본 모델보다 성능이 떨어지기 때문에 현재 설정이 수학적 문제에 적합하지 않다고 지적했습니다. 이는 고도로 전문화된 작업에는 다른 접근 방식이 필요할 수 있음을 시사합니다. 향후 연구는 사고 과정의 길이 제어 및 더 큰 모델에 대한 사고의 영향과 같은 측면에 초점을 맞출 수 있습니다.
가장 밝은 부분:
연구팀은 작업 실행에서 AI의 사고 능력을 향상시키는 것을 목표로 하는 '사고 선호 최적화(Thinking Preference Optimization, TPO)'를 출시했습니다.
? TPO는 평가 모델을 사용하여 답변하기 전에 모델이 사고 단계를 생성하도록 함으로써 답변 품질을 최적화합니다.
테스트에 따르면 TPO는 일반 지식 및 마케팅과 같은 영역에서 우수한 성능을 보이지만 수학 작업에서는 성능이 좋지 않은 것으로 나타났습니다.
전체적으로 TPO 기술은 대규모 언어 모델 개선을 위한 새로운 방향을 제시하며, AI 사고 능력 향상에 대한 잠재력은 기대해볼 만하다. 그러나 이 기술에도 한계가 있으며, 향후 연구에서는 응용 범위를 더욱 개선하고 확장해야 합니다. Downcodes의 편집자는 이 분야의 최신 개발에 계속해서 관심을 기울이고 독자들에게 더욱 흥미로운 보고서를 제공할 것입니다.