OpenAI는 눈길을 끄는 새 모델 gpt-4o-audio-preview를 출시했습니다. 이 모델은 음성 생성 및 분석 분야에서 획기적인 발전을 이루어 사용자에게 보다 자연스럽고 지능적인 음성 상호 작용 경험을 제공합니다. 다운코드 편집자는 이 모델의 핵심 기능, 애플리케이션 시나리오 및 가격 전략을 심층적으로 이해하고 다양한 산업에 대한 잠재적 영향을 분석하도록 안내합니다.
OpenAI가 다시 한번 인공지능 기술 트렌드를 선도하고 새로운 gpt-4o-audio-preview 모델을 출시합니다. 이 모델은 음성 생성 및 분석의 놀라운 기능을 보여줄 뿐만 아니라 인간과 컴퓨터의 상호 작용에 대한 새로운 가능성을 열어줍니다. 이 혁신적인 모델의 기능과 잠재적인 응용 프로그램을 자세히 살펴보겠습니다.
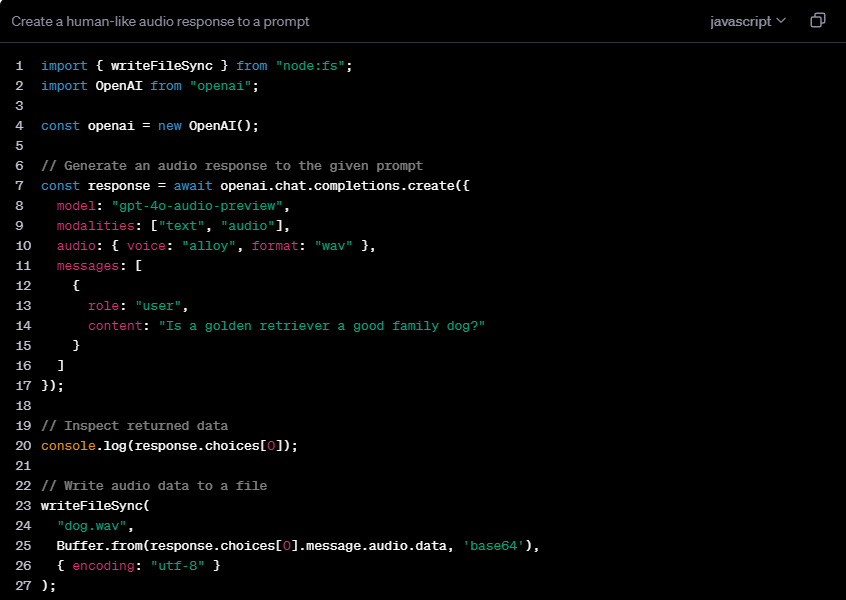
gpt-4o-audio-preview의 핵심 기능에는 세 가지 주요 측면이 포함됩니다. 첫째, 텍스트를 기반으로 자연스럽고 부드러운 음성 응답을 생성하여 음성 도우미 및 가상 고객 서비스와 같은 애플리케이션에 대한 강력한 지원을 제공합니다. 둘째, 이 모델은 오디오 입력의 감정, 억양, 음높이를 분석하는 기능을 갖추고 있어 감성 컴퓨팅 및 사용자 경험 분석 분야에서 폭넓은 응용 가능성을 가지고 있습니다. 마지막으로, 오디오를 입력 및 출력으로 모두 사용할 수 있는 음성 대 음성 상호 작용을 지원하여 전체 범위의 음성 상호 작용 시스템의 기반을 마련합니다.
OpenAI의 기존 Realtime API와 비교하여 gpt-4o-audio-preview는 음성 처리의 세부 사항에 더 중점을 둡니다. 억양과 감정과 같은 미묘한 특징을 처리하는 데 특히 중점을 두고 음성 생성, 감정 분석 및 음성 상호 작용에 탁월합니다. 이와 대조적으로 Realtime API는 실시간 데이터 처리에 더 중점을 두고 실시간 음성-텍스트 또는 실시간 번역 및 기타 지속적인 대화형 애플리케이션과 같이 즉각적인 피드백이 필요한 시나리오에 적합합니다.
gpt-4o-audio-preview의 유연성은 다중 모드 조합 지원에 반영됩니다. 사용자는 텍스트 입력을 선택하여 텍스트 및 오디오 출력을 생성하거나 오디오 입력을 사용하여 텍스트 및 음성 출력을 얻을 수 있습니다. 또한 오디오-텍스트 변환 및 혼합 입력 모드도 지원하여 개발자에게 풍부한 옵션을 제공합니다.
가격 측면에서 OpenAI는 토큰 기반 청구 모델을 채택합니다. 텍스트 입력 가격은 백만 토큰당 약 5달러로 상대적으로 낮습니다. 텍스트 출력은 백만 토큰당 약 15달러로 약간 더 높습니다. 오디오 처리 비용은 상대적으로 높습니다. 입력 비용은 백만 토큰당 $100(분당 약 $0.06)인 반면 오디오 출력은 백만 토큰당 $200(분당 약 $0.24)에 이릅니다. 이 가격 책정 전략은 오디오 처리의 복잡성과 컴퓨팅 리소스 요구 사항을 반영합니다.
gpt-4o-audio-preview의 출시는 의심할 여지 없이 여러 산업에 혁신적인 영향을 미칠 것입니다. 고객 서비스 분야에서는 보다 자연스럽고 감성적인 음성 인터랙션 경험을 제공할 수 있습니다. 교육 산업에서는 이 기술을 사용하여 학생들의 발음과 억양을 향상시키는 데 도움이 되는 지능형 언어 학습 보조 장치를 개발할 수 있습니다. 엔터테인먼트 산업에서는 더욱 실감나는 음성합성과 가상 캐릭터 상호작용을 이끌어낼 것으로 기대된다. 또한, 보조 기술 측면에서 gpt-4o-audio-preview는 청각 장애인을 위해 보다 정확한 음성-텍스트 서비스를 제공하거나, 시각 장애인을 위해 보다 풍부한 음성 설명을 제공할 수 있습니다.
세부 정보: https://platform.openai.com/docs/guides/audio/quickstart
전체적으로 gpt-4o-audio-preview 모델의 등장은 음성 인공 지능 기술의 새로운 단계를 의미합니다. 강력한 기능과 광범위한 응용 가능성은 미래의 인간-컴퓨터 상호 작용 방법에 혁명적인 변화를 가져올 것입니다. Downcodes의 편집자는 이 모델을 기반으로 하는 더욱 혁신적인 응용 프로그램을 볼 수 있기를 기대합니다.