Downcodes의 편집자는 Alibaba Damo Academy와 중국 인민대학교가 공동으로 mPLUG-DocOwl1.5라는 문서 처리 모델을 오픈소스화했다는 사실을 알게 되었습니다. 이 모델은 OCR 인식 없이 문서 내용을 이해할 수 있으며 여러 벤치마크 테스트에서 좋은 성능을 발휘합니다. 핵심은 다중 모드 대형 언어 모델(MLLM)의 서식 있는 텍스트 이미지에 대한 구조적 이해를 향상시키는 "통합 구조 학습" 방법에 있습니다. . 이 모델은 GitHub에 공개적으로 코드, 모델 및 데이터 세트를 공개하여 관련 분야 연구에 귀중한 리소스를 제공합니다.
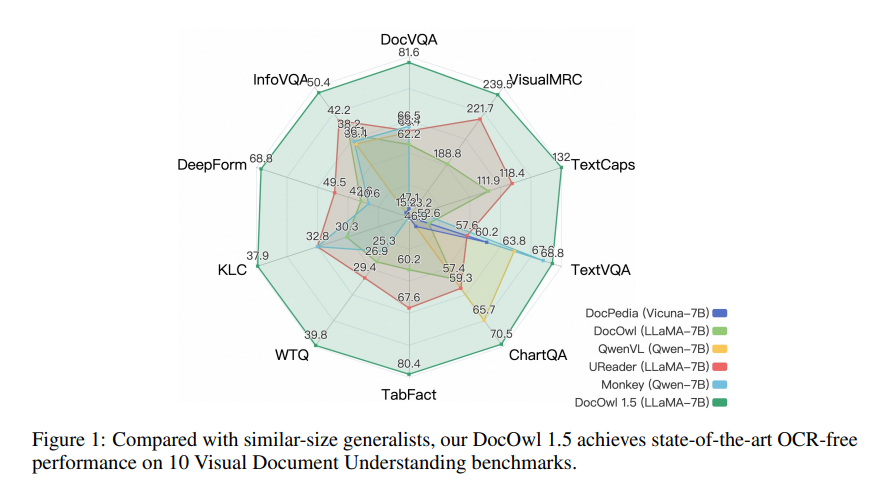
Alibaba Damo Academy와 중국 인민대학교는 최근 mPLUG-DocOwl1.5라는 문서 처리 모델을 공동으로 오픈했습니다. 이 모델은 OCR 인식 없이 문서 내용을 이해하는 데 중점을 두고 있으며 여러 시각적 문서 이해 벤치마크 테스트에서 최고의 성능을 달성했습니다.
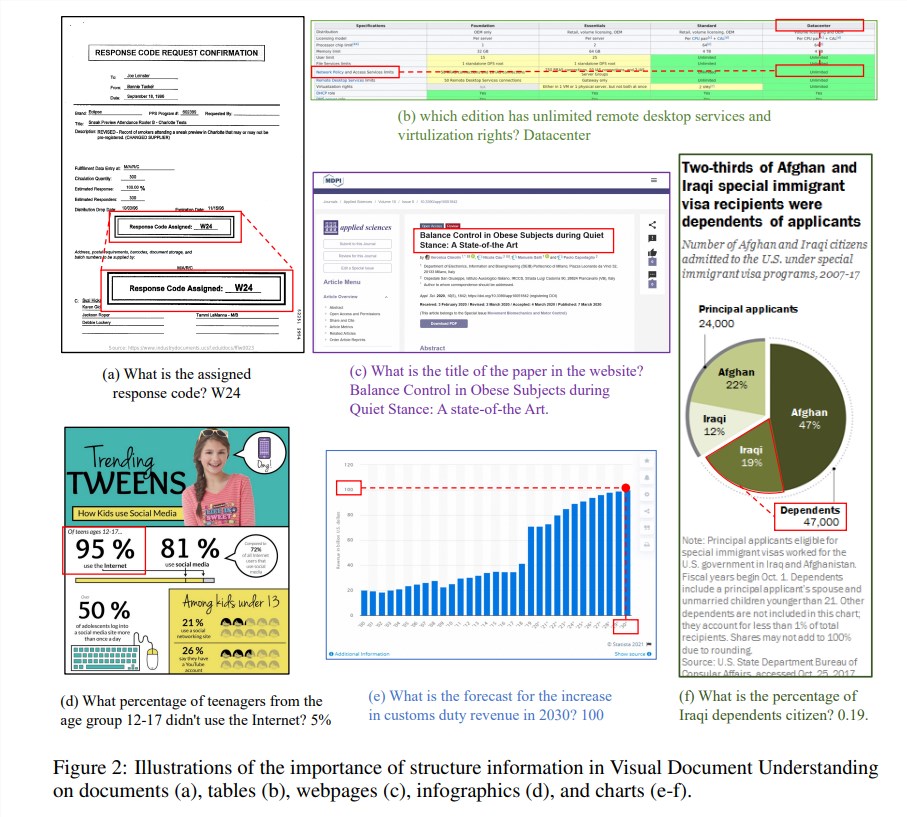
구조적 정보는 문서, 표, 차트 등 텍스트가 많은 이미지의 의미를 이해하는 데 매우 중요합니다. 기존 다중 모드 대형 언어 모델(MLLM)에는 텍스트 인식 기능이 있지만 서식 있는 텍스트 문서 이미지의 일반적인 구조를 이해하는 기능이 부족합니다. 이러한 문제를 해결하기 위해 mPLUG-DocOwl1.5는 시각적 문서 이해에 있어 구조적 정보의 중요성을 강조하고, MLLM의 성능 향상을 위한 '통합 구조 학습'을 제안합니다.
모델의 "통합 구조 학습"은 구조 인식 구문 분석 작업 및 다중 세분성 텍스트 위치 지정 작업을 포함하여 문서, 웹 페이지, 테이블, 차트 및 자연 이미지의 5개 영역을 다룹니다. 구조적 정보를 더 잘 인코딩하기 위해 연구원들은 레이아웃 정보를 보존할 뿐만 아니라 컨볼루션을 통해 수평으로 인접한 이미지 패치를 병합하여 시각적 특징의 길이를 줄이는 간단하고 효과적인 시각적-텍스트 모듈 H-Reducer를 설계했습니다. 고해상도 이미지를 보다 효율적으로 이해하기 위한 대규모 언어 모델.
또한 구조 학습을 지원하기 위해 연구팀은 구조 인식 텍스트 시퀀스와 다중 세분성 텍스트 경계 상자 쌍을 포함하는 공개적으로 사용 가능한 데이터 세트를 기반으로 400만 개의 샘플을 포함하는 포괄적인 훈련 세트인 DocStruct4M을 구축했습니다. 문서 분야에서 MLLM의 추론 기능을 더욱 활성화하기 위해 25,000개의 고품질 샘플이 포함된 추론 미세 조정 데이터 세트 DocReason25K도 구축했습니다.
mPLUG-DocOwl1.5는 먼저 통합 구조 학습을 수행한 다음 여러 다운스트림 작업에서 다중 작업 미세 조정을 수행하는 2단계 학습 프레임워크를 채택합니다. 이 훈련 방법을 통해 mPLUG-DocOwl1.5는 10개의 시각적 문서 이해 벤치마크에서 최첨단 성능을 달성했으며, 5개의 벤치마크에서 7B LLM의 SOTA 성능을 10% 이상 향상시켰습니다.
현재 mPLUG-DocOwl1.5의 코드, 모델 및 데이터 세트가 GitHub에 공개되어 있습니다.
프로젝트 주소: https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5
논문 주소: https://arxiv.org/pdf/2403.12895
mPLUG-DocOwl1.5의 오픈 소스는 시각적 문서 이해 분야의 연구 및 응용에 새로운 가능성을 제공합니다. 효율적인 성능과 편리한 액세스 방법은 개발자의 관심과 사용을 받을 가치가 있습니다. 앞으로 이 모델이 보다 실제적인 시나리오에 활용될 수 있을 것으로 기대된다.