다운코드 편집자는 스위스 로잔 연방공과대학(EPFL)의 최신 연구 결과에 대해 알아볼 수 있도록 안내합니다! 이 연구는 대형 언어 모델(LLM)에 대한 두 가지 주류 적응형 훈련 방법인 상황별 학습(ICL)과 지침 미세 조정(IFT)을 심층적으로 비교하고 MT-Bench 벤치마크를 사용하여 모델의 따라갈 수 있는 능력을 평가합니다. 지침. 연구 결과에 따르면 두 가지 방법은 서로 다른 시나리오에서 고유한 장점을 갖고 있어 LLM 교육 방법 선택에 귀중한 참고 자료가 됩니다.
스위스 EPFL(Ecole Polytechnique Fédérale de Lausanne)의 최근 연구에서는 대규모 언어 모델(LLM)을 위한 두 가지 주류 적응형 훈련 방법인 상황별 학습(ICL)과 교육 미세 조정(IFT)을 비교했습니다. 연구원들은 MT-Bench 벤치마크를 사용하여 모델의 지침 준수 능력을 평가했으며 특정 상황에서는 두 방법 모두 성능이 더 좋거나 나쁘다는 것을 발견했습니다.
연구에 따르면 사용 가능한 훈련 샘플 수가 적을 때(예: 50개 이하) ICL과 IFT의 효과가 매우 유사하다는 사실이 밝혀졌습니다. 이는 데이터가 제한적일 때 ICL이 IFT의 대안이 될 수 있음을 시사합니다.
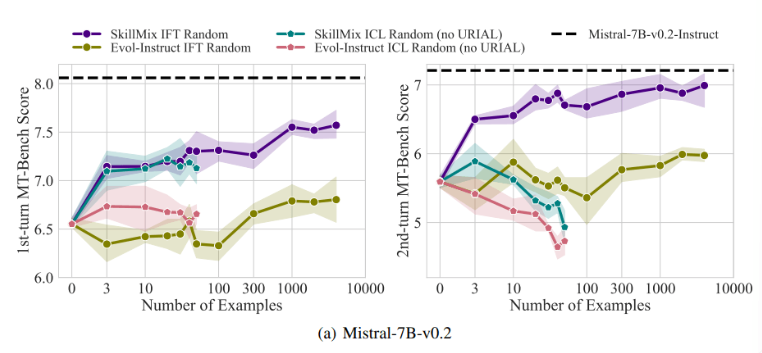
그러나 다중 턴 대화 시나리오와 같이 작업 복잡성이 증가함에 따라 IFT의 장점이 분명해집니다. 연구원들은 ICL 모델이 단일 샘플의 스타일에 과적합되는 경향이 있어 복잡한 대화를 처리할 때 성능이 저하되거나 기본 모델보다 더 나쁜 결과를 낳는다고 믿습니다.
또한 이 연구에서는 기본 언어 모델을 훈련하기 위해 규칙을 따르기 위해 3개의 샘플과 지침만 사용하는 URIAL 방법도 조사했습니다. URIAL이 특정 결과를 달성했지만 IFT로 학습한 모델과 비교하면 여전히 격차가 있습니다. EPFL 연구자들은 샘플 선택 전략을 개선하여 이를 미세 조정 모델에 가깝게 만들어 URIAL의 성능을 향상시켰습니다. 이는 ICL, IFT 및 기본 모델 교육을 위한 고품질 교육 데이터의 중요성을 강조합니다.
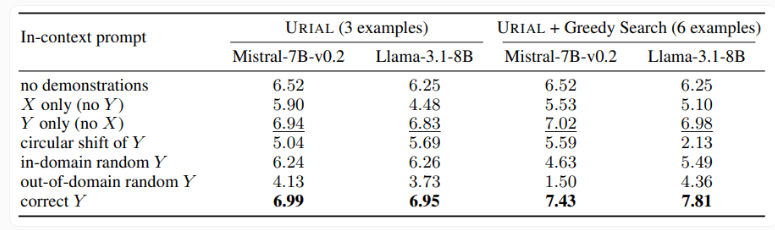
또한, 연구에서는 디코딩 매개변수가 모델 성능에 상당한 영향을 미친다는 사실도 발견했습니다. 이러한 매개변수는 모델이 텍스트를 생성하는 방법을 결정하며 기본 LLM과 URIAL로 훈련된 모델 모두에 중요합니다.
연구원들은 적절한 디코딩 매개변수가 주어지면 기본 모델도 어느 정도 지침을 따를 수 있다고 지적합니다.
이 연구의 중요성은 특히 훈련 샘플이 제한적인 경우 상황별 학습이 언어 모델을 빠르고 효율적으로 조정할 수 있음을 보여주었다는 것입니다. 그러나 다중 턴 대화와 같은 복잡한 작업의 경우 명령 미세 조정이 여전히 더 나은 선택입니다.
데이터 세트의 크기가 증가함에 따라 IFT의 성능은 계속 향상되는 반면, ICL의 성능은 특정 수의 샘플에 도달한 후 안정화됩니다. 연구원들은 ICL과 IFT 사이의 선택이 사용 가능한 리소스, 데이터 양, 특정 애플리케이션 요구 사항 등 다양한 요소에 따라 달라진다는 점을 강조합니다. 어떤 방법을 선택하든 고품질 교육 데이터가 중요합니다.
전체적으로 이 EPFL 연구는 대규모 언어 모델을 위한 훈련 방법 선택에 대한 새로운 통찰력을 제공하고 향후 연구 방향을 제시합니다. ICL 또는 IFT를 선택하려면 특정 상황에 따라 장단점을 비교해야 하며 고품질 데이터가 항상 핵심입니다. 우리는 이 연구가 모든 사람이 대규모 언어 모델을 더 잘 이해하고 적용하는 데 도움이 되기를 바랍니다.