Downcodes의 편집자는 베이징 Zhiyuan 인공 지능 연구소가 여러 대학과 협력하여 Video-XL이라는 초장기 비디오 이해를 위한 대형 모델을 출시했다는 사실을 알게 되었습니다. 이 모델은 10분 이상의 긴 비디오를 처리하는 데 탁월한 성능을 발휘하여 여러 벤치마크에서 선두 위치를 차지하고 강력한 일반화 기능과 처리 효율성을 보여줍니다. Video-XL은 언어 모델을 사용하여 긴 시각적 시퀀스를 압축하고 "건초 더미에서 바늘 찾기"와 같은 작업에서 거의 95%의 정확도를 달성합니다. 2048 프레임의 입력을 처리하려면 80G의 비디오 메모리가 있는 그래픽 카드만 있으면 됩니다. 이 모델의 오픈 소스는 글로벌 다중 모드 비디오 이해 연구 커뮤니티의 협력과 발전을 촉진할 것입니다.
베이징 지위안(Beijing Zhiyuan) 인공지능 연구소는 상하이교통대학교, 중국 인민대학교, 북경대학교, 베이징 우편통신대학교 등 대학과 협력하여 Video-XL이라는 대형 초장거리 영상 이해 모델을 출시했습니다. 이 모델은 다중 모드 대형 모델의 핵심 기능을 보여주는 중요한 시연이자 일반 인공 지능(AGI)을 향한 핵심 단계입니다. Video-XL은 기존 멀티모달 대형 모델에 비해 10분 이상의 장편 영상 처리 시 더 나은 성능과 효율성을 보여준다.

Video-XL은 언어 모델(LLM)의 기본 기능을 활용하여 긴 시각적 시퀀스를 압축하고, 짧은 비디오를 이해하는 기능을 유지하며, 긴 비디오 이해에서 탁월한 일반화 기능을 보여줍니다. 이 모델은 여러 주류 긴 비디오 이해 벤치마크에서 여러 작업에서 1위를 차지했습니다. Video-XL은 효율성과 성능 사이의 적절한 균형을 달성합니다. 2048 프레임 입력을 처리하고 1시간 길이의 비디오를 샘플링하며 비디오 "건초 더미 속의 바늘" 작업에서 거의 95%를 달성하려면 80G 비디오 메모리가 있는 그래픽 카드만 필요합니다. % 정확성.
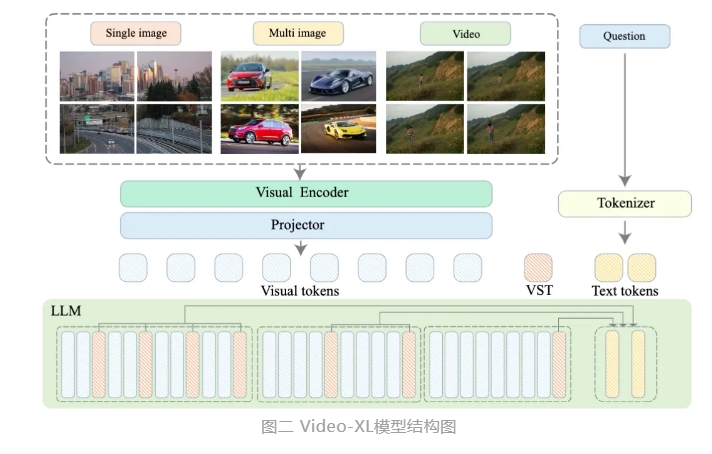
Video-XL은 영화 요약, 영상 이상 탐지, 광고 배치 탐지 등의 응용 시나리오에서 폭넓은 활용 가치를 발휘하고, 장편 영상 이해를 위한 강력한 보조자가 될 것으로 기대된다. 이 모델의 출시는 긴 비디오 이해 기술의 효율성과 정확성에 있어 중요한 단계이며, 향후 긴 비디오 콘텐츠의 자동화된 처리 및 분석을 위한 강력한 기술 지원을 제공합니다.
현재 Video-XL의 모델 코드는 글로벌 다중 모드 영상 이해 연구 커뮤니티의 협력과 기술 공유를 촉진하기 위해 오픈 소스로 공개되었습니다.
논문 제목: Video-XL: 시간 규모 비디오 이해를 위한 초장거리 비전 언어 모델
논문 링크: https://arxiv.org/abs/2409.14485
모델 링크: https://huggingface.co/sy1998/Video_XL
프로젝트 링크: https://github.com/VectorSpaceLab/Video-XL
Video-XL의 오픈 소스는 긴 비디오 이해 분야의 연구 및 응용에 새로운 가능성을 제공합니다. 그 효율성과 정확성은 관련 기술의 추가 개발을 촉진하고 향후 더 많은 응용 시나리오에 대한 기술 지원을 제공할 것입니다. 앞으로 Video-XL을 기반으로 한 더욱 혁신적인 애플리케이션을 볼 수 있기를 기대합니다.