Downcodes의 편집자는 Alibaba Cloud가 음성 상호 작용 분야에서 획기적인 발전을 이룬 새로운 대규모 오디오 언어 모델 Qwen2-Audio를 출시했다는 사실을 알게 되었습니다. 다양한 오디오 신호 입력을 수용하고 오디오 분석을 수행하거나 음성 명령에 직접 응답하여 사용자 경험을 크게 향상시킬 수 있습니다. 이전 Qwen-Audio 모델과 비교하여 Qwen2-Audio는 명령 추적에서 더욱 강력한 성능을 보여주며 여러 벤치마크 테스트에서 선두 위치를 달성했습니다. 이는 인공 지능 분야에서 Alibaba Cloud가 취한 또 다른 확고한 발걸음으로 사용자에게 더욱 발전되고 편리한 음성 상호 작용 기술을 제공합니다.
Alibaba Cloud는 최근 Qwen-Audio라는 대규모 오디오 언어 모델을 출시했습니다. 이 모델은 다양한 오디오 신호 입력을 수용하고 오디오 분석을 수행하거나 음성 명령에 직접 응답할 수 있어 음성 상호 작용 경험을 크게 향상시킵니다.
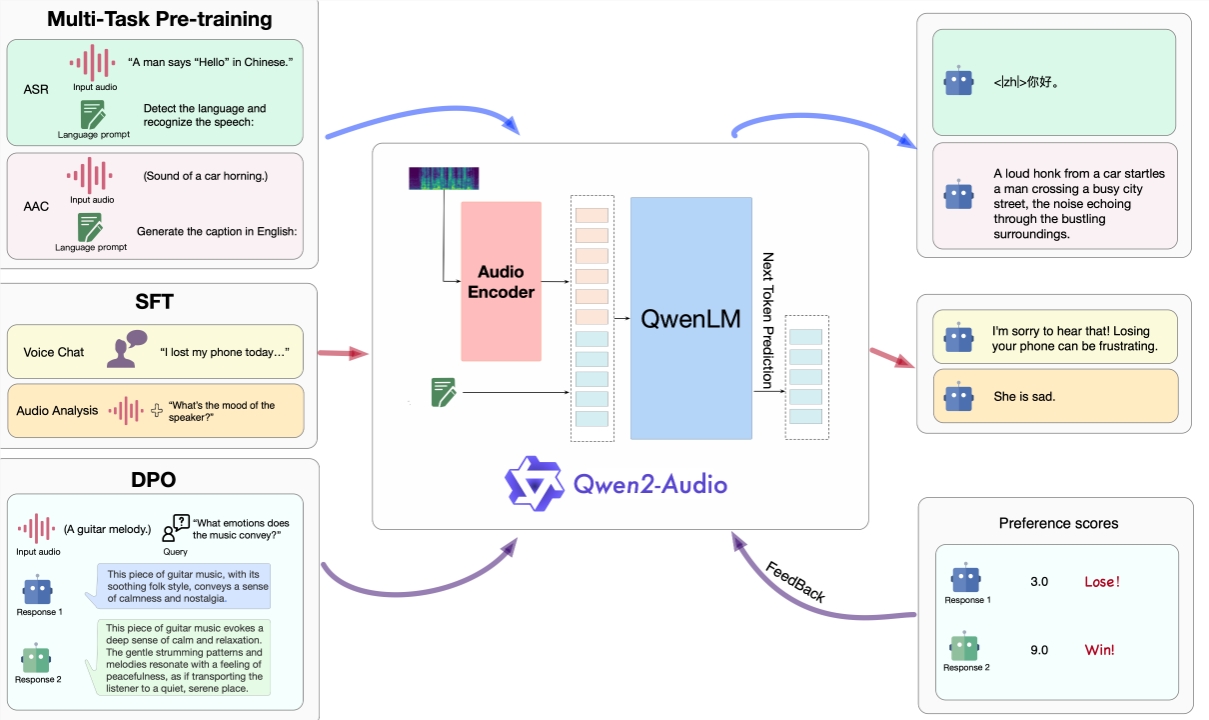
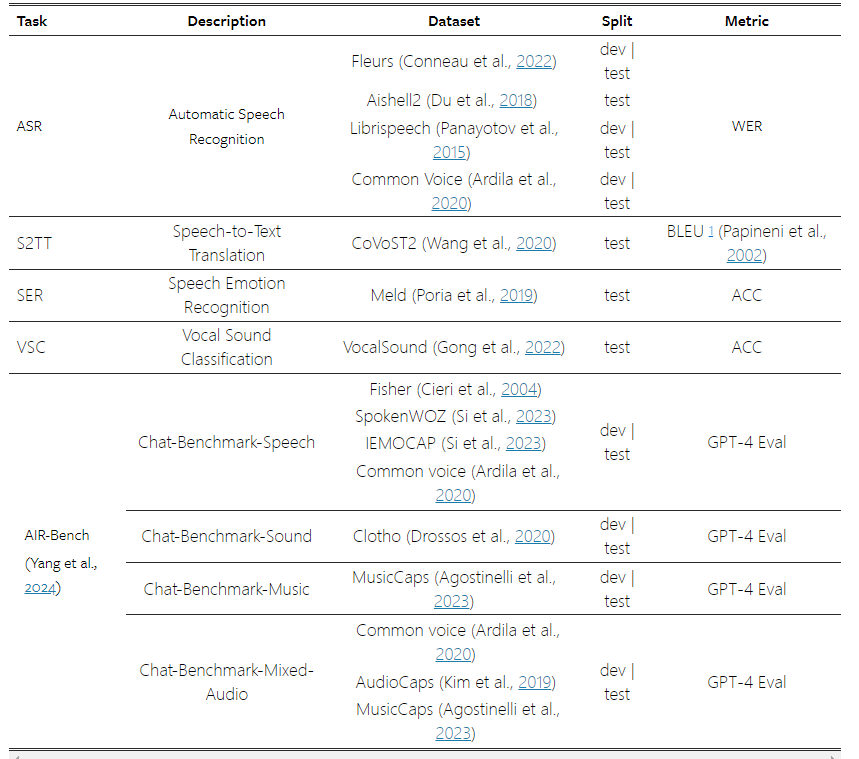
Qwen2-Audio의 채팅 기능 측면에서 연구원들은 AIR-Bench 채팅 벤치마크에서 성능을 측정했습니다(Yang et al., 2024). Qwen2-Audio는 음성, 음성 음악 및 혼합 오디오 전반에 걸쳐 최첨단 성능을 보여주었습니다. (SOTA) 명령 추적 기능. Qwen-Audio에 비해 상당한 개선이 이루어졌으며 다른 LALM보다 훨씬 뛰어난 성능을 보입니다.
가장 밝은 부분:
Alibaba Cloud는 음성 상호 작용 경험을 향상시키는 혁신적인 대규모 주파수 언어 모델인 Qwen2-Audio를 출시합니다.
Qwen2-Audio는 오디오 분석을 위해 다양한 오디오 신호 입력을 수용하거나 음성 명령에 직접 응답하여 음성 상호 작용 기능을 크게 확장할 수 있습니다.
3단계 훈련 과정을 통해 Qwen2-Audio의 모델 구조 훈련 방법과 성능이 완전히 입증되어 사용자에게 더 나은 오디오 상호 작용 경험을 제공합니다.
전체적으로, Qwen2-Audio의 출현은 음성 상호 작용 기술에 새로운 가능성을 가져오고, 강력한 성능과 다양성으로 인해 향후 응용 분야에서 광범위한 전망을 갖게 됩니다. Downcodes의 편집자는 인공 지능 분야에서 Alibaba Cloud의 최신 진행 상황에 계속해서 관심을 기울이고 독자들에게 더욱 흥미로운 보고서를 제공할 것입니다.