최근에는 복합형 대형 모델이 급속히 발전하여 우수한 모델이 많이 등장했습니다. 그러나 대부분의 기존 모델은 훈련 분리로 인한 시각적 유도 편향 문제로 인해 효율성과 성능이 제한되는 시각적 인코더에 의존합니다. Downcodes의 편집자는 Zhiyuan Research Institute가 대학과 협력하여 출시한 새로운 시각적 언어 모델 EVE를 제공합니다. 이는 코더 없는 아키텍처를 채택하고 여러 벤치마크 테스트에서 우수한 결과를 달성하여 다중 모드 모델 개발을 위한 새로운 기회를 제공합니다. .
최근에는 다중 모드 대형 모델의 연구 및 적용에 상당한 진전이 이루어졌습니다. OpenAI, Google, Microsoft 등 외국 기업은 일련의 고급 모델을 출시했으며 Zhipu AI, Step Star 등 국내 기관은 이 분야에서 획기적인 발전을 이루었습니다. 이러한 모델은 일반적으로 시각적 특징을 추출하고 이를 대규모 언어 모델과 결합하기 위해 시각적 인코더에 의존하지만 훈련 분리로 인한 시각적 유도 편향 문제가 있어 다중 모드 대형 모델의 배포 효율성과 성능이 제한됩니다.
이러한 문제를 해결하기 위해 Zhiyuan 연구소는 Dalian University of Technology, Peking University 및 기타 대학과 함께 차세대 코더가 없는 시각적 언어 모델 EVE를 출시했습니다. EVE는 세련된 훈련 전략과 추가적인 시각적 감독을 통해 시각적 언어 표현, 정렬 및 추론을 통합된 순수 디코더 아키텍처에 통합합니다. 공개 데이터를 사용하여 EVE는 여러 시각적 언어 벤치마크에서 우수한 성능을 발휘하여 주류 인코더 기반 다중 모드 방법에 접근하거나 심지어 능가합니다.
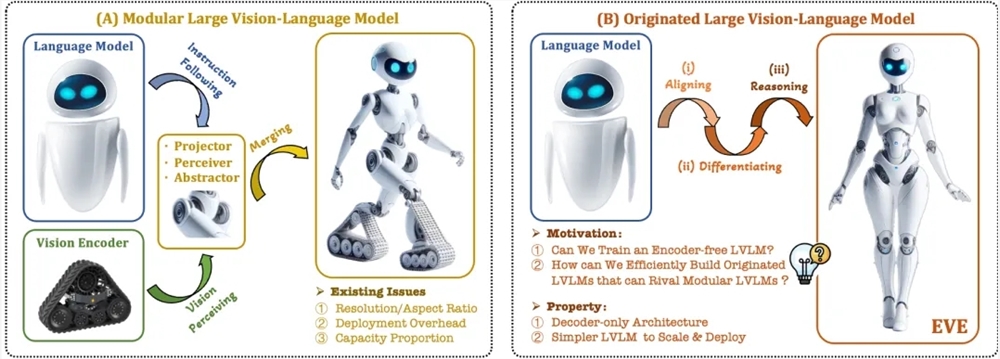
EVE의 주요 기능은 다음과 같습니다.
기본 시각적 언어 모델: 시각적 인코더를 제거하고 모든 이미지 종횡비를 처리합니다. 이는 동일한 유형의 Fuyu-8B 모델보다 훨씬 좋습니다.
낮은 데이터 및 학습 비용: 사전 학습은 OpenImages, SAM, LAION 등의 공개 데이터를 사용하며 학습 시간이 짧습니다.
투명하고 효율적인 탐색: 순수 디코더의 기본 다중 모드 아키텍처를 위한 효율적이고 투명한 개발 경로를 제공합니다.
모델 구조:
Patch Embedding Layer: 단일 컨볼루션 레이어와 평균 풀링 레이어를 통해 이미지의 2D 특징 맵을 얻어 로컬 특징과 전역 정보를 향상시킵니다.
패치 정렬 레이어: 다중 레이어 네트워크 시각적 기능을 통합하여 시각적 인코더 출력과 세밀한 정렬을 달성합니다.
훈련 전략:
대규모 언어 모델에 의해 안내되는 사전 훈련 단계: 시각과 언어 간의 초기 연결 설정.
생성적 사전 훈련 단계: 시각적 언어 콘텐츠를 이해하는 모델의 능력을 향상시킵니다.
감독된 미세 조정 단계: 언어 지침을 따르고 대화 패턴을 학습하는 모델의 능력을 규제합니다.
정량적 분석: EVE는 여러 시각적 언어 벤치마크에서 우수한 성능을 발휘하며 다양한 주류 인코더 기반 시각적 언어 모델과 유사합니다. 특정 지침에 정확하게 응답하는 데 어려움이 있음에도 불구하고 효율적인 교육 전략을 통해 EVE는 인코더 기반의 시각적 언어 모델과 유사한 성능을 달성합니다.
EVE는 앞으로도 인코더 없는 기본 시각적 언어 모델의 잠재력을 입증했으며, 향후 성능 개선, 인코더 없는 아키텍처 최적화 및 기본 다중 모드 구축을 통해 다중 모드 모델 개발을 계속해서 촉진할 수 있습니다. 모델.
논문 주소: https://arxiv.org/abs/2406.11832
프로젝트 코드: https://github.com/baaivision/EVE
모델 주소: https://huggingface.co/BAAI/EVE-7B-HD-v1.0
전체적으로 EVE 모델의 등장은 멀티모달 대형 모델 개발에 새로운 방향과 가능성을 제시하고 있으며, 그 효율적인 훈련 전략과 뛰어난 성능은 주목할 만하다. 우리는 미래의 EVE 모델이 더 많은 분야에서 강력한 역량을 발휘할 수 있기를 기대합니다.