실시간 음성 통신에서 의미와 운율에 영향을 주지 않고 화자의 음색을 변경하는 것은 항상 기술적인 문제였습니다. Downcodes의 편집자는 오늘 음성 내용과 리듬을 유지하면서 실시간으로 화자의 음성 음색을 변경할 수 있는 획기적인 기술인 StreamVC를 소개할 예정입니다. 이는 모바일 플랫폼에 적합하며 실시간 통신 및 음성 익명화를 제공합니다. StreamVC의 낮은 대기 시간, 고품질 음성 합성 및 피치 안정성은 실시간 통신 분야에서 상당한 이점을 제공합니다.
전화 통화든 화상 회의든 실시간 커뮤니케이션의 세계에서 소리는 우리가 자신을 표현하는 중요한 도구입니다. 그러나 언어의 내용과 리듬에 영향을 주지 않고 실시간으로 화자의 목소리 음색을 변경할 수 있다면 어떤 일이 일어날지 생각해 본 적이 있습니까? StreamVC 기술의 출현으로 이것이 가능해졌습니다.
StreamVC는 소스 음성의 내용과 운율을 유지하면서 대상 음성의 음색을 일치시키는 혁신적인 음성 변환 솔루션입니다. 기존 방법과 달리 StreamVC는 모바일 플랫폼에서도 입력 신호에 대한 대기 시간이 짧은 결과 파형을 생성하므로 전화 통화 및 화상 회의와 같은 실시간 통신 시나리오는 물론 이러한 시나리오의 음성 익명화에 적합합니다.
기술적인 하이라이트:
실시간: StreamVC는 모바일 장치에서 70.8밀리초의 짧은 지연 시간 추론이 가능합니다.
고품질 음성 합성: SoundStream 신경 오디오 코덱의 아키텍처 및 훈련 전략을 활용하여 경량의 고품질 음성 합성을 달성합니다.
피치 안정성: 화이트닝된 기본 주파수(f0) 정보를 도입하여 소스 스피커의 음색 정보를 유출하지 않고 피치 일관성이 향상됩니다.
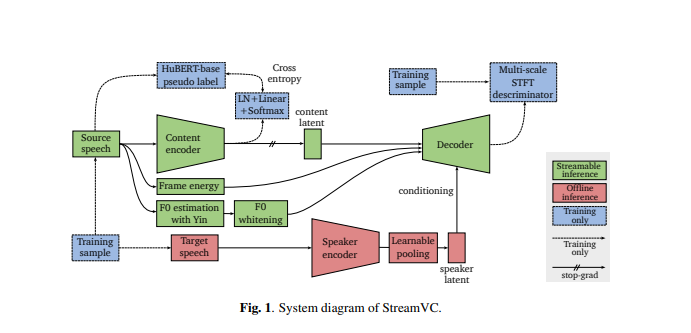
StreamVC의 디자인은 Soft-VC 및 SoundStream에서 영감을 받았습니다. HuBERT 모델에 의해 추출된 개별 음성 단위를 콘텐츠 인코더 네트워크의 예측 대상으로 사용합니다. 콘텐츠 인코더 및 디코더 아키텍처와 교육 전략은 고품질 인과 오디오 합성을 달성하기 위해 SoundStream 신경 오디오 코덱에서 설계되었습니다.
StreamVC는 자연성, 이해성, 화자 유사성, 음조 일관성 등 여러 벤치마크를 통해 기존 기술과 비교되었습니다. 실험 결과에 따르면 StreamVC는 소스 언어의 피치를 잘 보존하고 화자 유사성 측면에서 미세 조정 모델과 비교할 수 있는 것으로 나타났습니다.
StreamVC는 모바일 장치에서 대기 시간이 짧은 효율적인 사운드 변환이 전적으로 가능하다는 것을 증명합니다. HuBERT에서 파생된 소프트 음성 단위는 스트리밍 가능한 인과 컨벌루션 신경망 아키텍처를 통해 학습할 수 있으며, 고품질 출력을 제공하려면 백색화된 f0 정보를 디코더에 주입하는 것이 중요합니다.
논문 주소: https://arxiv.org/pdf/2401.03078
StreamVC 기술의 출현은 실시간 음성 통신에 대한 새로운 가능성을 가져왔습니다. 짧은 대기 시간, 고품질 음성 변환 기능은 더 많은 분야에서 음성 기술의 적용을 촉진할 것입니다. 앞으로 StreamVC는 음성 익명화, 음성 특수 효과 등에서 더 큰 역할을 할 것이라고 믿습니다. StreamVC를 기반으로 한 더욱 혁신적인 애플리케이션을 기대합니다!