OpenAI의 신비한 '딸기' 프로젝트가 드디어 공개되었습니다! 이전에 Q*라는 코드명으로 명명된 프로젝트가 이제 "Strawberry"라는 이름으로 다시 나타났습니다. 그 강력한 기능은 놀랍습니다. AI는 독립적으로 작업을 계획하고, 온라인으로 정보를 검색하고, 심층적인 연구도 수행할 수 있습니다! 머스크조차도 이를 비웃었는데, 이는 엄청난 영향력을 보여준다. Downcodes의 편집자는 이 인상적인 프로젝트에 대해 자세히 알아보고 그것이 어떤 마법을 가지고 있는지 알아보도록 안내할 것입니다.
최근 OpenAI는 '스트로베리' 프로젝트의 미스터리를 조용히 공개했습니다. 이전에 Q*로 알려져 있었고 현재는 Strawberry로 재런칭된 이 프로젝트는 AI가 작업을 미리 계획하고 온라인에서 자율적으로 정보를 수집하며 심층적인 연구까지 수행할 수 있게 한다고 합니다.
기술계의 거물인 머스크도 이에 동참하지 않을 수 없었다. 그는 댓글에서 “원래 AI의 종말이 종이클립 재앙이 될 줄 알았는데 이제는 끝없는 딸기가 될 것 같다”고 농담했다. 전지."
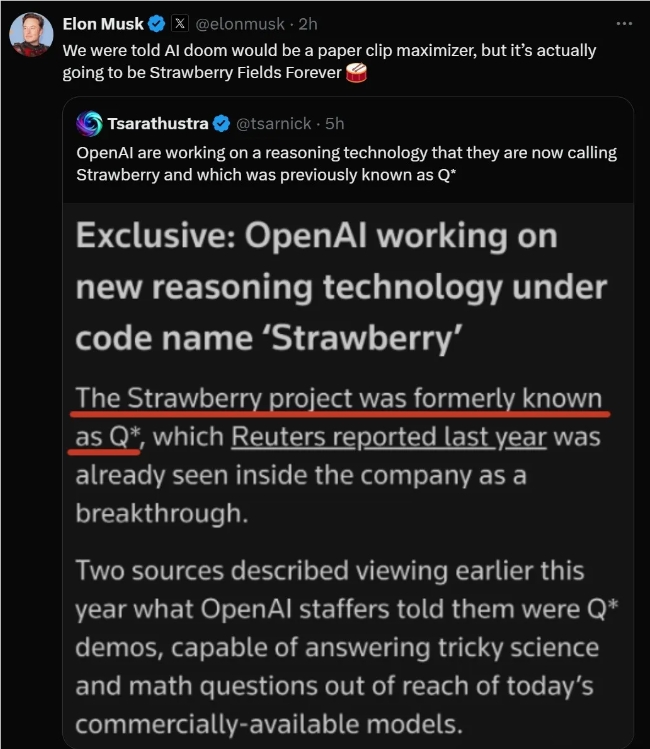
프로젝트 스트로베리에 대한 외부 세계의 호기심에도 불구하고 OpenAI는 운영 세부 사항에 대해 입을 다물었습니다. 본 프로젝트의 개발 과정은 회사 내에서 극비로 공개되기 때문에 출시 시기조차 미스터리가 되었습니다.
최근 내부 회의에서 OpenAI는 인간만큼 강력한 추론 능력을 갖춘 프로젝트 스트로베리(Project Strawberry)의 데모 버전을 선보였습니다. 이는 최근 발표된 AGI 로드맵과 일치하여 OpenAI가 더 큰 움직임을 보이고 있는지 궁금해합니다.
딸기 모델의 설계 컨셉은 AI가 질의 응답을 생성할 뿐만 아니라 사전 계획을 세우고 자율적이고 안정적으로 인터넷을 검색하며 이른바 '심층 연구'를 수행할 수 있도록 하는 것입니다. 현재 이 기능은 AI 분야 최초다.
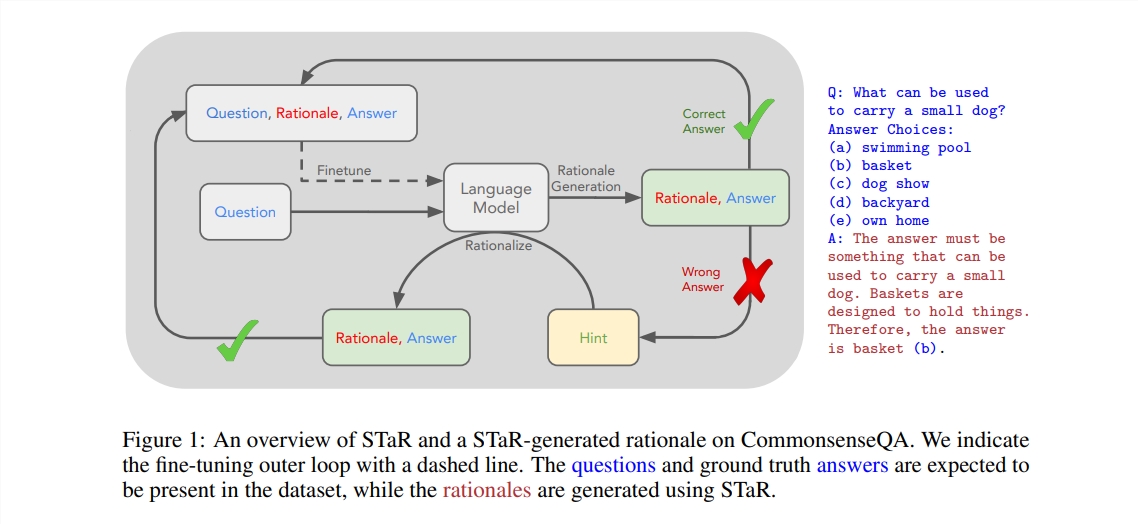
이 문제에 정통한 사람들은 OpenAI의 딸기 프로젝트가 스탠포드 대학에서 개발한 방법인 "Self-Teaching Reasoner(줄여서 STaR)"와 다소 유사하다고 말했습니다. STaR은 훈련 데이터를 반복적으로 생성하여 자기 개선을 달성합니다.
논문 주소: https://arxiv.org/pdf/2203.14465
현재 AI가 추론 프로세스를 생성하도록 하는 방법은 비용이 많이 들거나 정확도가 희생됩니다. 하지만 STaR 기술을 사용하면 소수의 추론 사례와 대량의 비추론 데이터를 반복적으로 사용하여 AI가 스스로 개선할 수 있습니다.
STaR 기술의 워크플로우는 다음과 같습니다. 첫째, AI는 많은 질문에 답하려고 시도하고 추론 프로세스를 생성합니다. 답이 틀리면 정답을 알고 추론을 재생성하십시오. 그런 다음 궁극적으로 정답으로 이어지는 모든 추론을 미세 조정하고 프로세스를 반복하십시오.
OpenAI는 Strawberry의 혁신이 AI 모델의 추론 능력을 크게 향상시킬 수 있기를 바라고 있습니다. 여기에는 특별한 처리 방법이 포함됩니다. AI 모델이 대량의 데이터로 사전 훈련된 후 성능을 최적화하도록 조정됩니다.
OpenAI는 또한 Strawberry가 모델이 일련의 작업을 미리 계획하고 실행해야 하는 장기 작업(LHT)을 수행할 수 있기를 원합니다. 이 목표를 달성하기 위해 그들은 "심층 연구" 데이터세트를 만들고 평가하고 있습니다.
Strawberry Project의 점진적인 발전으로 OpenAI는 AGI 목표 달성에 점점 더 가까워지고 있습니다. 스트로베리의 추론 능력이 정말로 인간과 비슷하다면 AI의 미래는 무한할 것입니다.
OpenAI의 “Strawberry” 프로젝트는 의심할 여지 없이 인공 지능 분야에서 획기적인 발전을 이룬 것이며, 향후 개발에 지속적인 관심을 기울일 가치가 있습니다. 다운코드 편집자는 계속해서 더 많은 기술 정보를 제공할 예정이니 계속 지켜봐 주시기 바랍니다!